Chariot Release Notes
0.26.0 - June 25, 2026
What's New
- Inference Engine Library:
- Chariot now provides a fuller UI experience for managing Inference Engines, which define how models are deployed and served. You can search and sort engines, review engine documentation and readiness details, configure environment variable schemas, and manage engine settings directly in the UI.
- As part of this release, legacy models will be migrated to Inference Engines. Users no longer need to select a model framework or artifact type during upload; Chariot now uses Inference Engines and Supported Inference Engines to determine how models can be served.
What's Improved
- You can now view text datum metadata when previewing text datums.
- Dataset lists are now defaulted to the most recently updated dataset first. You can still sort and filter as desired.
- Token metrics are now reported for models served through the OpenAI proxy engine.
- Model upload workflows can now prepopulate names and other metadata when uploading models exported from Chariot or models that include Chariot metadata.
- The version of Transformers used to serve Hugging Face models has been updated to support new models such as
gemma4_unified.
What's Fixed
- Fixed an issue where bounding boxes could be edited beyond image bounds. Now bounding boxes and segmentations must be completely within image boundaries. The center point of oriented bounding boxes must be within image boundaries.
- Fixed improper pagination of the dataset selector in the Training Wizard.
- Fixed Annotation Task behavior to block starting tasks for deleted datasets.
- Fixed responsiveness of the crosshair tool when annotating imagery with bounding boxes.
0.25.4 - June 8, 2026
What's New
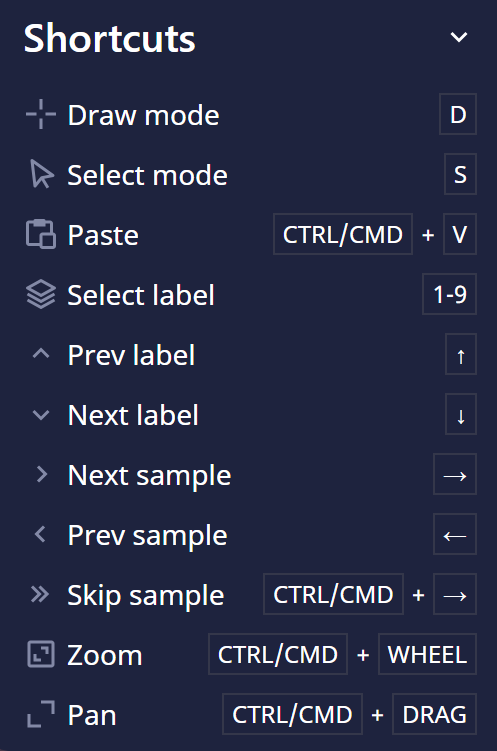
- Added keyboard shortcuts for next, previous, and skip sample in the Annotation Editor, making annotation navigation faster without leaving the keyboard.
What's Fixed
- Fixed a bug in caching for dataset uploads, significantly decreasing upload times.
0.25.3 - May 22, 2026
What's New
- Datasets API now supports sorting datasets by storage size. UI support is coming soon.
What's Improved
- Models using the Azure OpenAI inference engine now report token metrics.
- Improved dataset and dataset view list page performance and usability.
- Reduced health endpoint log spam in inference server logs.
What's Fixed
- Fixed an issue where the SDK
infer()method could wait indefinitely when called on a model without an active inference service. - Fixed an issue affecting model comparison.
- Fixed handling of annotation tasks after the underlying dataset has been deleted.
Deprecation Warnings
- Removed RStudio as a standard workspace application.
0.25.2 - May 8, 2026
What's Fixed
- Fixed a model upload exception path to prevent upload failures from surfacing as unhandled errors.
- Fixed an inference display issue where large image previews could appear cut off.
- Fixed scrolling while editing in Model Card Template view.
- Fixed a draw-overlap issue that blocked starting a new box over existing annotations when annotating object detection data.
0.25.1 - April 24, 2026
What's Improved
- Added an automatic restart for Training Runs to improve resiliency for lengthy runs that may be interrupted by infrastructure rotation.
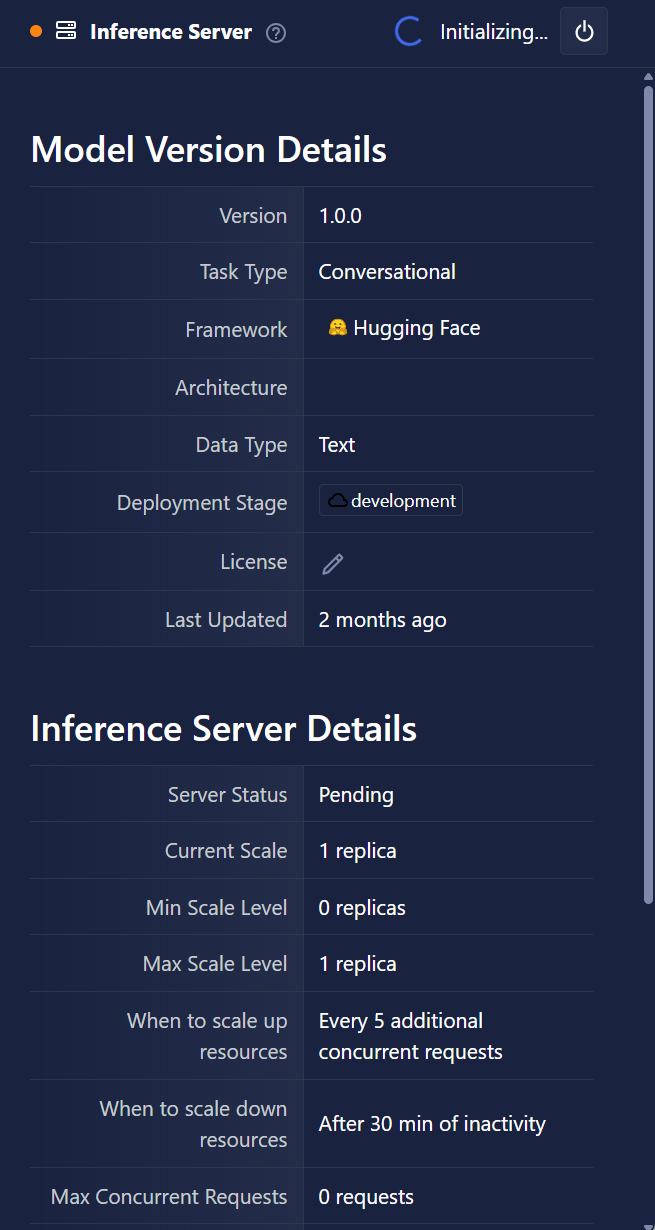
- Improved the display for Inference Server configuration by exposing custom engine fields and showing the server state.
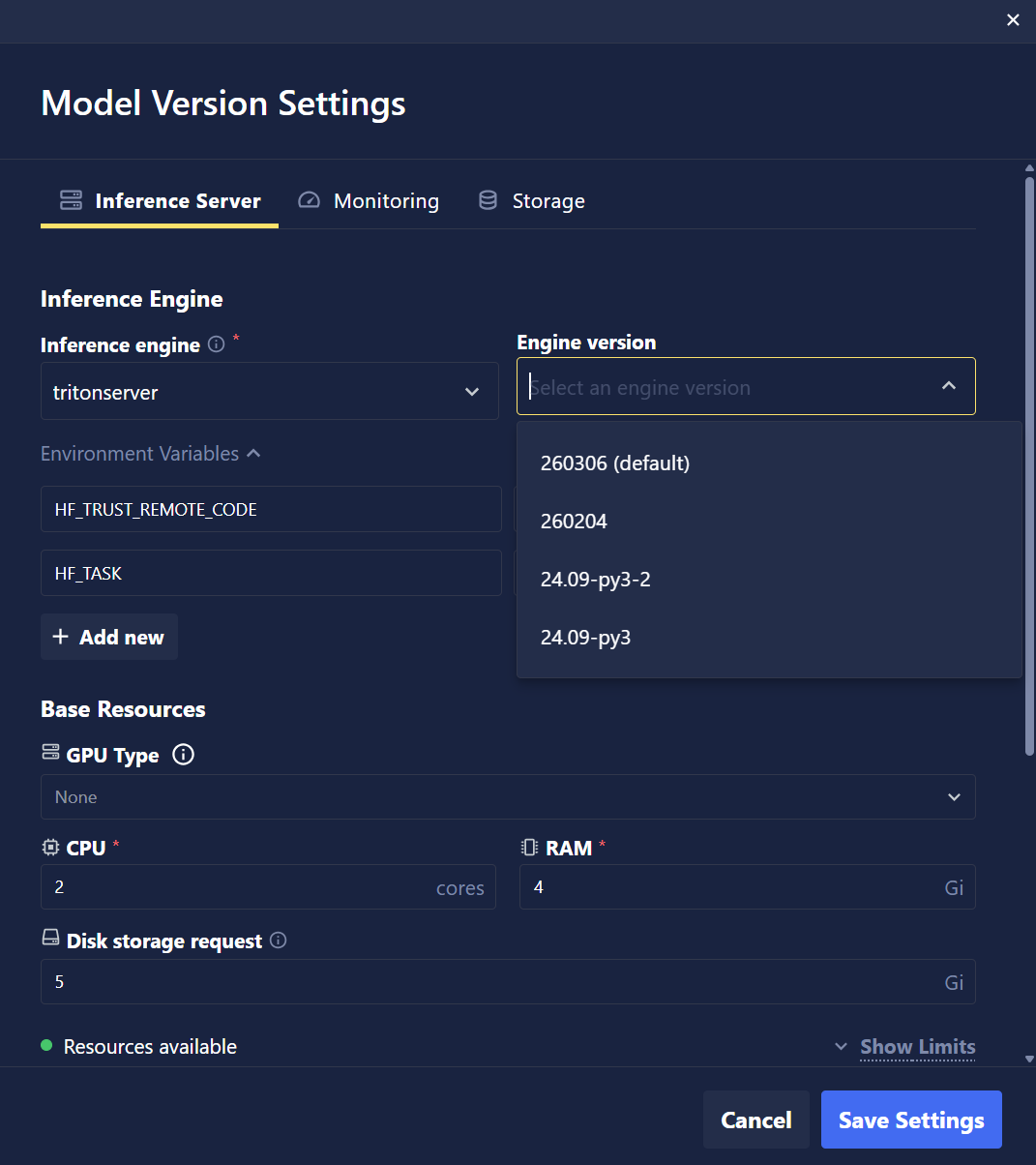
- Added custom Inference Engine version and Environment Variables options in Model Version Settings.
What's Fixed
- Workspaces are now less likely to get stuck in a “Pending” state due to improved scheduling logic that better aligns GPU requirements with disk locations.
- Fixed dataset upload workflow behavior so that selected files are not incorrectly cleared when the upload type changes.
0.25.0 - April 3, 2026
What's New
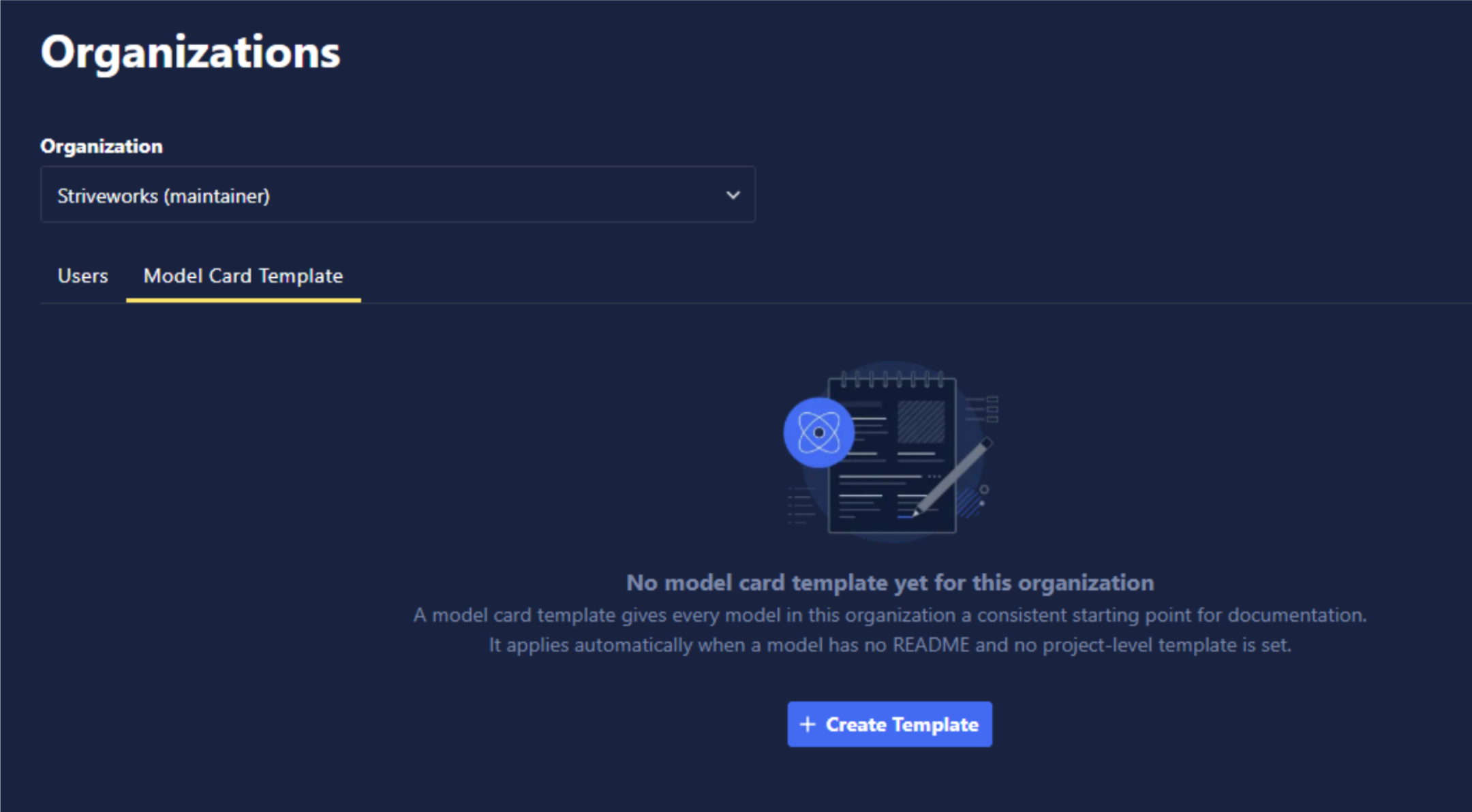
- Model Card Templates: A model card template is a templatized README that gives every model in an organization or project a consistent starting point for documentation. It applies automatically when a model has no README. Templates can be configured at organization or project level. Project level templates will override organization level templates.
- vLLM Token Metrics: Added support for token-level metrics for vLLM-hosted models, enabling better visibility into model usage and performance.
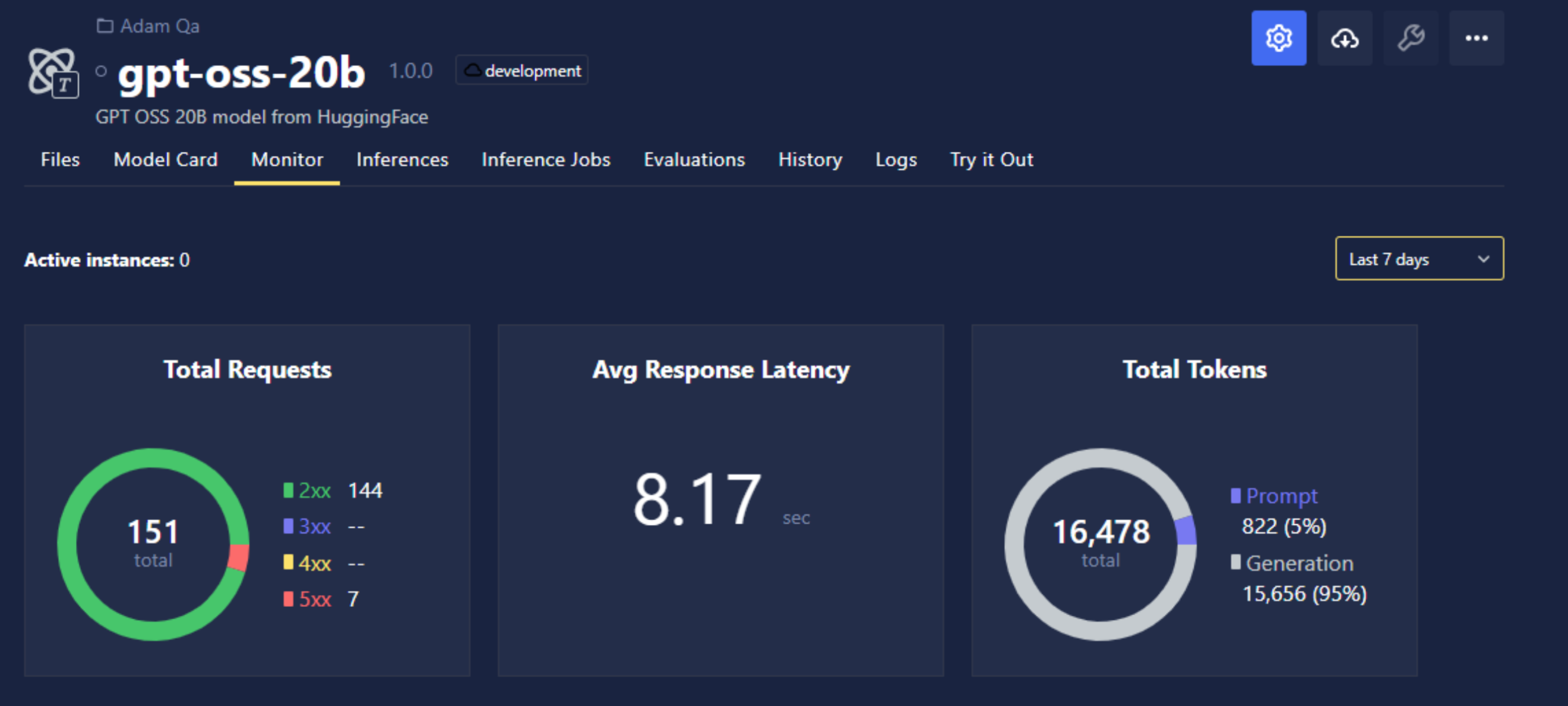
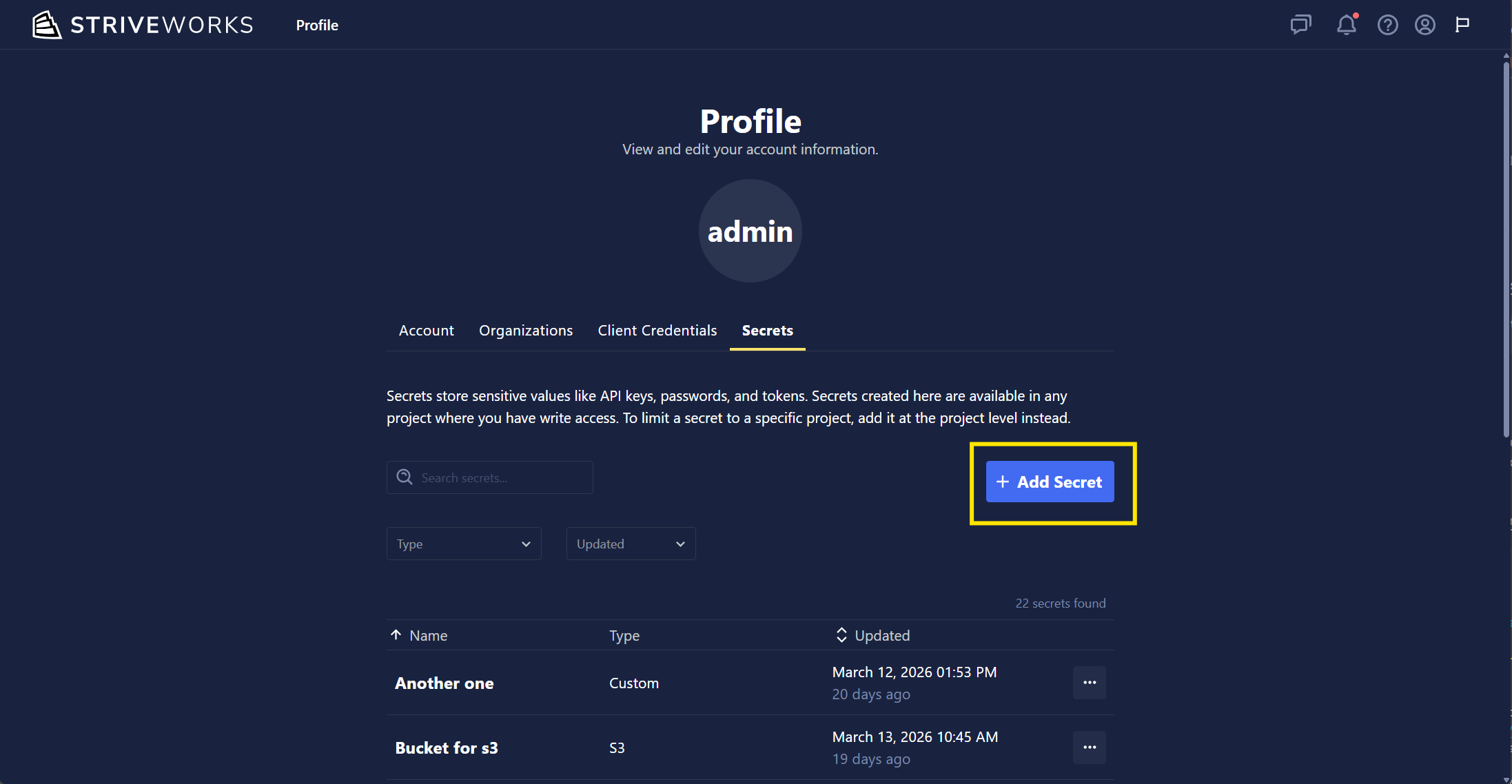
- User-Scoped Secrets Management: Users can now fully manage personnel secrets under Profile → Secrets.
