Resource Management
Uploading datasets, training models, and running inference servers all pull from the same pool of technical resources. The Resource Management dashboard is a great way to understand, at a glance, what's going on inside of Chariot and take action.
This dashboard can help you shut down non-essential processes for on-prem installations so that high-priority processes can be executed. When installed in the cloud, where scale is practically limitless, this dashboard effectively manages and scales costs.
To access the Resource Manager, click the Profile icon in the top right and then click the Manage Resources link.
The Resource Manager has two parts: the Table of Processes currently using resources and the Compute Totals across Chariot.
Table of Processes
This table displays all the Training Runs, Inference Servers, and Workspaces currently running. Each row contains detailed information regarding its name, entity type, resource allocation, associated project, creating user, creation time, and usage status.
Clicking the ... button to the right of each process will provide a list of available actions for that process, including the option to STOP the chosen entity. The actions available depend on the process's entity type.
Keep in mind that the Resource Manager will only show you projects that you have permission to view—those you are associated with in Chariot.
The checkbox to the left of each process allows you to select multiple processes at once to make bulk changes as needed.
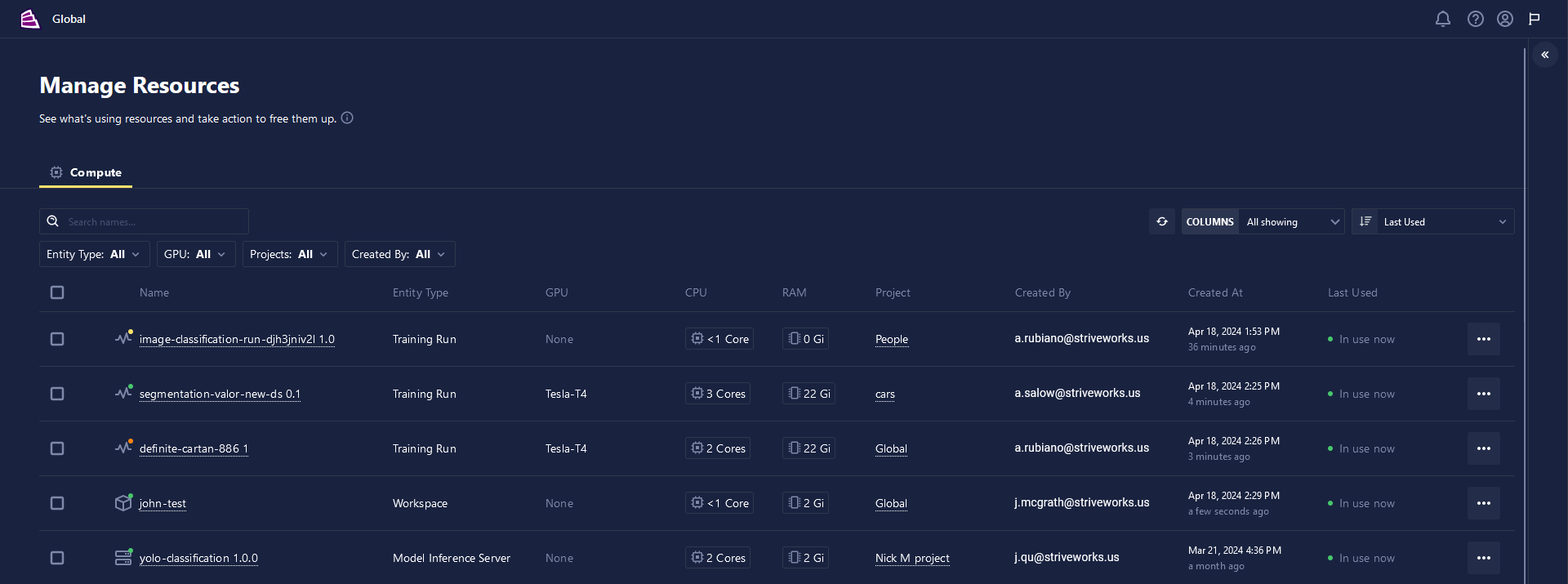
As your list grows with each additional Chariot process, the list may be sorted, filtered, and searched through for the necessary Chariot process, project, or user.
To sort the table, click the SORT drop-down and choose the column you want to sort by. You can also hide columns from the table view by clicking the COLUMNS drop-down and choosing the option that best suits your needs.
To get the most up-to-date information about Chariot resources, click the REFRESH icon above the table. The information displayed in the table will refresh to its current state.
Compute Totals
The Compute Totals drawer displays all of the Kubernetes nodes running in your cluster, showing the number of CPUs, RAM, and GPUs currently in use.