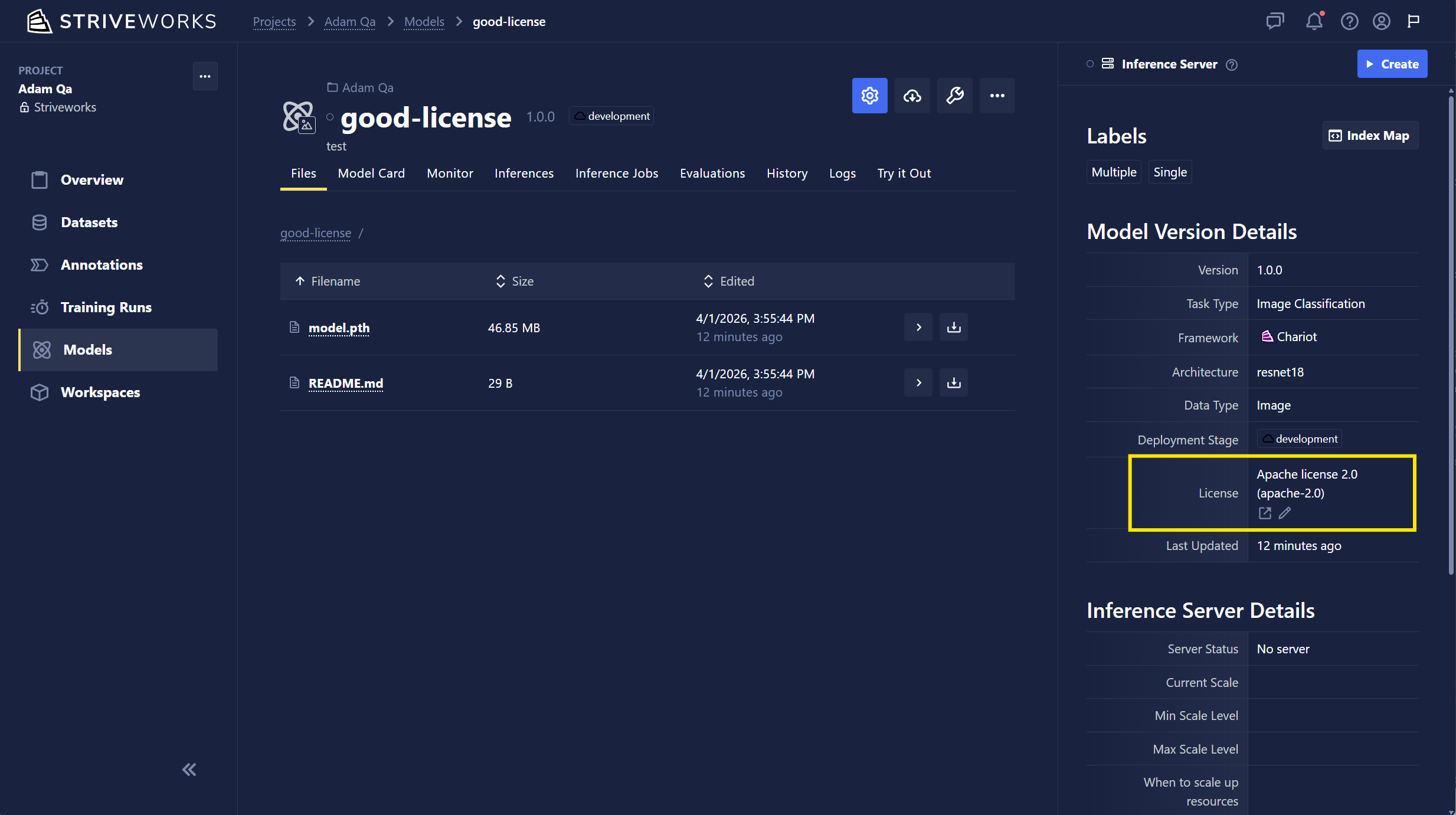
- Model License Data: Users can now view license details directly under Model Version Details and can filter Model page by license.
What's Improved
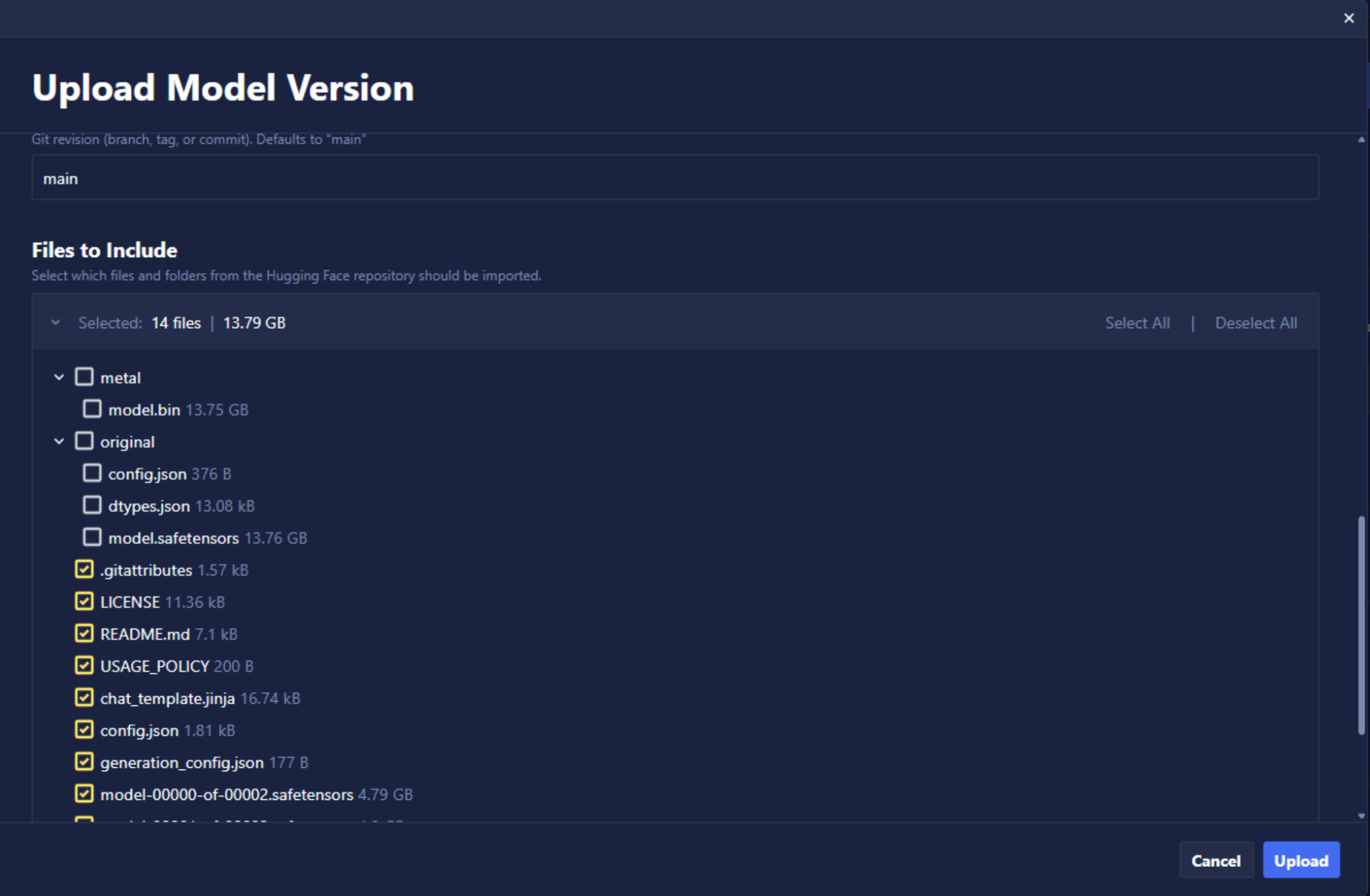
- Hugging Face Import File Selection: Importing models from Hugging Face now includes a file tree view enabling users to preview repository contents before import and selectively include or exclude files.
- Object Detection Crosshair Tool: Added crosshair visual aid to improve annotation precision.

- Improved model upload experience:
- Eliminated duplicate error notifications.
- Added clearer fail-fast behavior.
- Improved reliability of long-running training runs when encountering intermittent connection issues to storage.
What's Fixed
- Fixed an issue where Hugging Face model revisions were ignored during import via UI and SDK, causing main to always be the revision imported.
- Fixed issue of inference server initializing message disappearing from Try-it-Out page while waiting for Inference Serve to initialize.
- Fixed dataset upload status & count mismatches so upload totals and states are consistent.
- Fixed a Swagger documentation bug which prevented inspection of Upload API endpoint details.
- Fixed inconsistency issue between the unannotated filter and resulting displayed datums.
0.24.4 - March 11, 2026
What's Fixed
- This release consisted mainly of minor enhancements and bug fixes.
0.24.3 - March 7, 2026
What's New
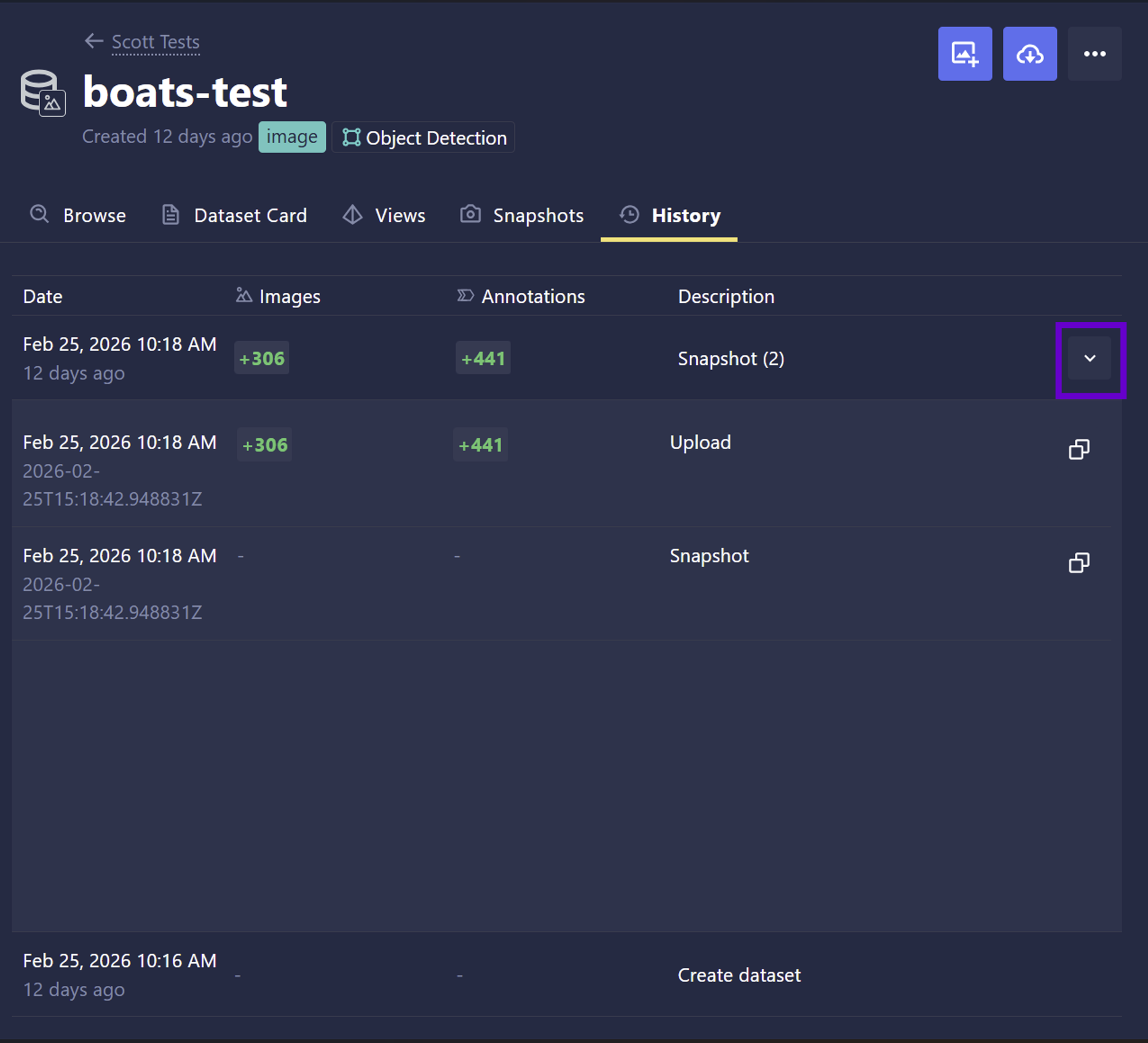
- Enhanced Dataset History Controls: Users can now expand history events that contain grouped sub-events. This feature includes a new Copy Timestamp button for child events and supports infinite scrolling for seamless navigation through large event logs.
What's Improved
- Added support in the SDK to send batch inputs for text embedding.
- Significantly reduced load times when viewing individual datasets or datums.
- Improved automated scaling for various dataset jobs such as uploads.
What's Fixed
- Fixed an issue where edited training notes would temporarily disappear or “depopulate” immediately after saving. The UI now correctly retains and displays the updated notes.
- Fixed an issue with drift detection failing when a baseline in-distribution dataset is small.
- Fixed an issue where bounding box annotations over the edges of images were not being properly clipped during the training pre-processing.
- Fixed an issue where verifying or editing an annotation during an Annotation Review Task would cause the bounding box to disappear from the screen. Annotations now remain visible even after their status changes so that users don’t lose track of work while navigating through a task.
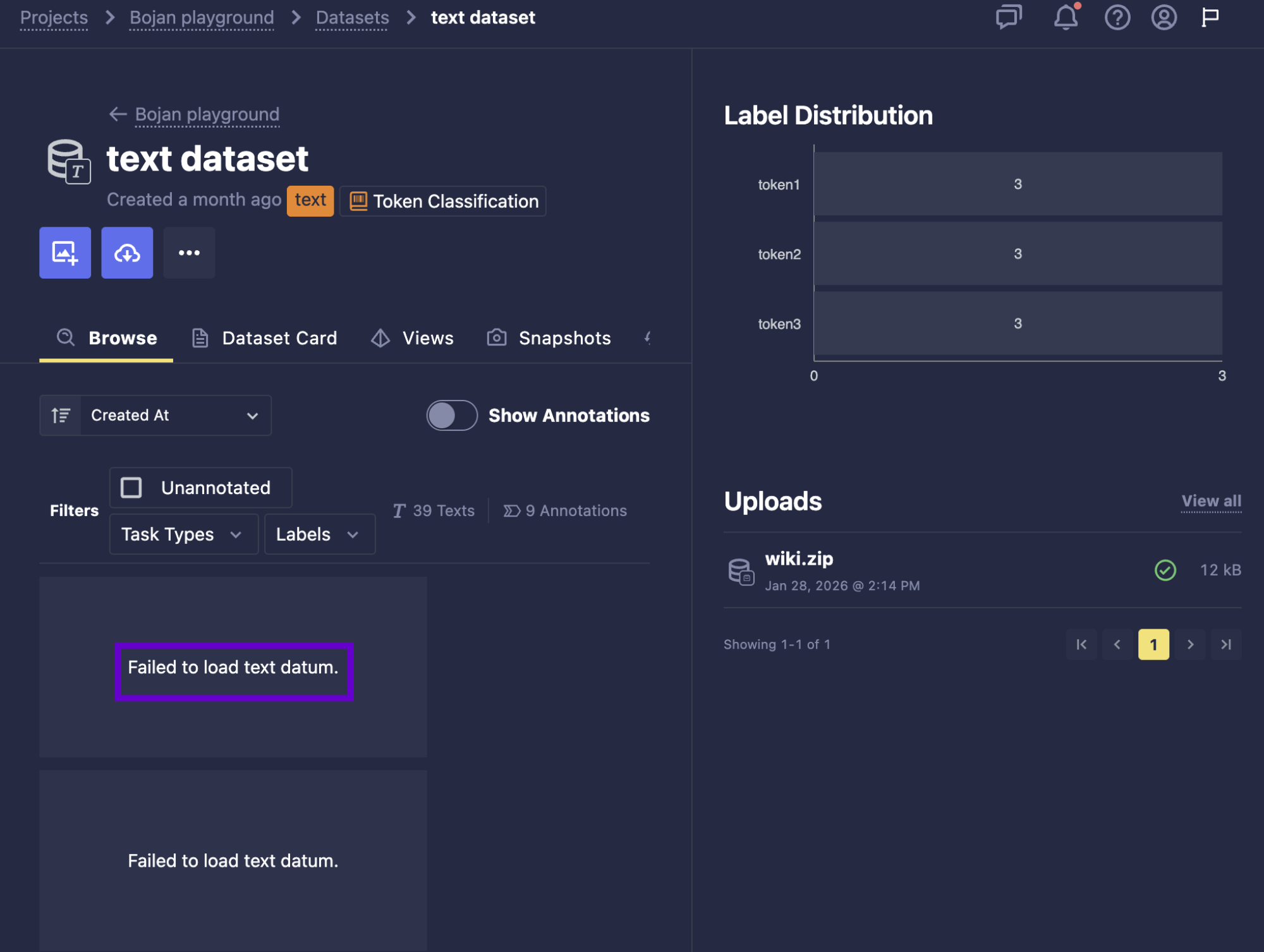
- Fixed an issue where text datums would show raw HTML status codes if there was failure in retrieving text datums. Users will now see “Failed to load text datum,” consistent with error handling for images.
0.24.2 - February 28, 2026
What's Fixed
- Resolved lag during sign-in and sign-out.
- Fixed issue where the Annotation Details and Image Details panels interfered with drawing annotations.
- Fixed package version incompatibility in Chariot Workspaces with chariot-client 0.24.1.
- Fixed multiple instances of UI crashes.
- Fixed issue where custom Blueprint run configurations did not allow the selection of multiple GPUs even when support_multi_gpu was set to true.
- Fixed issue where Training Run duration could display as negative in certain edge cases.
- Fixed issue where secret values were replaced with ******** when the secret name was changed in the Chariot UI.
0.24.1 - February 17, 2026
What's New
- Enhanced Datum Visualization Controls
- Users can now adjust the following image settings directly while viewing and annotating datums:
- Contrast
- Brightness
- Saturation
- Inversion
- Users can now adjust the following image settings directly while viewing and annotating datums:

What's Improved
- Improved Model File Directory View
- The list of files associated with a model is no longer paginated. Users can now view the entire directory tree on a single page, making it easier to navigate and inspect model contents.
What's Fixed
- Fixed an issue where text datums containing HTML were rendered as HTML instead of being safely escaped.
- Fixed an issue preventing custom Inference Engines from pulling container images from private repositories.
- Fixed an issue with class labels of detections being cut off when using the try-it-out feature.
- Fixed an issue causing the training metrics page to crash when metrics contained null values.
0.24.0 - February 6, 2026
What's New
- Multi-GPU Workloads
- Chariot now supports training and serving models using multiple GPUs on a single compute node. This enables higher throughput training and improved inference performance for larger or more demanding models.
- Model Monitoring Enhancements
- We’ve redesigned the model-monitoring experience to provide deeper visibility and longer-term observability:
- Metrics retention increased to 60 days, with data persisting even after models scale down
- Custom time-range queries for historical analysis (previously limited to the last minute)
- New system and inference metrics, including: GPU utilization VRAM usage Concurrent requests Requests in queue
- Metric export to CSV, making it easier to analyze or share performance data outside of Chariot
- We’ve redesigned the model-monitoring experience to provide deeper visibility and longer-term observability:
What's Improved
- Improved rendering of the Training Run list when many Snapshots are associated with a run.
- Improved performance and rendering of dataset previews with large numbers of annotations.
- Improved error messaging during Snapshot creation to clearly indicate when a View has no applicable data.
- Improved performance when retrieving Snapshot datums.
What's Fixed
- Fixed an issue where the classification banner did not appear on the Manage Resources page.
- Fixed search behavior where certain characters (such as hyphens) were not handled correctly.
- Fixed an issue where the annotation toggle state was not preserved when navigating away from and back to a page.
- Fixed an issue where model files were incorrectly interpreted as directories.
0.23.5 - January 16, 2026
What's New
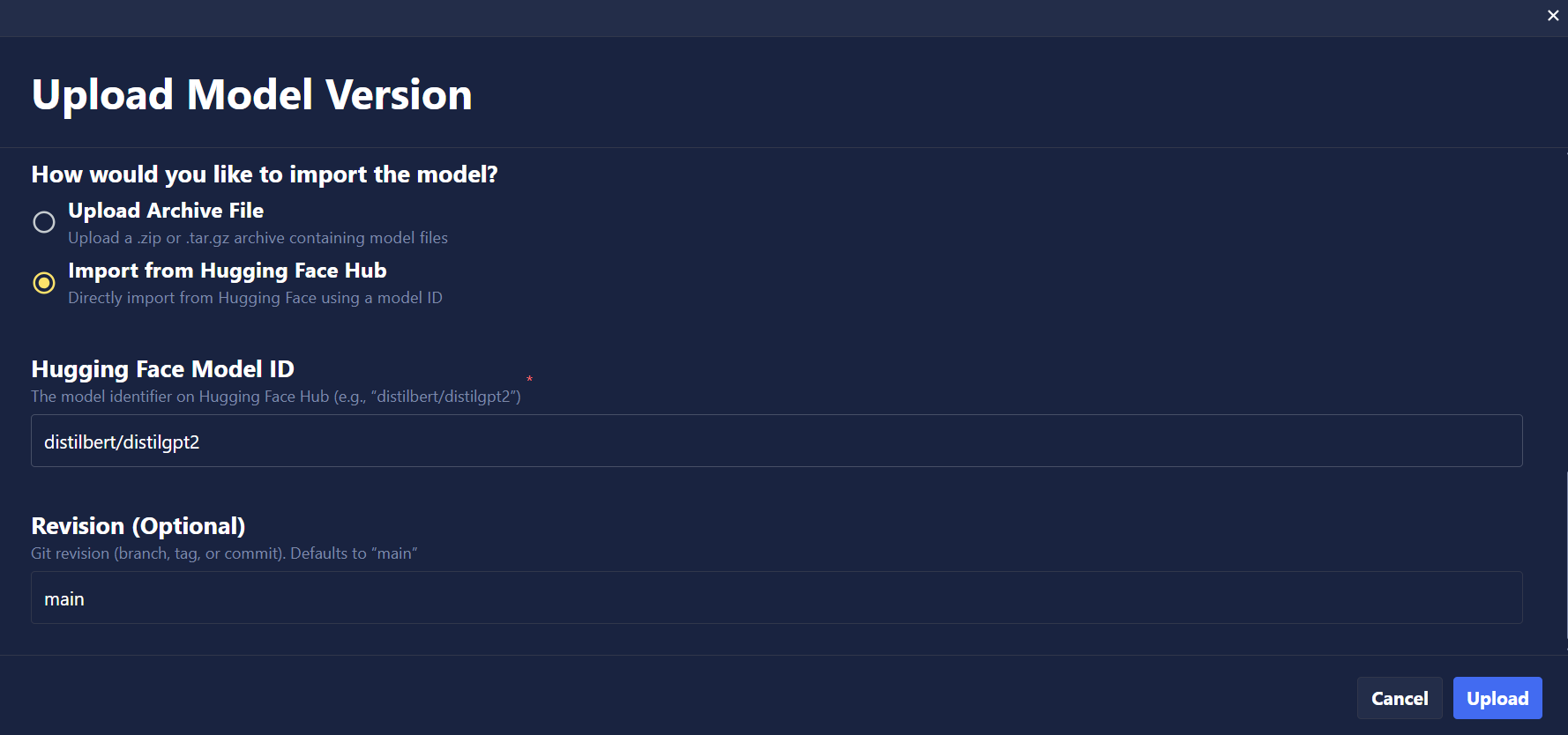
- Direct Import of Models From Hugging Face Hub
- Import models directly from Hugging Face Hub by simply providing the Hugging Face model ID to easily bring your favorite open source models from Hugging Face hub into Chariot.
- Import models directly from Hugging Face Hub by simply providing the Hugging Face model ID to easily bring your favorite open source models from Hugging Face hub into Chariot.
- Expanded Filtering for Datum Annotations
getDatumAnnotationspreviously only returned active annotations for the given datum. It now supports filtering annotations by metadata, approval status, task type, and timestamp.
What's Fixed
- Fixed a UI mapping issue where the raw back-end status Job_submitted was displayed instead of a readable status label.
- Fixed UI layering issues where the classification banner obscured model status text and hover tooltips.
- Fixed issue with help/hover text in the Workspace application setup modal so disk storage guidance references the correct Workspace context.
- Fixed issue with PyTorch models created using MAR (Model Archive) only being able to install files from Armory, so they can now install from PyPI.
- Fixed an issue where using the CTRL hotkey for panning would also draw at the same time during ad hoc annotation.
- Fixed pagination issues on the Inference Store page.
- Fixed a bug preventing Segment Anything annotation hints from working.
0.23.4 - December 20, 2025
What's New
- vLLM Settings Updates
- Several updates were made to expose additional vLLM configuration options in the Chariot UI and to provide clearer guidance when configuring models to run on vLLM.
- Snapshot Review Status Filtering
- You can now filter Snapshot details by Review Status, making it easier to navigate Snapshots based on workflow state.
- Video Tutorials in the User Guide
- Added step-by-step video walkthroughs for model training, model evaluation, and data annotation.
- Simplified Class Label UX
- The “Search” and “Add Label” inputs have been merged into a single field, making it more intuitive to add new labels to datasets or annotation tasks.
What's Fixed
- Fixed an issue where clicking on a model returned from global search redirected users to an empty results page.
- Fixed an issue preventing oriented detections from rendering in the Try-It-Out interface.
- Fixed an issue where annotation task statistics did not update after closing the Annotation Editor.
- Fixed an issue in model evaluation where the image classification ROC AUC metric incorrectly accepted datum filters.
- Fixed an issue where forking a model did not correctly copy supported inference engines.
- Fixed an issue that caused the UI to crash when opening a model’s label index map.
0.23.3 - December 6, 2025
What's New
-
Enhanced Annotation Productivity
- We’ve added new keyboard shortcuts to streamline annotation workflows:
- Quick-select labels using number keys 1–9.
- Fast navigation for arrow-based label selection.
- Shortcuts for negative labels when applicable.
- We’ve added new keyboard shortcuts to streamline annotation workflows:
-
Improved Inference Engine Configuration
- You can now configure inference engines directly through the UI:
- Select from a list of supported inference engines.
- Provide required and optional runtime variables through guided configuration.
- You can now configure inference engines directly through the UI:
-
Better Dataset Statistics Filtering
- Dataset label distribution now respects task type filters.
- GetDatasetStatisticsSimple now supports task type filtering.
-
Training Blueprint metadata can now be marked uneditable on creation.
What's Fixed
- Fixed an issue preventing Blueprint version changes after selecting a Training Blueprint for model training.
- The Model Monitoring page now auto-refreshes as expected.
- Fixed missing evaluation metrics in a model's History tab.
- Fixed an issue with tooltips being covered up when the Classification Banner is present.
- Fixed misleading duplicate upload name error message when there are multipart conflicts for a given upload.
- Fixed an issue in precision–recall curve interpolation for object detection and oriented object detection evaluations, which could result in small AP metric inaccuracies on large or densely labeled datasets.
0.23.2 - November 20, 2025
What's New
- Draggable Strive Assistant
- The Strive Assistant chat window is now draggable and can be repositioned anywhere within the Chariot interface, allowing users to keep the chat accessible while working across views.
What's Fixed
- Fixed an issue preventing model selection for comparison when a project contained a model produced from a - Training Run that had since been deleted.
- Fixed icons going off screen on displays smaller than 768 pixels by making breadcrumbs collapsible.
- Fixed a problem that prevented the retrieval of Snapshots used for training models.
- Fixed a visual glitch on the dataset browse page where datum elements flickered or shifted when hovering over the pagination buttons on certain screen sizes.
- Fixed an issue where the “Show all other predictions” option in model comparison did not work correctly.
0.23.1 - November 15, 2025
What's New�
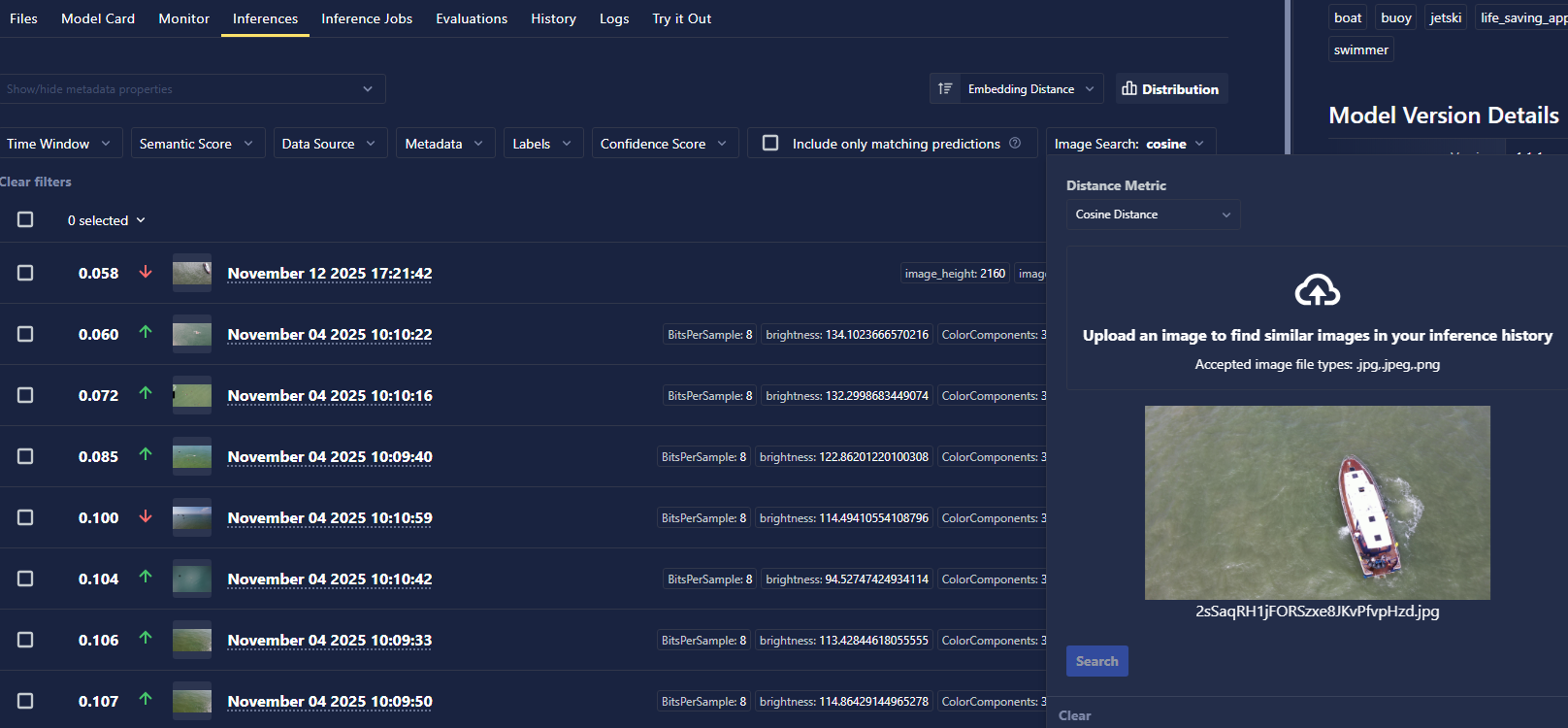
- Inference Image Similarity Search
- Inference now supports image similarity search. Users can supply an image to find visually similar images that have been previously used for inference.
- Strive Assistant
- Users are now presented with a confirmation message before clearing their chat history.
- Strive Assistant is now accessed through the chat icon on the top toolbar.

- Inference Server Scale-Down Timeout
- The maximum timeout for Inference Server scale-down has been increased from one hour to eight hours.
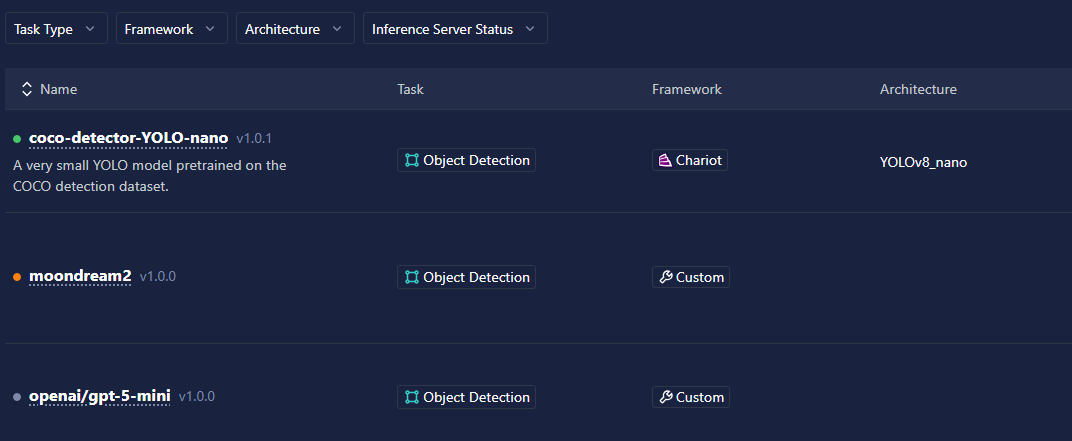
- Inference Server Status
- Inference Server Status is now available directly from the Catalog view, allowing users to quickly see which models are currently deployed and active without navigating into individual model details.
What's Fixed
- Fixed possible out-of-memory and timeout errors when downloading models using the chariot-sdk model.download_model() function. The stream now writes directly to file instead of loading all content into memory.
- Resolved a UI issue that caused the Model Inference Store view to “jump” when navigating between pages. Pagination now functions smoothly even during active inference operations.
- Fixed an issue where the UI did not show an updated label distribution after dataset upload completion. The refresh now occurs automatically.
- Fixed an issue preventing vLLM from running in FIPS-compliant environments by updating internal hashing methods to meet security standards.
- Resolved an issue where Workspaces created under prior Chariot versions failed to start after upgrades due to a
pydantic-core / pydanticversion mismatch.
0.23.0 - November 4, 2025
What's New
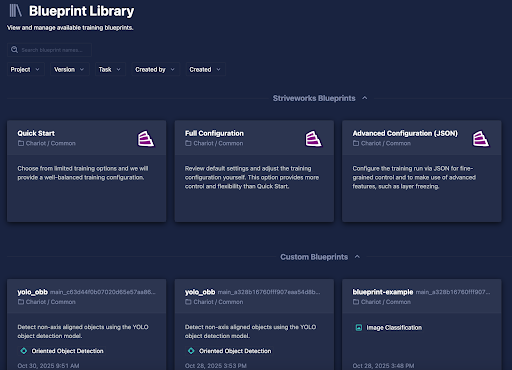
- Training Blueprint Discoverability
- Users can now search for custom Training Blueprints in the Chariot UI, making it easy to find the right Training Blueprint for your model training needs.
- vLLM serving runtime updated to 0.11.0
- Supports more LLM architectures (including gpt-oss-20b/120b) and more GPU architectures (including Volta, Turing, Ampere, and Hopper).
- Supports more runtime options, including finer-grained control over GPU memory usage.
- Now supports tool calling and can be used as a drop-in replacement for an OpenAI provider.
What's Fixed
- Dataset snapshots with no specific task type can now be used in training runs.
- Fixed issue with previously seen datum being presented for a second time in annotation tasks.
- Improved performance for fetching a dataset’s available metadata keys via the
datasets/{dataset_id}/datums/metadata/query-keys. New uploads will immediately benefit from this change. Existing datasets will benefit after subsequent calls once the cache is warmed.
0.22.0 - September 28, 2025
What's New
- Custom Models and Inference Engines
- Chariot now supports custom-defined models and inference engines. Users can upload their custom models under the “Custom” type and can create their own custom inference engine to serve it. Custom models can be any format or runtime.