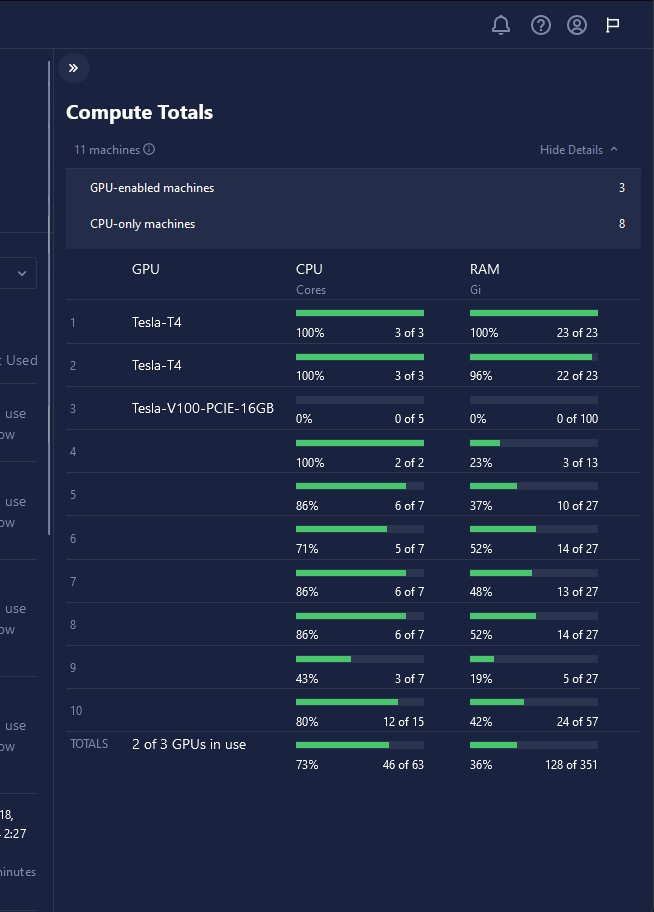
The most crucial information to take from this view is the amount of available resources left in each node. When you create a Training Run, Inference Server, or Workspace, Chariot finds the first node with enough resources to fulfill the request.
Error Message
While processing data in Chariot, you may receive an error, noting that there was insufficient memory to process your request, which is called an out-of-memory error. Optimizing your training settings and parameters for your resource constraints will take time and experimentation for even the most seasoned data scientists and machine learning practitioners.
If your Training Run fails, you will receive a notification. Logs indicating the error can be found in the Events tab of your Training Run page.
For out-of-memory errors, two kinds of error messages can occur:
-
"OOMKilled": This error indicates insufficient RAM was assigned for your Training Run. To proceed, clone and retry the Training Run, ensuring you have increased the RAM to the available limits. If it was already set to the maximum available RAM, you may need to decrease your batch size, use a smaller model architecture, or both.
-
"CUDA Out of Memory": This error indicates insufficient memory on the GPU you selected to train the model for the chosen training options. To proceed, decrease your batch size and retry the Training Run. This process of trial and error can be time intensive, but you will typically get the best results if you can maximize your batch size, given your resource constraints.
For further information regarding optimizing resources in Chariot, please read below.
GPU training
As a rule of thumb, you should always train on a GPU when it is available due to the many benefits using a GPU adds to your training process. GPUs enable you to speed up model training and train with larger batch sizes, which can improve model performance. Typically, the larger the batch of data used, the more beneficial it is to the training process as each training step benefits from more information for the model, and this effect is compounded. GPUs are designed to handle multiple tasks simultaneously, making them highly efficient for parallel processing. ML algorithms often involve intensive matrix computations, which can be performed in parallel on GPU cores much faster than a CPU's sequential processing. Additionally, many popular frameworks, such as PyTorch, which Chariot uses, are optimized for GPU training.
Some machine learning models, such as decision trees or K-nearest neighbors, don't process training data in batches, which can be trained well on CPUs. These are not natively supported in Chariot but can be used through user-defined Blueprints.
There are a few factors to consider in the resource wizard when setting up a Training Run:
- GPU Type (VRAM): The memory available on the GPU is called VRAM (Video Random Access Memory). It stores all the model parameters, intermediate computation results, and batches of data during training. As described above, a GPU with more VRAM allows for storing larger models and bigger batches of data.
Typically, the larger the batch of data that you can fit on a GPU, the more beneficial it is to the training process, as each training step benefits from more information for the model, and this effect is compounded. However, estimating how large a batch size you can get away with is tricky because it largely depends on the model architecture you are using and the characteristics of your data.
For example, if your total batch size is greater than the amount of VRAM available (ex., 64 images that are 250MiB each take up greater than 16GB available on a 16GB GPU), then this is a clear case where we know that a batch size of 64 is too large. The input data size alone exceeds the GPU VRAM available, and we have not even accounted for the network architecture and computations yet, yielding a "CUDA Out of Memory". However, when it comes to closer cases, estimating the total size needed for batch size, model parameters, and computations is an art rather than an exact science. Experimentation can be beneficial here.
-
RAM: RAM stores the operating system and other running processes and serves as a buffer for data transfer between CPU and GPU. If you do not have enough assigned RAM, this will yield "OOMKilled" errors. Even when training using a GPU, it is essential to allocate sufficient RAM, which will vary based on network architecture.
-
CPU Cores: While GPU training offloads most of the heavy computational tasks from the CPU to the GPU, the CPU still manages data loading, preprocessing, and coordinating the training process. More CPU cores can accelerate these tasks, especially when dealing with large datasets.
-
Ephemeral disk storage: This storage serves as secondary storage for datasets, checkpoints, and temporary files, with constraints on capacity and speed. The entire batch of data and the model architecture do not need to be stored simultaneously on ephemeral disk during training. Instead, datasets are typically stored on disk, and batches are loaded into RAM as needed. However, model checkpoints and temporary files may be periodically saved to disk to track training progress and enable resuming training from a specific point. Assigning more ephemeral disk storage will usually help with your training speed.
Non-GPU training
Without a GPU, the system relies on the computer's RAM to store model parameters, data batches, and computations. While VRAM offers faster processing speeds for large datasets and complex models, relying solely on RAM can limit model and batch sizes due to memory constraints. RAM is the primary resource for storing the model architecture, data, and computations during training. If you cannot use a GPU for model training, you may need to use smaller architectures and batch sizes to execute a successful Training Run.