- New dataset task type: Image Text to Text
- Chariot datasets now support a new task type called “Image Text to Text”. This is an annotation on an image datum and consists of “prompt” and “response” text fields. This annotation can be used to support training of vision language models (VLMs).
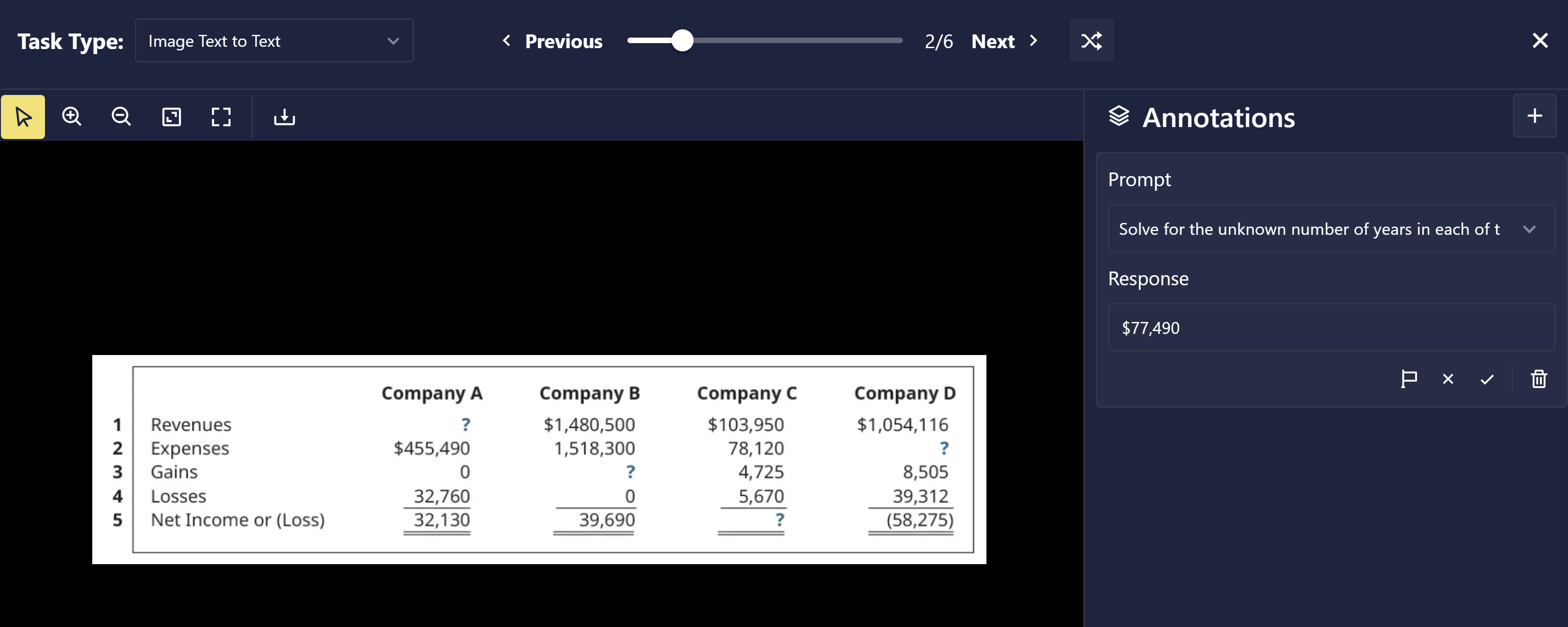
- Chariot datasets now support a new task type called “Image Text to Text”. This is an annotation on an image datum and consists of “prompt” and “response” text fields. This annotation can be used to support training of vision language models (VLMs).
- Inference Server Events
- Inference Server logs now show Kubernetes events in addition to pod logs.
What's Fixed
- Fixed incorrect error status of inference servers when nodes are scaling up
- Fixed issue with large models failing to upload with the SDK and improved model upload time using the SDK. Now, the SDK no longer compresses models for uploads.
- Fixed issue where some inference job statuses were wrongly displayed.
- Fixed resource manager sometimes incorrectly displaying which resources were in use.
- Fixed issue where model comparison failed due to a time zone incompatibility error.
- Resolved issue where metadata filters were ignored when creating dataset views.
- Fixed pod filter not working to filter log content on model inference servers.
- Fixed bounding box editing issue where opposite-side edges would move unexpectedly during bounding box adjustments.
0.21.1 - September 12, 2025
What's New
- Dataset Snapshot Filters:
- Added the ability to filter for unannotated datums and for annotations of a specific task type in the Dataset Snapshot browse page.
- Annotation Details:
- View the full history of individual annotations for greater transparency and traceability.
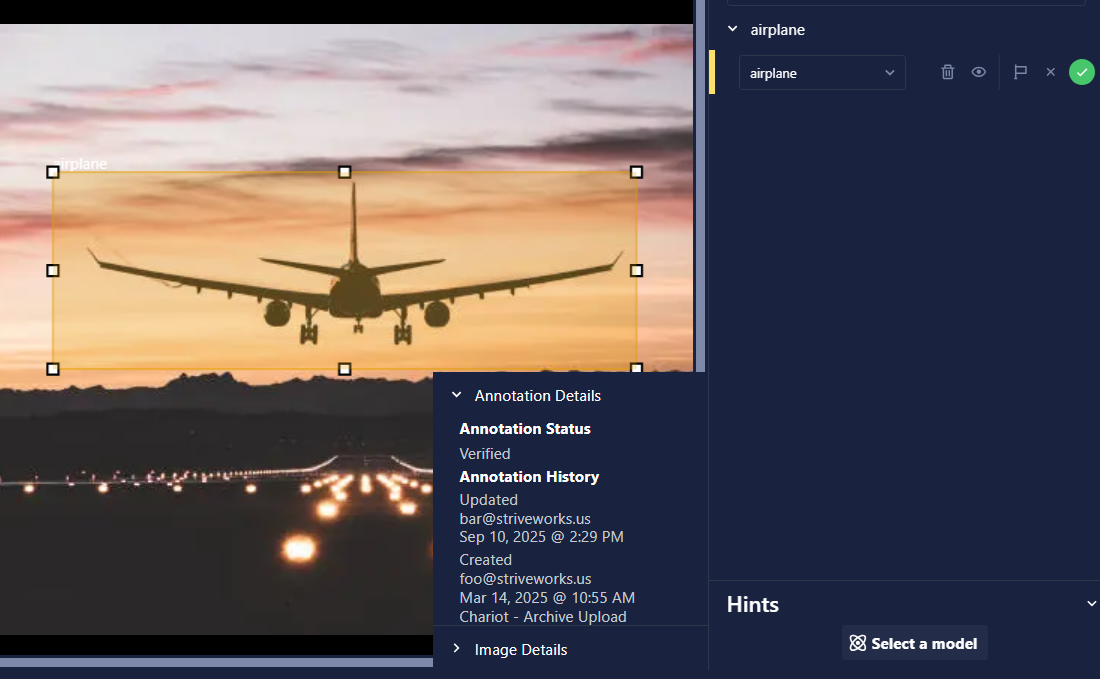
- View the full history of individual annotations for greater transparency and traceability.
- Optional Snapshot Names:
- Snapshot names are now optional. If no name is provided, a unique reference will be created using the timestamp and view.
- TS Video Upload Support:
- Users can now upload .ts video files directly into Chariot datasets through the Chariot UI.
- Dataset ReadMe Updates:
- Increased size limit for dataset ReadMe.
- ReadMe is now included in dataset download.
What's Fixed
- Resolved an issue where the Managing Resources page returned a 404 error on refresh.
- Fixed an error preventing model comparisons from completing when datasets contained Boolean metadata.
- Corrected rendering issues affecting some pages in the Chariot User Guide.
- Fixed an issue where inference jobs failed if a Snapshot allowed unannotated datums or mixed task types.
- Resolved dependency conflicts when installing Chariot RAG inside Chariot Workspaces.
- Fixed an issue in some Chariot instances where using the lasso tool to get segmentation masks from the Segment Anything Model failed.
- Fixed several log capture issues.
- Fixed an issue where the Annotation Editor crashed if no labels were defined for the task.
- Fixed an issue where the UI incorrectly required disk storage to be set for models.
0.21.0 - August 23, 2025
What's New
-
Dataset Cards
- Chariot datasets now support free-text Dataset Cards, allowing users to provide additional details about the dataset such as labeling strategy used, potential biases in the data, usage restrictions, etc. This free-text data complements the structured data, history, and statistics that Chariot already captures and displays.
-
Chariot MCP Strive Assistant—Beta
- Chariot MCP is now available via the SDK for all users.
- Select instances include a chat interface that enables natural language interaction with Chariot.
-
Model Uploads
- Updates have been made to the model upload workflow to ensure smoother and more reliable uploads. Browser-based uploads now support larger file sizes, reducing friction for users working with large models.
-
Improved API Support for Automatic Speech Recognition(ASR) Hugging Face Models
- Chariot now supports sending raw audio bytes directly to ASR models via the API. For example:
payload = {"inputs": [{"name": "inputs","datatype": "BYTES","shape": [1],"parameters": {"content_type": "audio_bytes"},"data": [audio_b64]}]}response = session.post(INFERENCE_SERVER_URL, json=payload) -
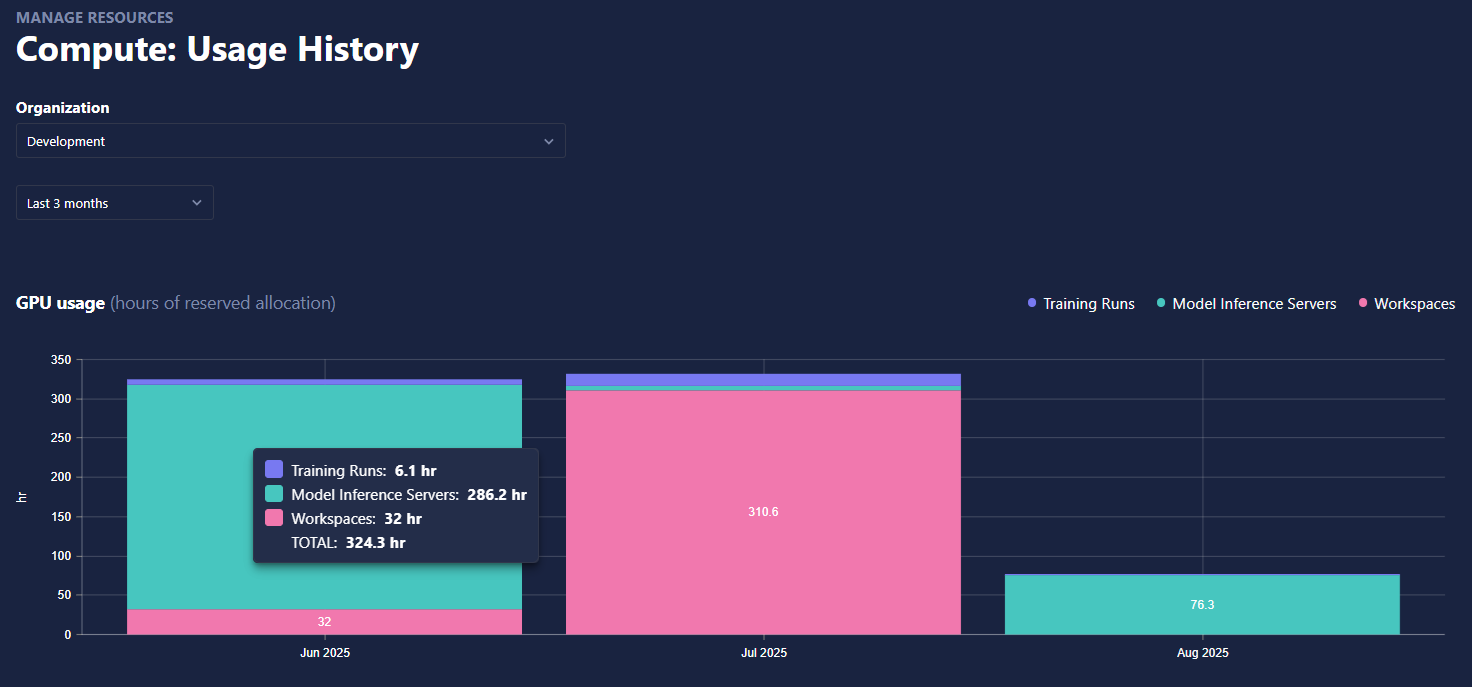
Usage Tracking:
- Users can now view their historical compute usage for the last six months, enabling improved monitoring and resource planning.
What's Fixed
- Resolved a display issue where uploaded model files (e.g., sharded weights and index files) appeared missing due to pagination in the UI. Files are now correctly displayed.
- Fixed a problem where model uploads via the browser UI stalled indefinitely.
- Fixed a bug causing inference retrieval to fail when using both the “Include only matching predictions” filter and a semantic score filter. Queries now return results as expected.
- Fixed an issue where manually entered latitude/longitude boundaries were ignored when creating dataset views. The system now correctly respects user-provided coordinates, not just map-drawn inputs.
- Fixed an error encountered when calculating metrics on the model comparison page due to dataset metadata handling.
0.20.1 - July 29, 2025
What's New
- Dataset Metadata Range Filters:
- Chariot now supports range-based metadata filtering, allowing users to apply operators like
>,<,=,ANYand others to numeric, timestamp, and string value. This enables flexible, type-aware filtering of datums.
- Chariot now supports range-based metadata filtering, allowing users to apply operators like
What's Fixed
- Resolved an issue that caused downloading large models to fail.
- Fixed issues that caused the datasets API to become unresponsive in certain cases.
0.20.0 - July 22nd, 2025
What's New
- Model Comparison:
- Comparison is now supported for image classification and image segmentation models.
- Some metrics can be computed across a selected subset of class labels.
- Image examples now support toggling all detections and ground truth labels, providing greater context for evaluating model performance.
- Documentation: The Chariot User Guide has been updated for improved navigation and readability.
- Logging Improvements:
- Training logs now persist longer: 48 hours for debug logs and 180 days for other logs.
- Logs for bulk inference jobs and Workspace applications are now accessible to users.
- All logs can now be downloaded.
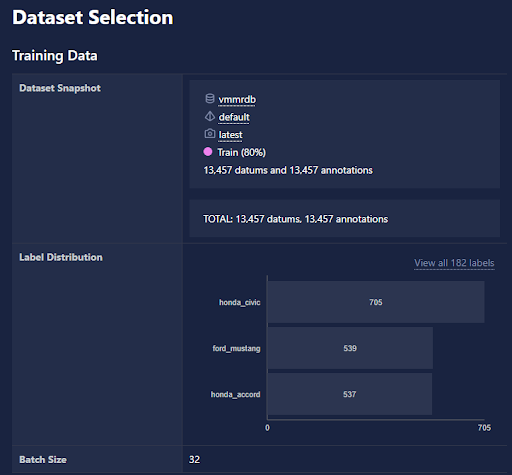
- Updates to the Training UI:
- Added label distribution visualizations to the dataset selection section of Training Run details.
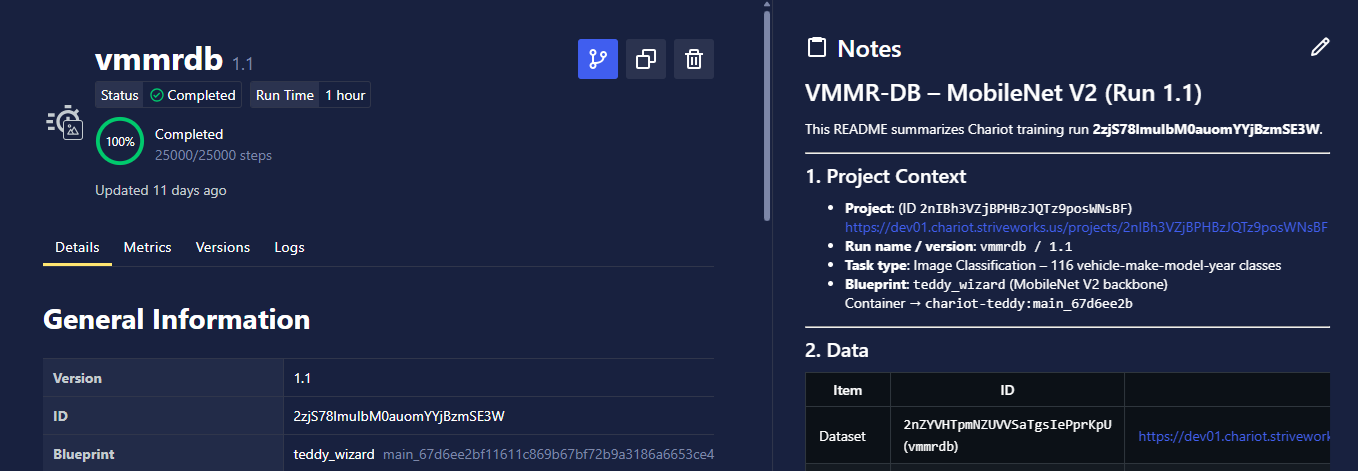
- Introduced a notes section (with Markdown support) for capturing additional context on each training run.
- Added label distribution visualizations to the dataset selection section of Training Run details.
- The “Try-it-out” feature now supports PyTorch object detection models, enabling quick validation directly in the UI.
What's Fixed
- Fixed a UI issue where switching tabs caused partial refreshes of page elements.
- Corrected breadcrumb navigation when viewing models outside the current project context.
- Resolved an issue causing tables in README files to render with white-on-white text.
- Addressed memory-related failures affecting bulk inference jobs.
- Fixed an error preventing the re-upload of exported models due to zero-size directory entries in tar files.
0.19.1 - June 25, 2025
What's New
- Added support for oriented object detection models in the model comparison page.
- Added the ability to start inference jobs directly from the model comparison page.
- Added display of aggregated training and validation datasets statistics when reviewing training run configuration.
- Added the ability to filter by confidence score threshold in the inference store UI.
- Updated YOLO OBB Blueprint to use Valor-lite for all evaluations instead of YOLO Validator ensuring consistent metrics between training runs and bulk inference jobs.
- Improved bulk inference status messaging for jobs with partial failures.
- Improved zip file dataset upload handling with better error messaging for invalid or unsupported zip formats.
- Enhanced back-end and front-end reporting of ephemeral storage resource constraints for training runs
- Improved error handling during concurrent dataset uploads to eliminate "null" error messages.
- Improved handling of duplicate metadata keys in the in the Inference Store
What's Fixed
- Fixed task type filter dropdown not populating in the training runs interface.
- Addressed a limitation where only the 10 most recent checkpoints were displayed.
- Fixed broken hover-over text in the ad-hoc annotation and datum preview interfaces.
0.19.0 - June 5, 2025
What's New
- Updated Annotation Tasks
- The Datasets API now supports managing annotation tasks via api/datasets/v3/tasks. These replace the tasks previously managed by the now-deprecated Annotations API: annotation/v1/api/.
- This release achieves full parity with the previous API and user interface. With that milestone reached, additional functionality is expected in future releases. We’ve already added a couple of additional features:
- The new annotation task framework “locks” a datum while it is open in the Annotation Editor, preventing multiple users—within the same task or across different tasks—from unknowingly working on the same item and creating duplicate annotations.
- Oriented Bounding Box annotation is now supported for annotation tasks
- Training run submission has been enhanced with better ephemeral storage validation and clearer error messaging. The system now properly validates ephemeral storage requests against available cluster resources and provides more informative feedback when resources are insufficient.
- Archived annotations, even if not associated with an archived datum, now appear in the dataset timeline history. Previously, this prevented users from creating a new snapshot when the only changes were archived annotations.
- Inference server transformers (ISTs) are now always turned on (unless this is overridden at the cluster level). ISTs are used to implement Chariot functionality like authorization, inference storage, and drift. For more information on ISTs, refer to the Setting Up an Inference Server section of the user documentation
What's Fixed
- Resource Management:
- Fixed GPU counting logic in the Compute Totals section to properly display allocated GPUs out of total available GPUs instead of showing misleading “X out of 0.”
- Performing actions on resources no longer redirects users back to the first page; instead, it maintains their current position in the resource list.
- Resolved status discrepancies between the resource monitoring page and individual model pages, ensuring consistent status reporting across all interfaces.
- Fixed an issue where the Model Comparison feature incorrectly reported valid model-dataset pairs as invalid when incompatible pairs were also included in the comparison set.
- Resolved project search functionality that was failing due to incorrect URL encoding in API requests.
- Fixed PyTorch model forking functionality that was failing with “Class labels cannot be empty” errors.
0.18.1 - May 9, 2025
What's New
- Datum ID visible in Chariot UI: Added datum ID as a query parameter when viewing datums in dataset preview, making it easier to identify, reference, and share specific datums. This enhancement improves workflow efficiency when investigating model performance or addressing data issues.
- Model Class Label Index Map: Updated copy class label index map to be string-to-integer JSON class label mappings. This simplifies the process of downloading a model from one project and uploading it to another by providing the exact format required for uploads.
What's Fixed
- Resolved an issue where score thresholding functionality was not working for oriented object detection models trained by the yolo_obb Blueprint
0.18.0 - April 25, 2025
What's New
- Model Forking: Users can now fork models from one project to another while maintaining lineage, which enables teams to build upon existing work, share successful models across departments, and better organize model iterations.
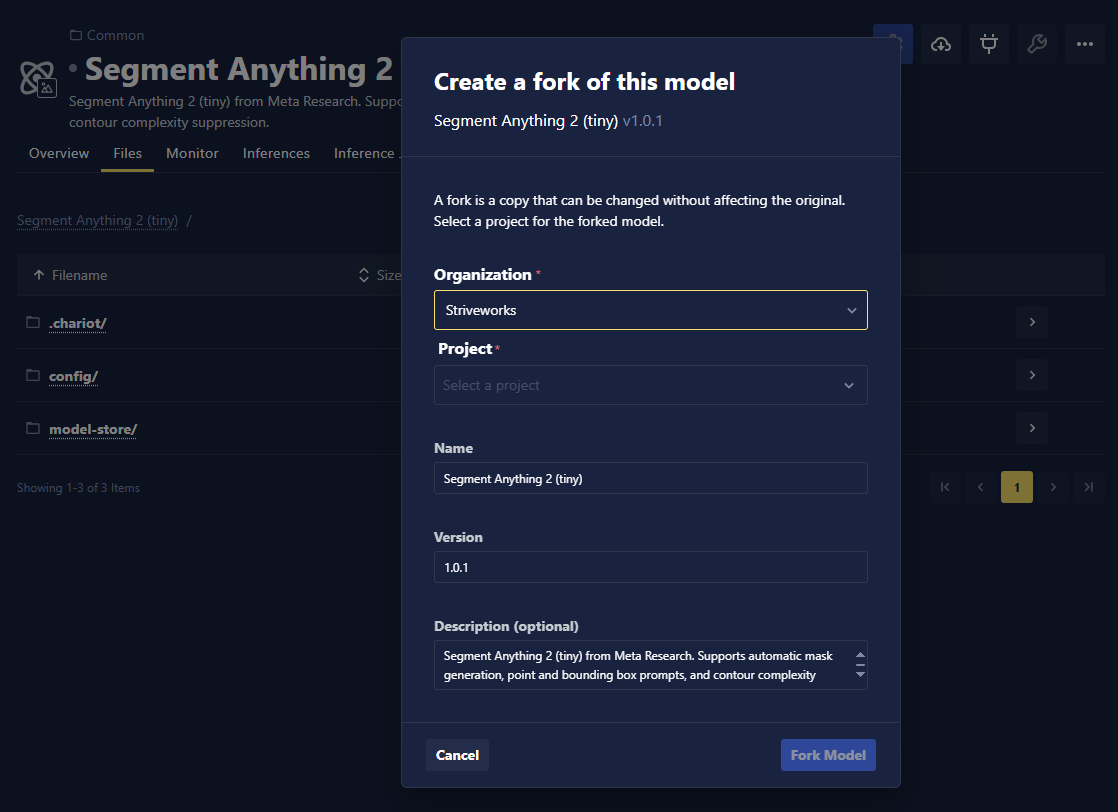
- Dataset Snapshot Search: Added the ability to search snapshots by name, making it easier to find specific snapshots when working with large numbers of dataset Snapshots. This feature also includes filtering by View for more precise navigation.
- Log Improvements:
- Logs for training runs and inference servers can now be downloaded as JSON files.
- Improved readability of inference server logs.
- Training Run Filtering: Added the ability to filter training runs in the UI by the user who created them.
What's Fixed
- UI and Navigation: Fixed Multiple UI and Navigation Issues:
- Corrected a display issue where annotation jobs in non-organization mode incorrectly showed "Access Restricted" even when users had proper access permissions.
- Fixed a bug where labels would be replaced with index numbers when validating datasets.
- Resolved issues with annotation selection visibility and interaction in the dataset preview.
- Resolved an issue where the model page UI would show resources not actually allocated to the model's inference server.
- Fixed a bug that prevented exporting inferences to new datasets in different projects.
- Fixed a bug that prevented some users from editing the settings of workspace applications after they were started.
- Models and Inference: Addressed several model-related issues:
- Corrected an issue where multiple annotations per image were being exported from image classification models instead of only the highest probability label.
- Fixed a bug where drift checks were running even when explicitly disabled, ensuring drift detection only occurs when enabled by users.
0.17.3 - April 15, 2025
What's New
- Annotation Experience: There are several improvements to the annotation workflow:
- Annotations now remain selected after changing labels in the dataset preview window.
- Selected annotations automatically scroll into view after label changes.
- Dataset Search Enhancement: Dataset search now begins after typing a single character instead of requiring three characters, making it easier to find datasets with short names or prefixes.
- tmux in Notebook Base Image: The notebook base image now includes tmux, allowing users to run persistent processes that continue even when notebook sessions close.
- Bulk Inference Evaluation Improvement: Bulk inference for model evaluation no longer filters detections using a default threshold, which provides more accurate evaluation metrics.
What's Fixed
- Data Management: Improved data handling reliability:
- Fixed an issue when adding datums to a dataset from the inference store would fail with a "source URL is invalid" error.
- Resolved an error when exporting large numbers of datums (>10k) from the inference store to a dataset.
- UI and Navigation: Fixed multiple UI issues:
- Corrected an issue when annotation jobs in non-organization mode incorrectly displayed "Access Restricted."
- Fixed errors that occurred when attempting to annotate certain images.
- Resolved a bug where clicking through dataset images would sometimes randomly close the datum view.
- Fixed pagination issues with training runs that prevented access to runs beyond the first page.
- Corrected breadcrumb duplication that occurred after adding users to projects.
- Fixed the exit button functionality on the "add to dataset" window.
- Removed redundant tooltips on the training details page.
- Fixed inconsistent behavior when navigating through dataset preview with direct clicks versus arrow navigation.
- Models and Training: Fixed multiple model-related issues:
- Resolved an issue where the YOLO OBB Blueprint allowed training progress to exceed 100% completion when starting from a checkpoint.
- Fixed a bug where inference servers didn't scale up properly on creation.
- Corrected an issue where enabling inference store on a running model did not properly store inferences until restart of inference server.
- Addressed authorization errors when attempting to use models in the Global project.
0.17.0 - March 14, 2025
What's New
- Organizations Mode (Alpha Version) is now available. It is a new type of structure where all users and projects belong to organizations. Please talk to your Chariot admin about enabling it.
- There is now role-based access control (RBAC) for users at both the organization and project view the roles here.
- Projects now have three levels of visibility: public, restricted, and private.
- Organizations Mode lays the groundwork for multi-tenancy, usage tracking, finer-grained access control, and many more features that we plan to release throughout the year.
- Image classification and image segmentation tasks are now supported through the Dataset Preview Window.
- Improved latency when collecting and displaying resource usage on the Resource Management page.
- Added
RandomCropsetting, previously limited to image segmentation, to the "Full Configuration" Training - - Run wizard for image classification and object detection. approval_statusfields when filtering datums and/or creating Views are now an array and accept multiple values.- Improvements to inference server settings prevent occurrences of settings displayed in the user interface being out of sync with those used by the inference server.
- Added endpoint
GET /views/{viewId}/snapshots/countto retrieve the count of Snapshots for a View that matches the request filter criteria.
What's Fixed
- Model-generated inferences coming from the Inference Store now have the correct
needs_reviewannotation status. - Fixed issues with inference servers not scaling down properly.
- Fixed an issue with bulk inferences being stored twice.
- Fixed an issue with model evaluation metrics failing to filter on metadata other than geolocation.
- Fixed an issue preventing the ability to input a value for metadata filters on the Inference Store page.
- Fixed various issues with images and/or labels not loading properly in Dataset Preview.
- Fixed an issue with some model evaluation metrics missing the IoU threshold.
- Fixed an issue where Snapshots were not selectable due to a lack of pagination.
0.16.0 - January 24, 2025
What's New
- Oriented Bounding Boxes: Chariot now fully supports oriented bounding boxes for datasets and models. See the Chariot User Guide for information about the format for oriented annotations as well as a sample Blueprint for training a model that leverages oriented bounding boxes.
- vLLM Support: Supported Hugging Face models can now run using the vLLM runtime, allowing for significantly higher throughput and efficient memory management.
- Exportable Data Drift Detectors: Artifacts that calculate data drift can now be exported and reuploaded to another Chariot instance, where they can be used for drift monitoring. Drift detector artifacts can be found under the
.chariot/drift-detectorspath.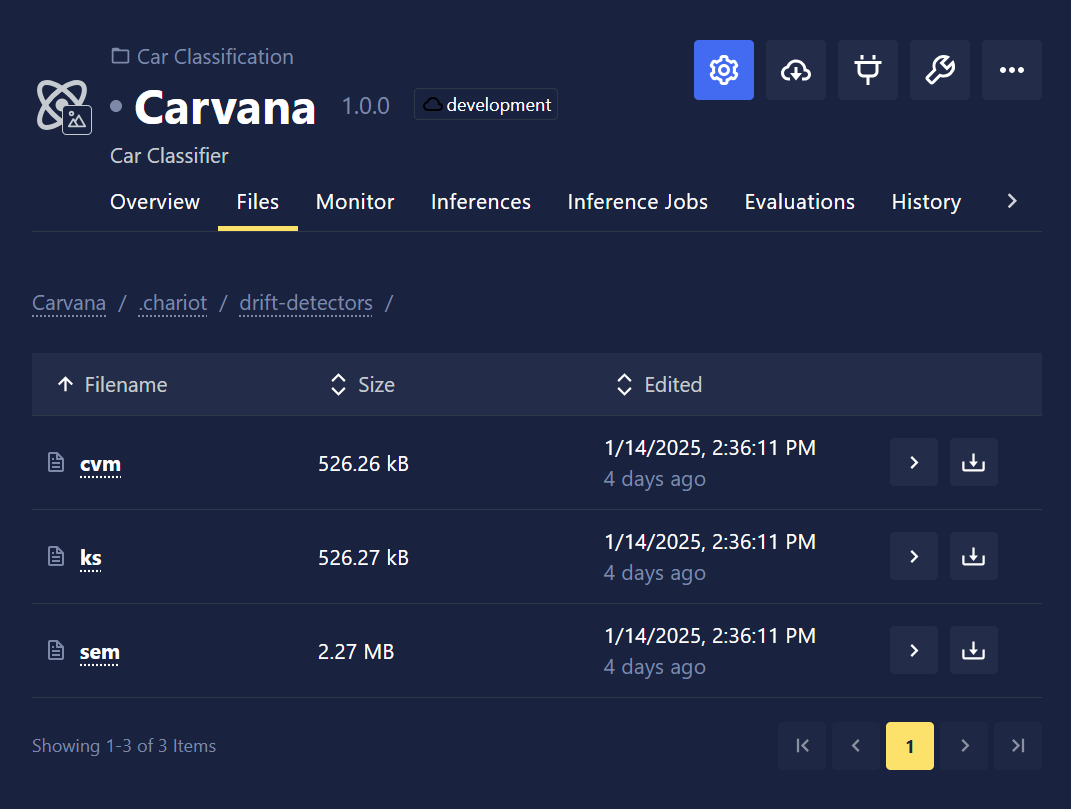
What's Fixed
- Fixed issue of Hugging Face models that were previously exported from Chariot not uploading.
- Fixed issue of dataset history timeline not being updated when annotations were made by the Python SDK.
- Fixed issue causing
chariot.models.model.get_catalogfunction in the SDK to fail. - Fixed issue of Image Details panel expanding each time a new datum is loaded.
- Fixed issue of apparent "frozen" page when deleting models.
0.15.0 - December 20, 2024
What's New
- Annotate Data Directly from Dataset Page (ALPHA): Users can now add, remove, update, and review annotations directly in the Datum Preview view within the Datasets tab. This feature enables users to quickly filter for and annotate specific images, enhancing efficiency in data annotation and management. Note: This feature is only supported for object detection annotations at the moment; support for other annotation types is coming soon!
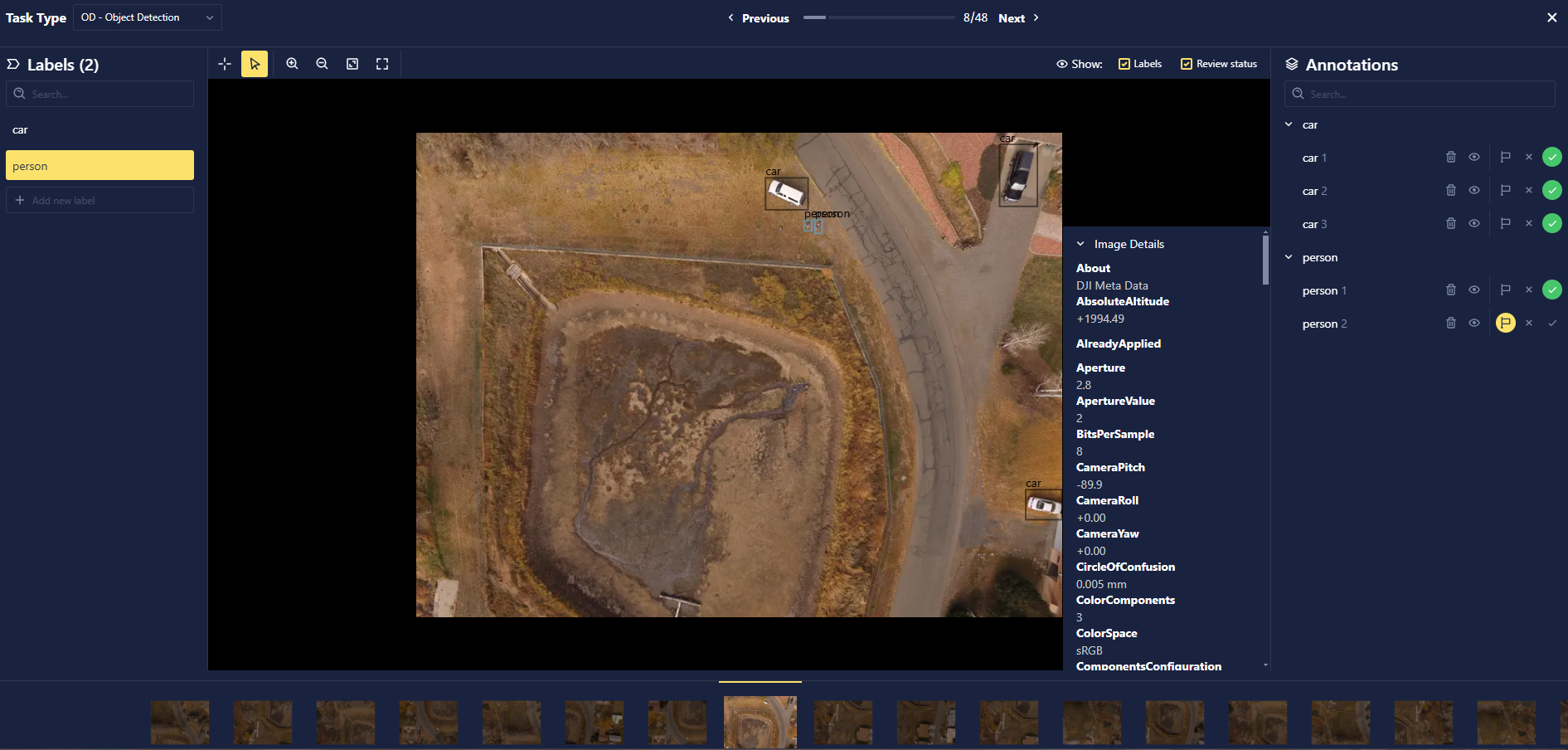
- Annotation Metadata: Users can now include metadata for annotations. This enables enhanced filtering capabilities to query this metadata when retrieving annotations and associated data. Key updates to our API endpoints include:
- Create Annotations with Metadata: POST
/datums/{datumId}/annotationsto create an annotation, now with the option to include pre-existing metadata and an approval status. - Archive Annotations: POST
/annotations/{annotationId}/archiveAnnotationallows archiving a single annotation by ID.
- Create Annotations with Metadata: POST
- Annotation QA Process: Leveraging our new annotation metadata functionality, users can now perform a QA process for annotations using the Approval Status field. This field helps categorize annotations as Approved, Rejected, or Requested, facilitating scenarios where a second opinion on an annotation is necessary. Updates include:
- Enhanced Search and View Capabilities: The approval_status field is now added to all relevant datum search and view endpoints, such as POST
/datasets/{datasetId}/getDatumsand POST/datasets/{datasetId}/views, enabling users to filter by an empty approval_status, which allows for more flexible data handling. - Create Annotations with Metadata: Users can now create annotations with pre-existing metadata and approval status directly via uploads.
- Advanced Retrieval Options: Users can retrieve datums, statistics, and labels for datasets or snapshots, filtered using annotation metadata.
- Enhanced Search and View Capabilities: The approval_status field is now added to all relevant datum search and view endpoints, such as POST
- Dataset Event Grouping: Dataset events that include various user actions on a specific dataset or view are now grouped with similar events. Users can see this change reflected in the History tabs within Dataset Details and View Details, as well as when selecting a Point in Time during snapshot creation.
- Usage of Predicted Labels From Inference Store: Users now have the option to include predicted labels when adding data to a dataset. All predicted labels are assigned the Requested approval status. This status indicates that these annotations require review and adjustment before being utilized in training models, ensuring that only verified data influences model accuracy.
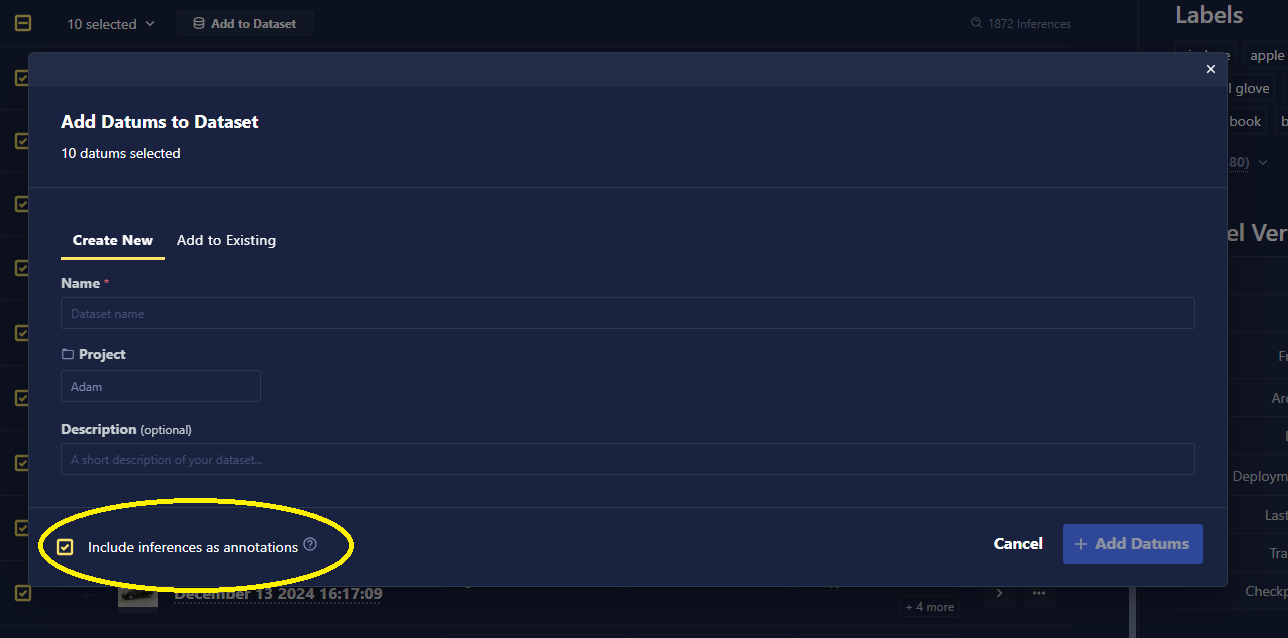
- Visualization of Inference Store Data: Users can now visualize distributions of predicted labels and metadata from source data within the inference store and apply various filtering methods to these visualizations to better assess model performance, detect potential drift, and make informed decisions about models in real time.
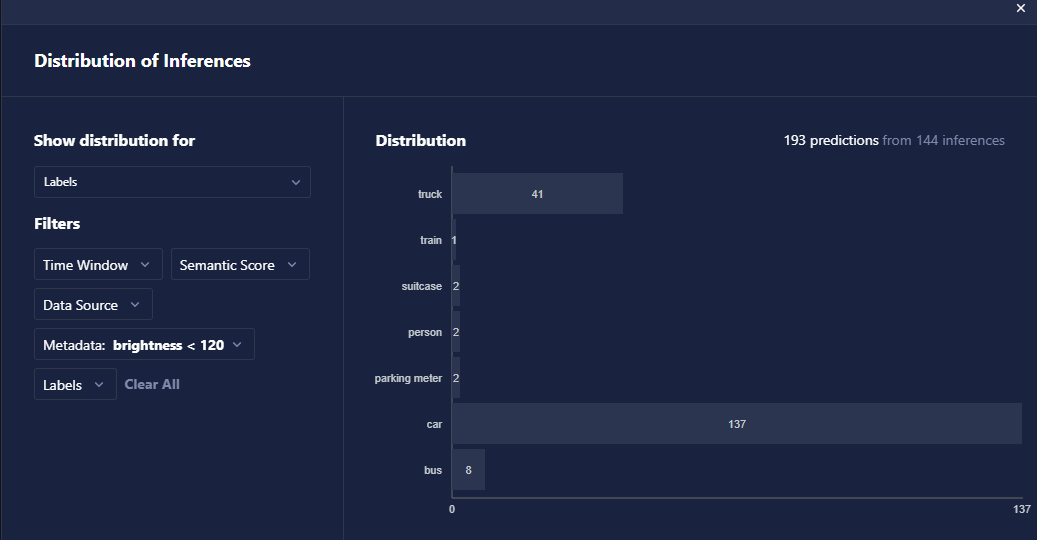
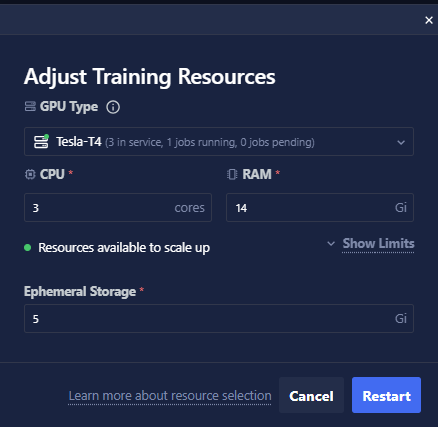
- Quick-Adjust Training Compute Resources: Training runs that have been stopped or have encountered errors can now be swiftly restarted with updated compute resources, minimizing downtime and optimizing performance.
- Chariot now automatically adds datum metadata to images extracted from video uploads (including Chariot.Upload.Video.Frame, Chariot.Upload.Video.Id, and Chariot.Upload.Video.FFMPEGMetadata).
- When assigning datums to splits during snapshot creation, Chariot now assigns datums with a Chariot.Upload.Video.Id metadata tag temporally by frame number, grouping frames together in splits. All other datums will continue to use random assignment.
What's Fixed
- Fixed dataset Updated at Time displaying incorrect value. -Downloading single datums no longer removes the file extension.
0.14.0 - October 4, 2024
What's New
- Editable Model Card in Models Overview Tab: In a follow up to the updates released in 0.13, where users could view and edit individual model files, users can now see and edit a "model card" in the Models Overview tab. Users can supply verbose details of a model, using markdown instead of being limited to a small textbox to supply a model description. This tab is populated using a .readme file that the user provides as part of a models file package.
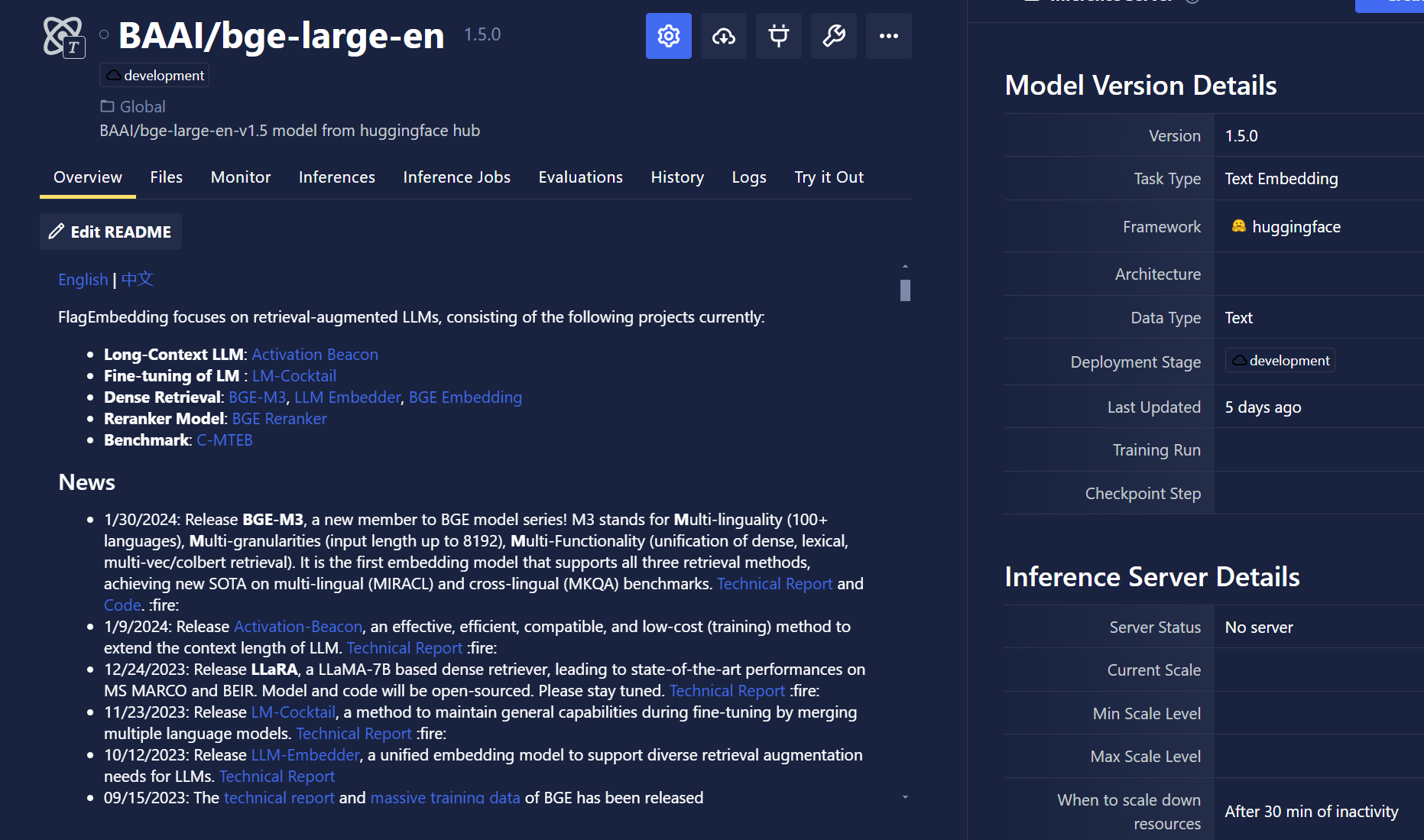
If no .readme file is available, users have the ability to create one by clicking Edit on the models overview tab directly.
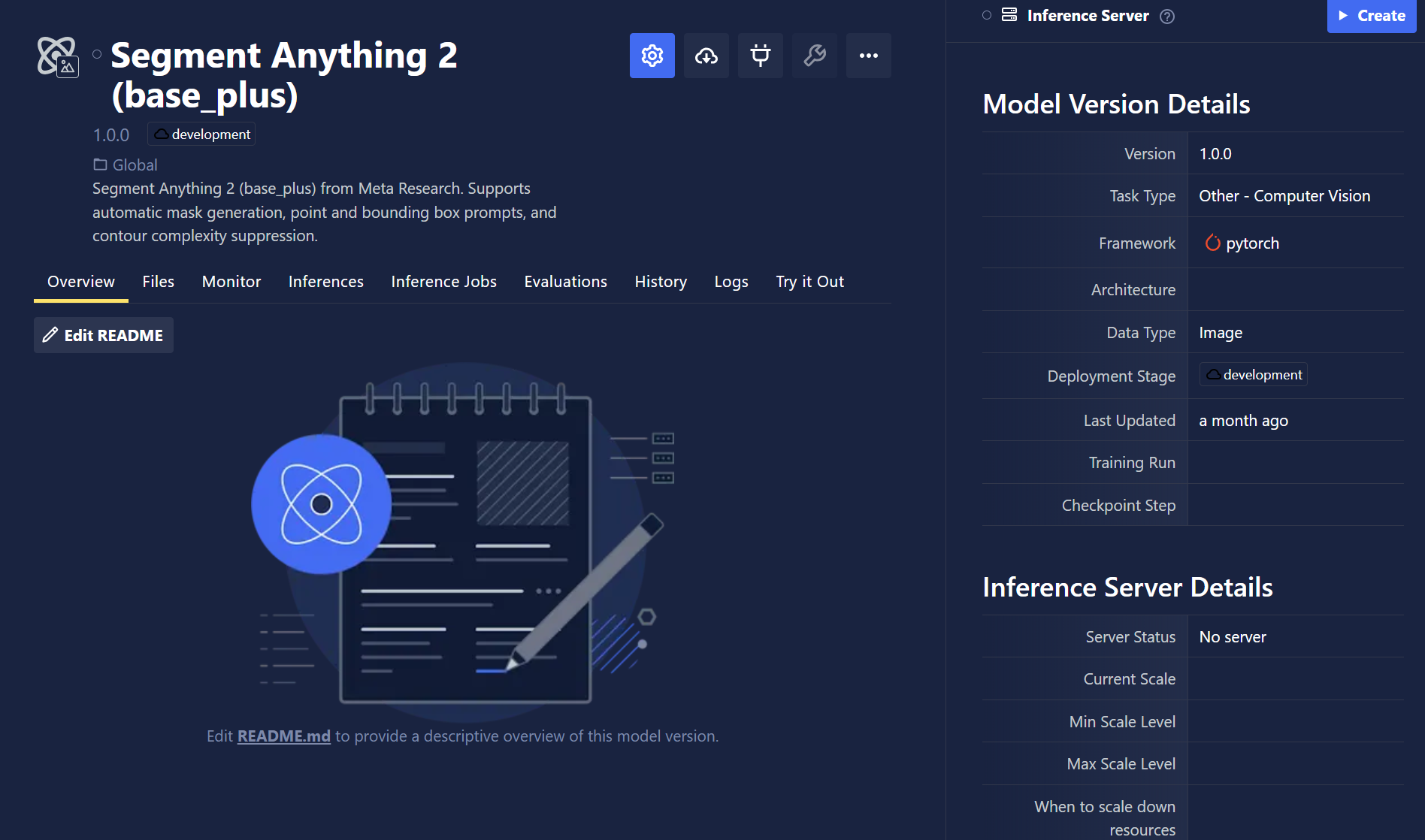
- Model Performance Comparison: Users can now compare the performance of different models in their project. Multiple models of the same task type can be compared for their performance on the same dataset. Users can also set up different comparison "sets" where evaluation metrics for multiple sets of models evaluated on datasets are displayed together. Users have the ability to add filters to the comparison to only evaluate the models on data that meets specific criteria such as location of the image capture.
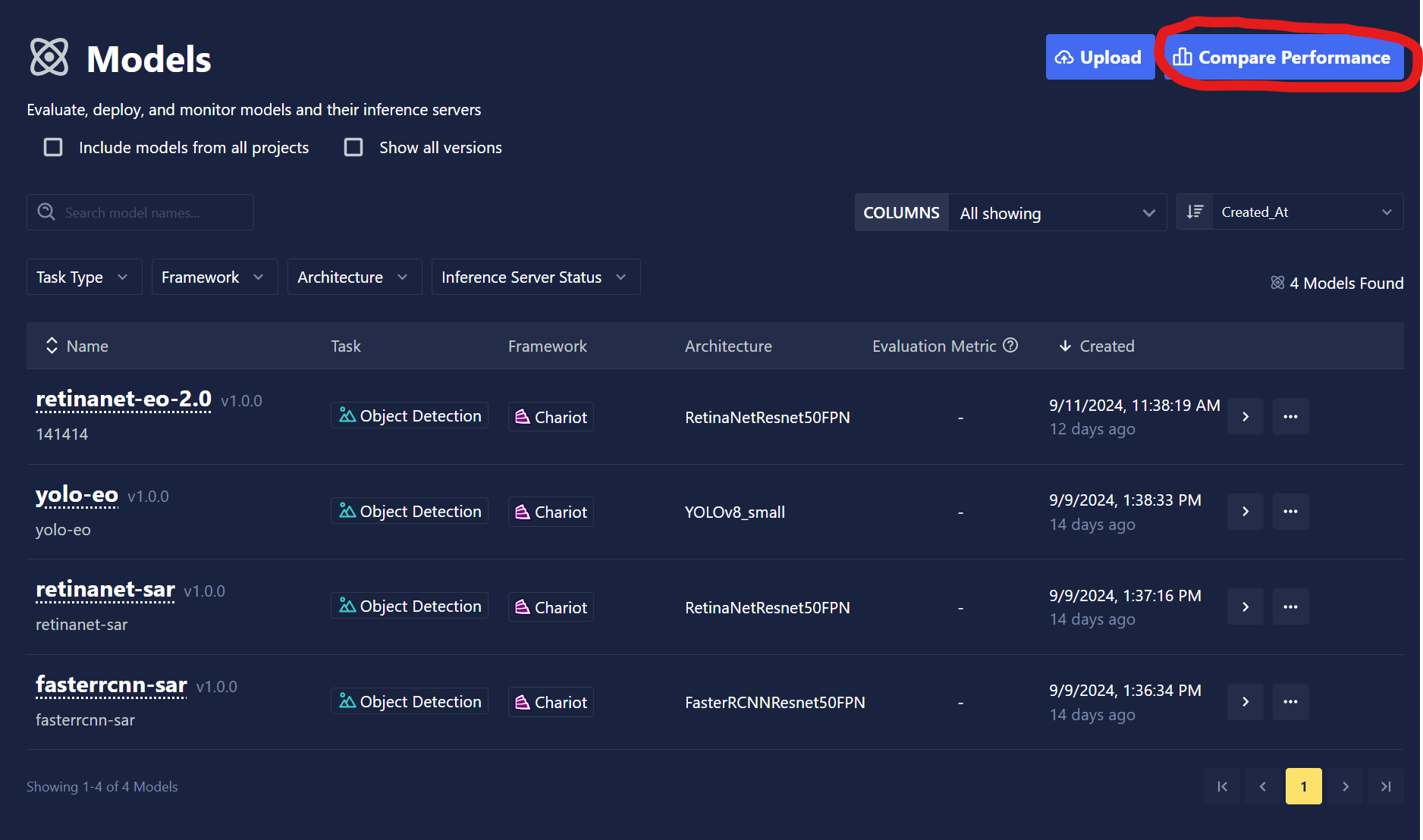
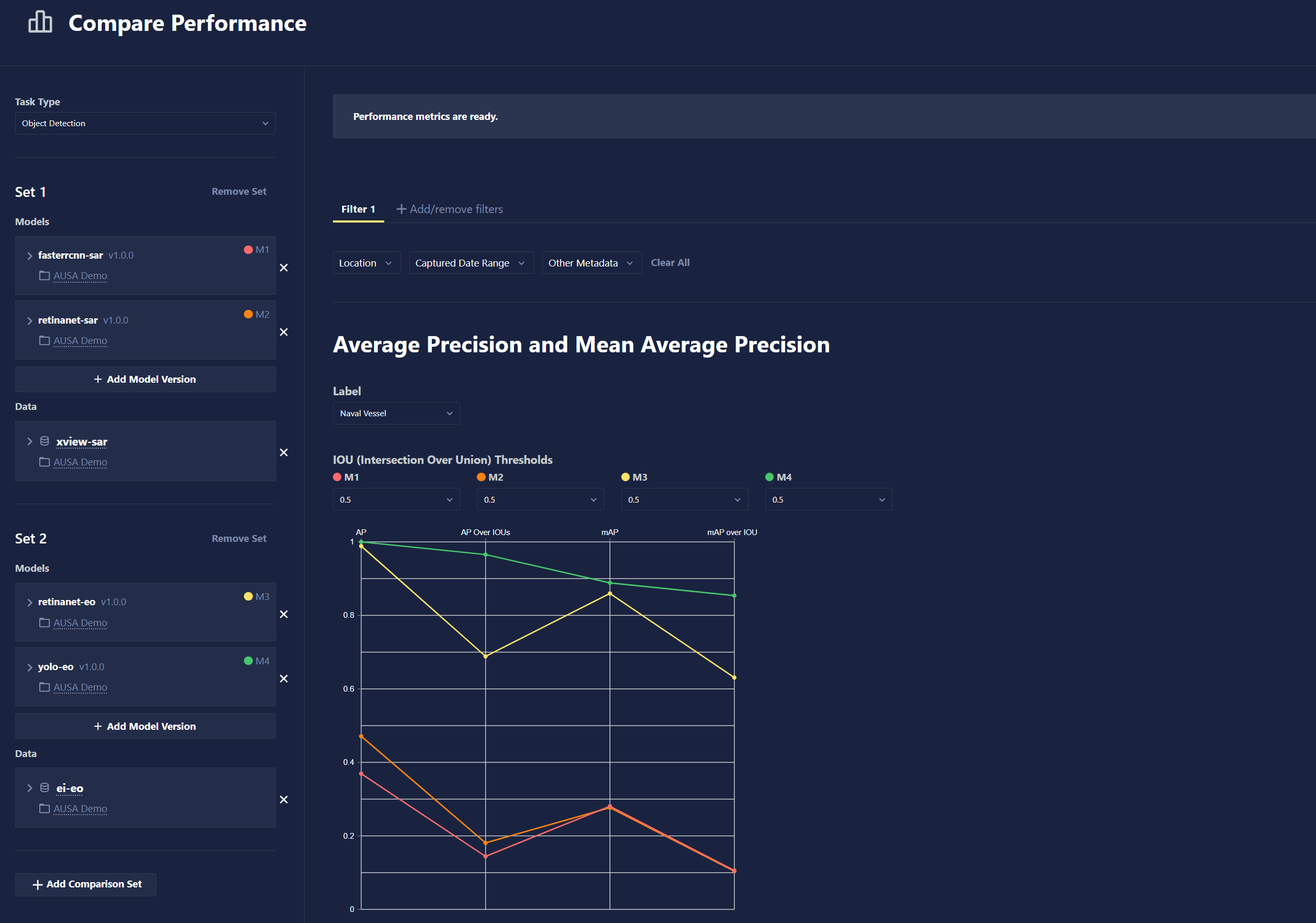
-
Private Image Support for Blueprints: With the help of Chariot's Secret Manager, users can now use images from their private repositories for training models through Blueprints. Prior to this release, users could only create Blueprints using images from publicly accessible repositories, which limited the proprietary training frameworks they could use to train models, based on an organization's security and privacy restrictions.
-
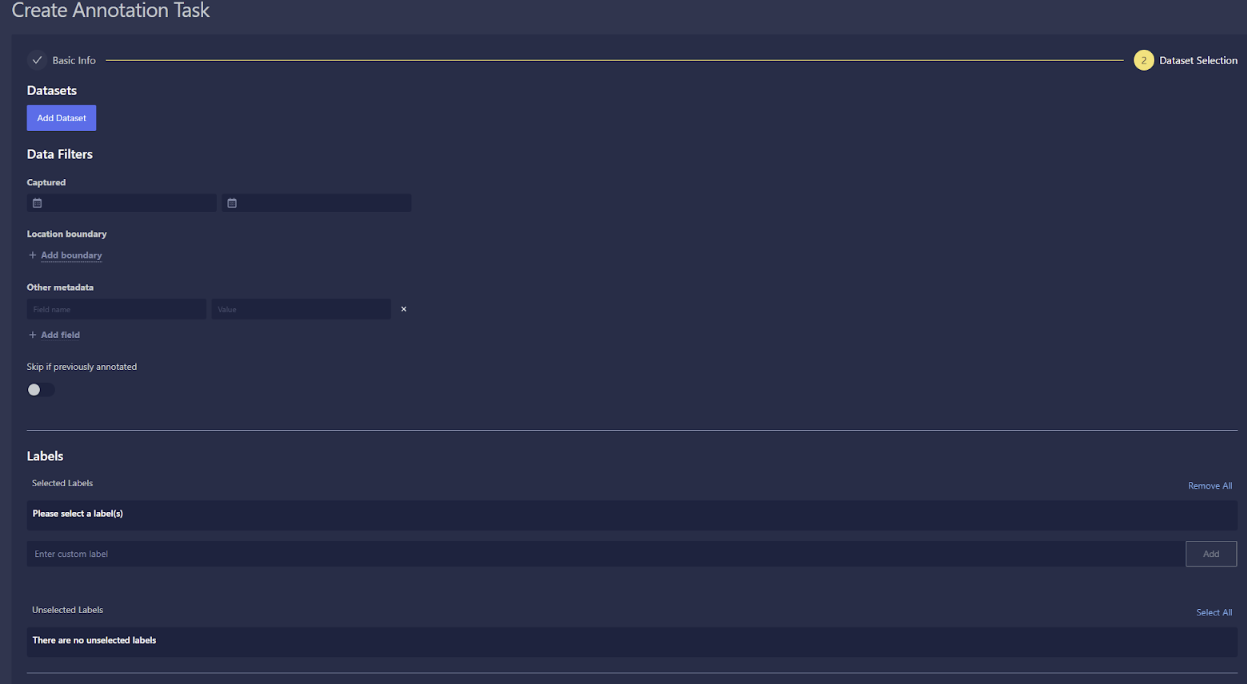
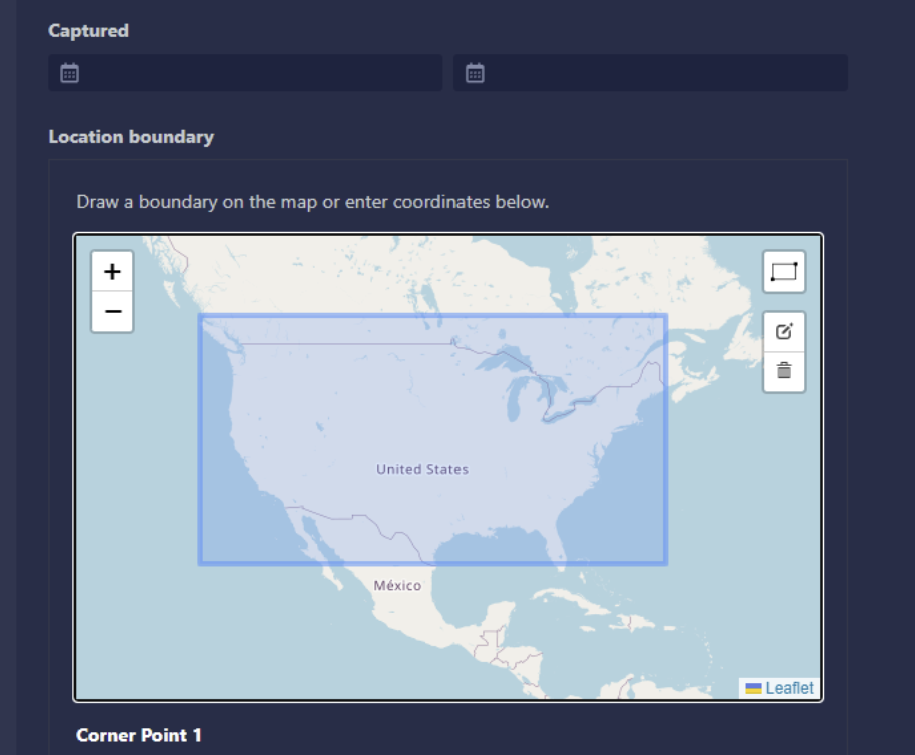
Filter Data When Creating an Annotation Task: Users can now add filters to specify the slice of the dataset that is included in an annotation task when creating a task. This includes captured data, location boundary, and other metadata. The location boundary can be specified by drawing a coordinate box in the map:
0.13.0 - September 13, 2024
What's New
- Model files: Users can now view the individual files that make up a model directly, similar to browsing a GitHub repository. This enhancement eliminates the need to download the entire model just to inspect its contents, providing a more efficient and streamlined experience for users. However, this feature is currently limited to files smaller than 10 megabytes, ensuring quick and easy access without compromising performance. This update enhances transparency and accessibility, making it easier for users to explore and work with models.
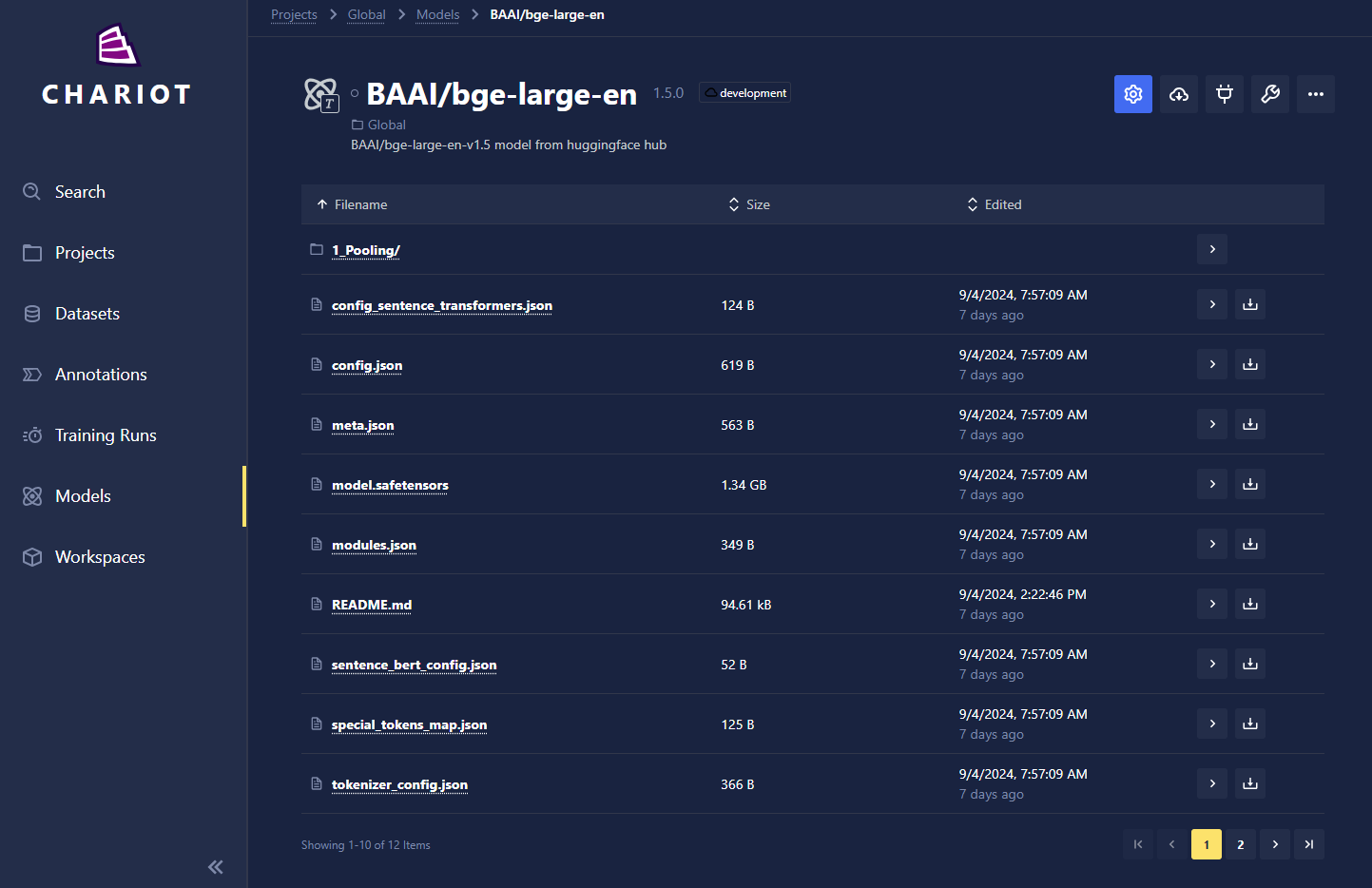
- "Quick Start" Training Wizard: Users now have the option to use a simplified workflow to set up a training run that only requires choosing from a few parameters and settings. After selecting Start New Run on the training runs list, select Quick Start on Step 2 of the wizard, the Blueprint Selection step (note that choosing Full Configuration will take you through the legacy version of the wizard that exposes all parameters and settings):
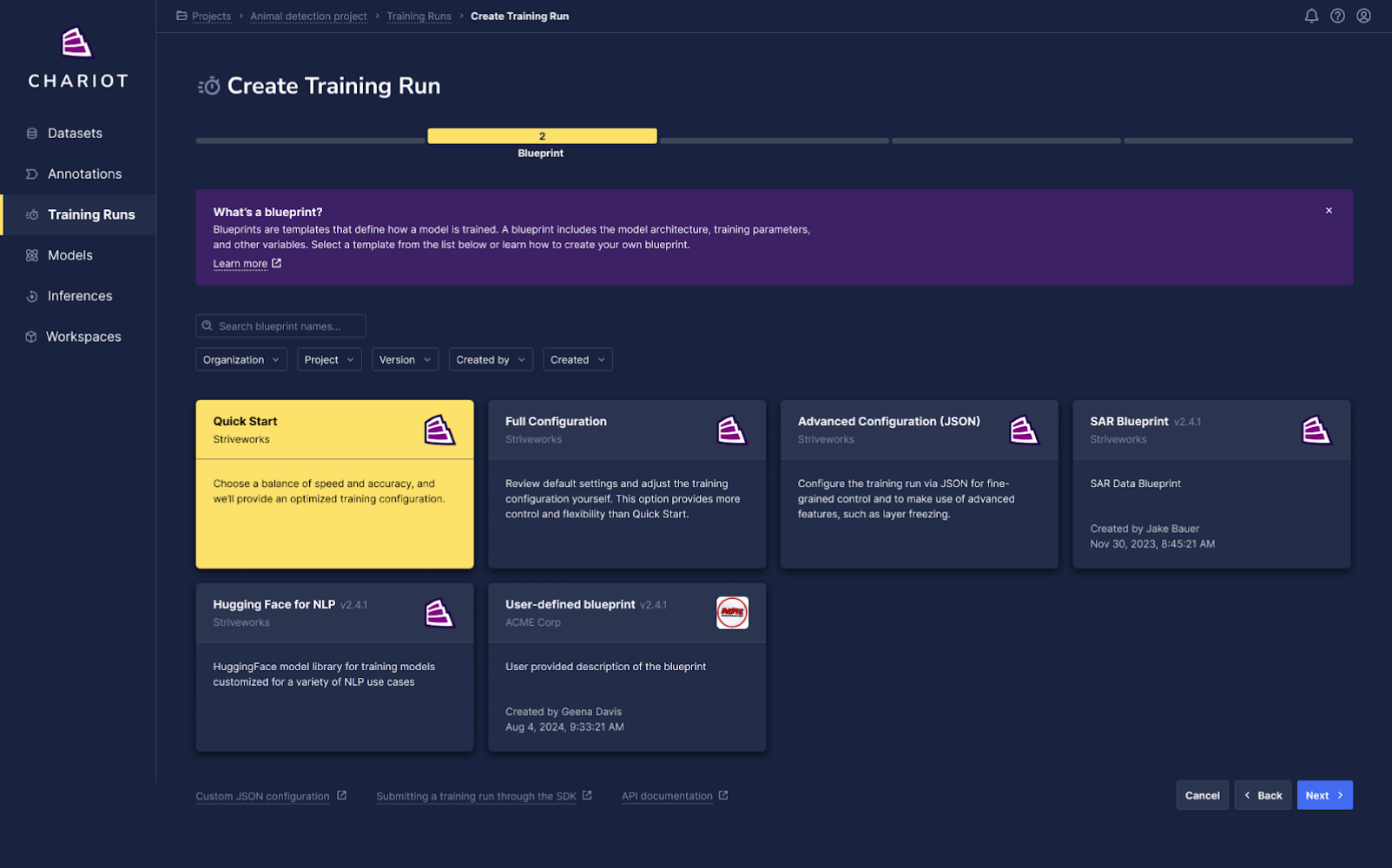
After selecting the dataset for training, choose from a limited number of key options such as the starting model and training length.
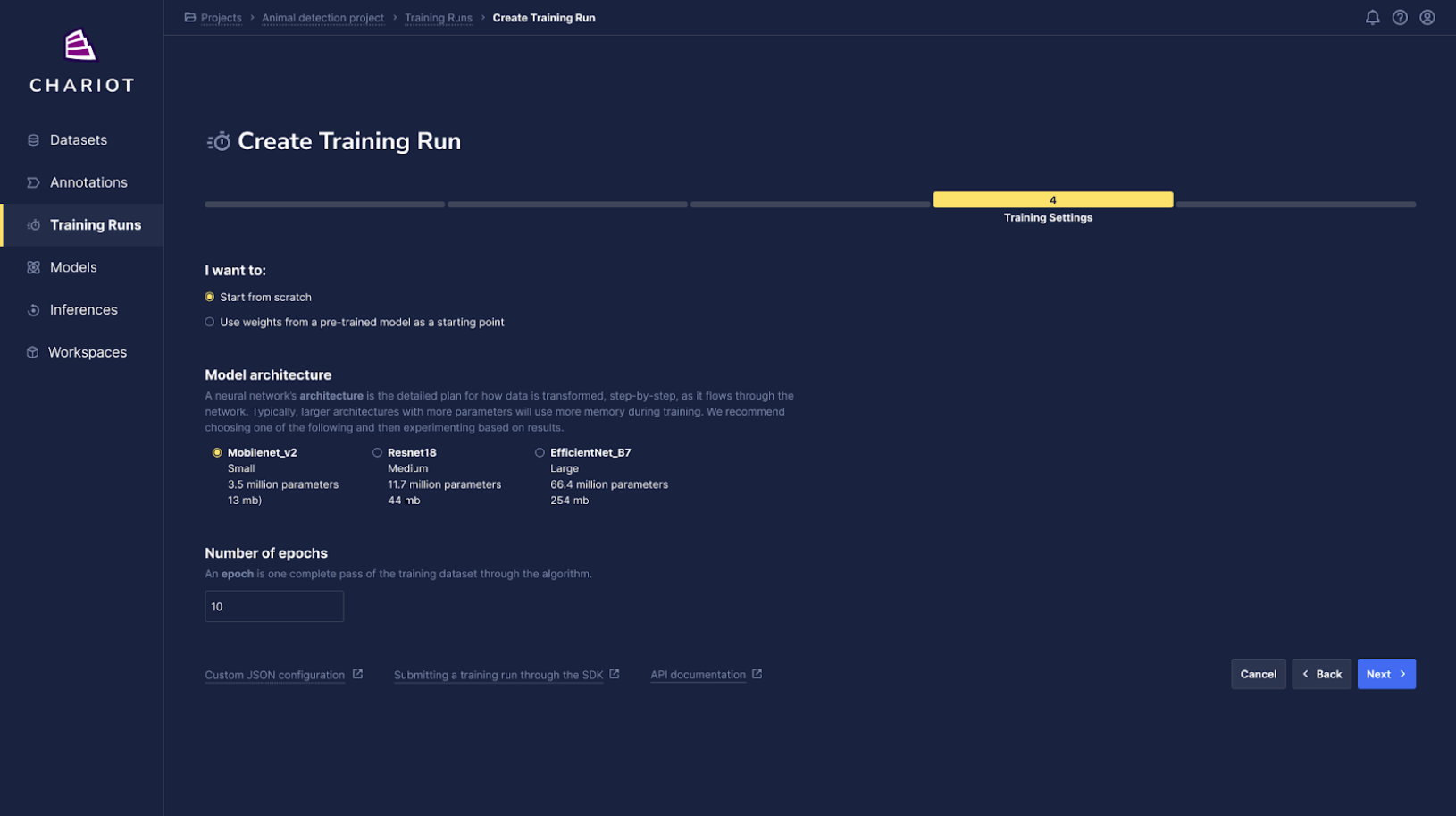
Note two important changes from the full configuration option:
-
Training length is specified in epochs versus previously used steps
-
We have narrowed down model architecture options from the full Chariot catalog to just three curated options per task type based on size and effectiveness
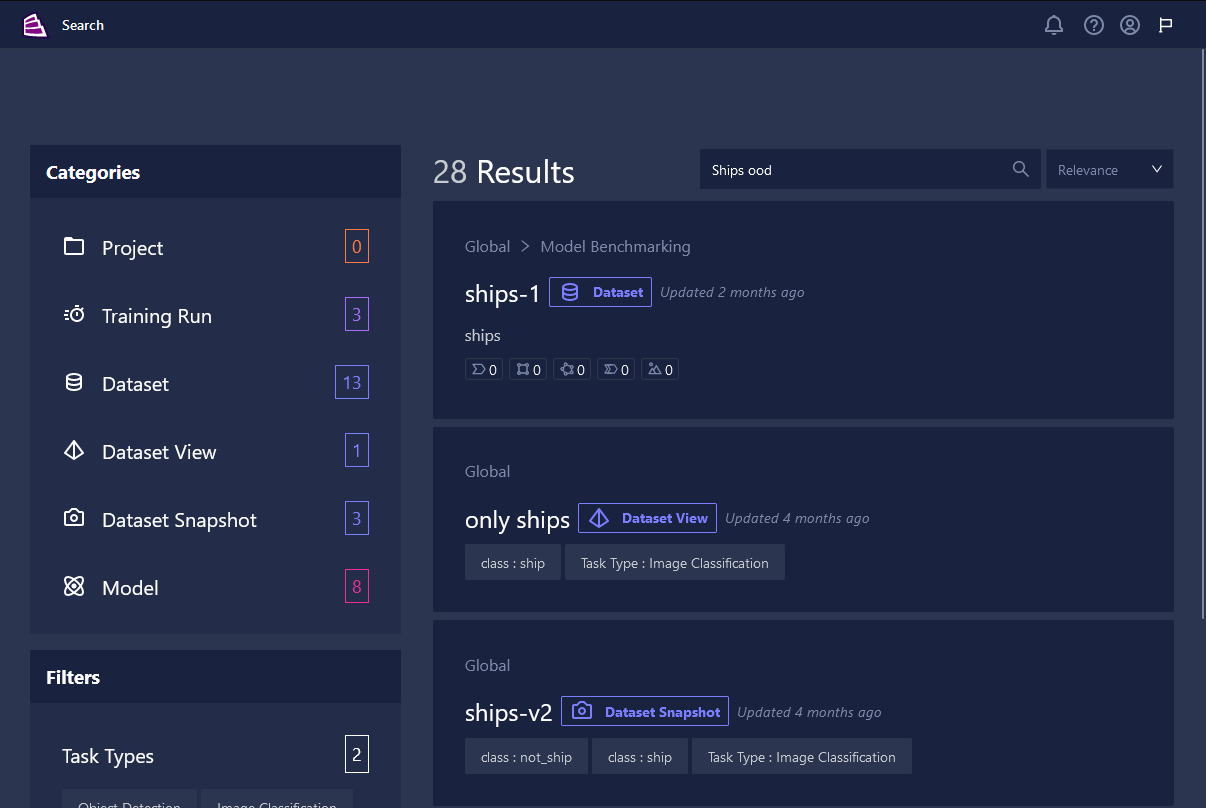
-
Global and project search have both been updated to support our new version of Datasets from release 0.9. Two important concepts from that update are dataset views and snapshots. These are now searchable alongside all of the other major entities that make up Chariot.
What's Fixed
- Fixed broken link to learn more about using secrets
- Fixed hidden white space that was causing user creation/login to fail
0.12.0 - August 16, 2024
What's New
-
Segment Anything Lasso Tool: Users now have the ability to use a new feature in Chariot powered by the Segment Anything Model to speed up segmentation annotations and make them more accurate. With the Lasso Tool, users can draw a bounding box around the object in the image they wish to segment, and the model provides a segmentation mask. See the Chariot User Guide for more detailed information.
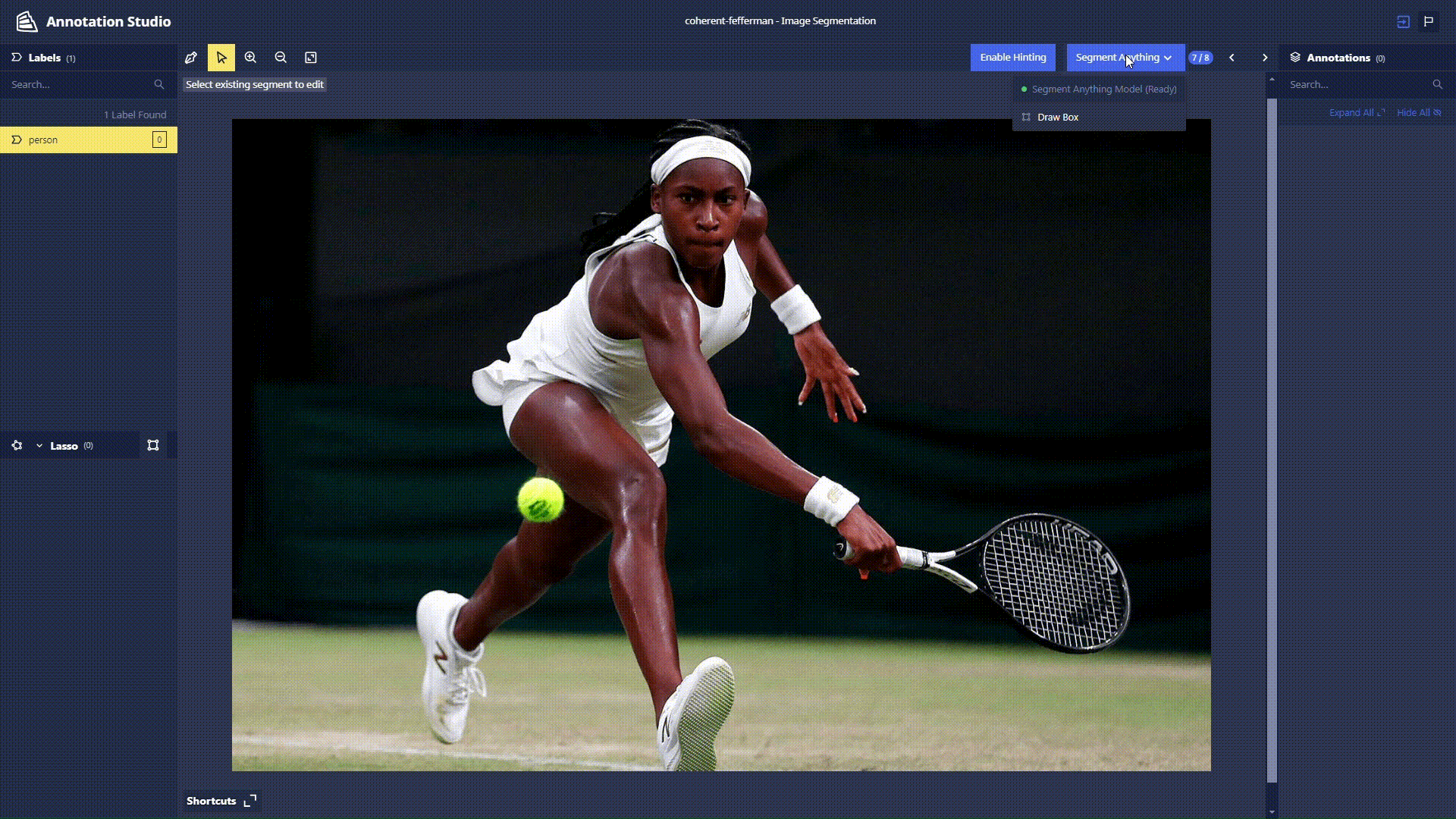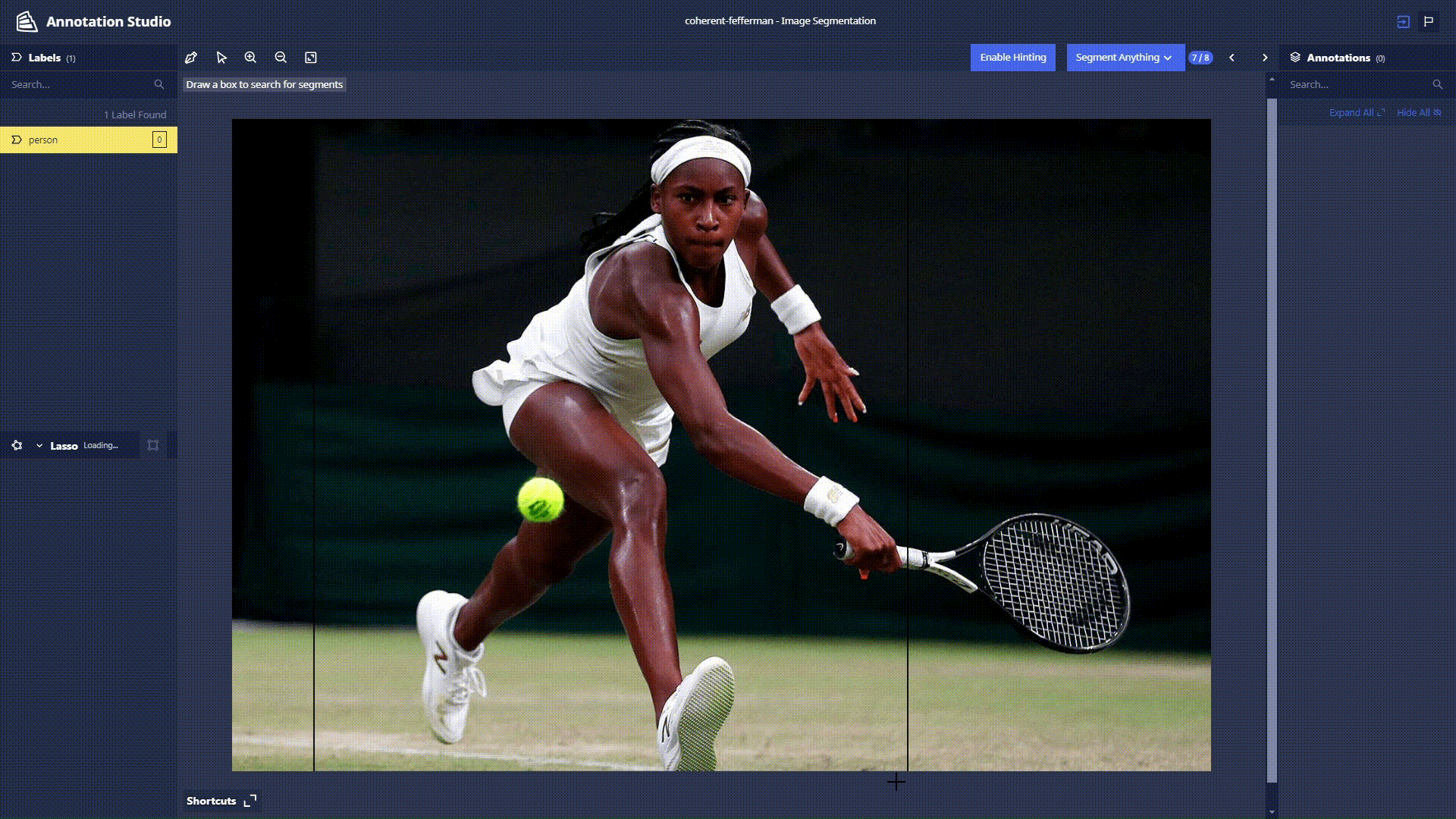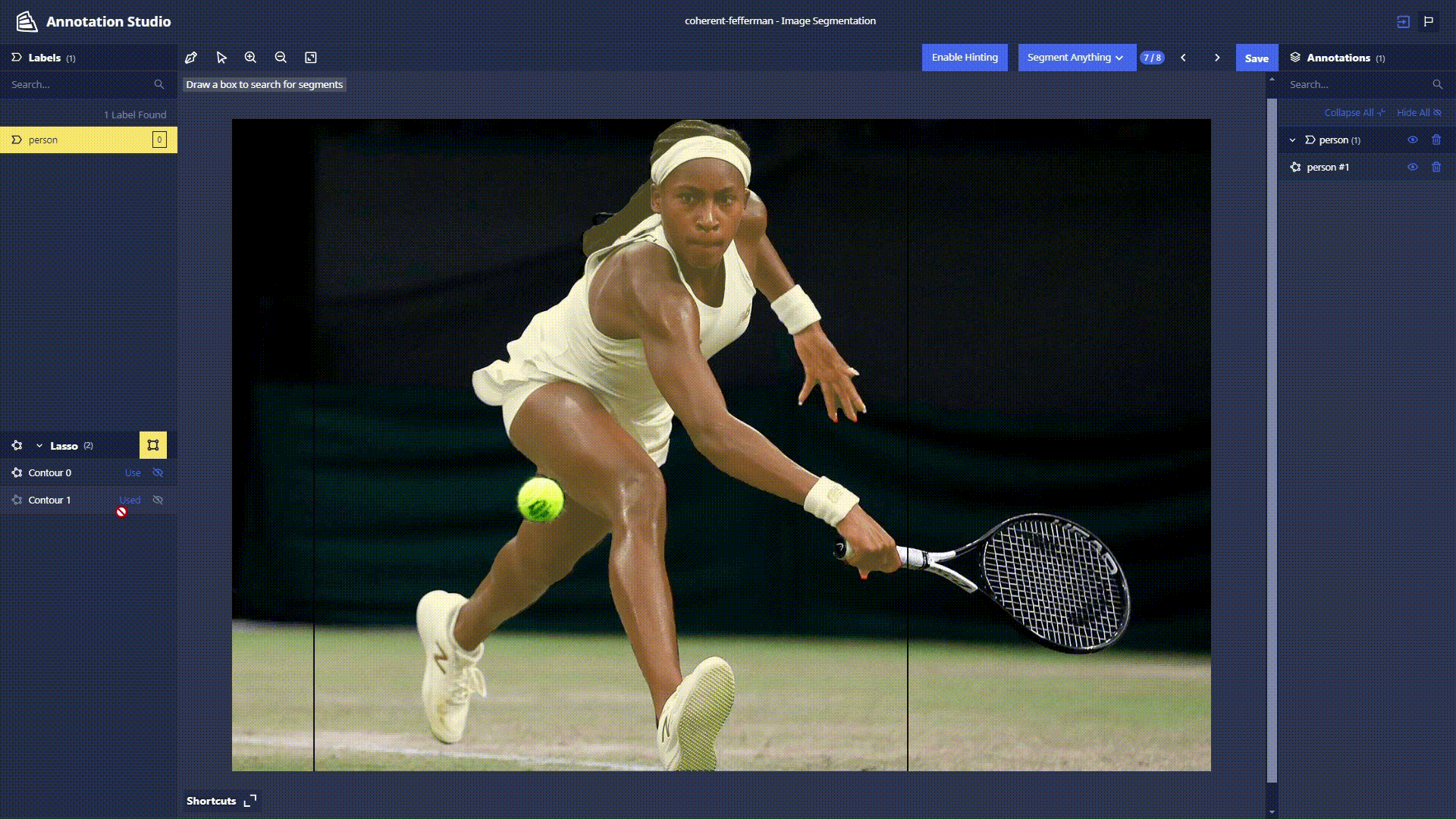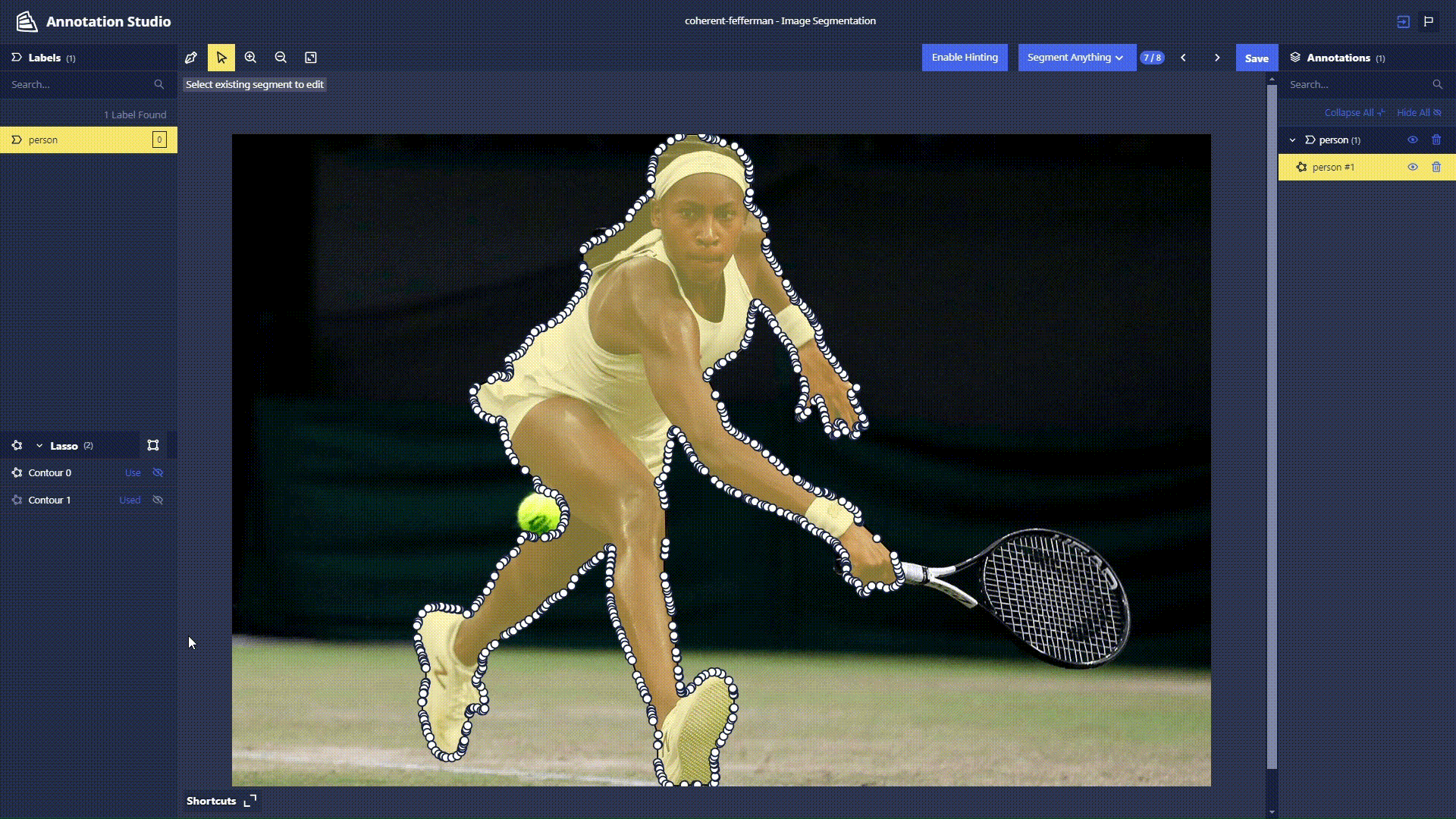
-
Polygon Splitting: When segmenting images using the Segment Anything Lasso Tool, objects that are required to be labeled separately may get segmented as a single entity. To split a polygon, users can select a starting point and click on the scissors icon to initiate the split. Users can then choose additional points within the polygon and select a final point to complete the split.
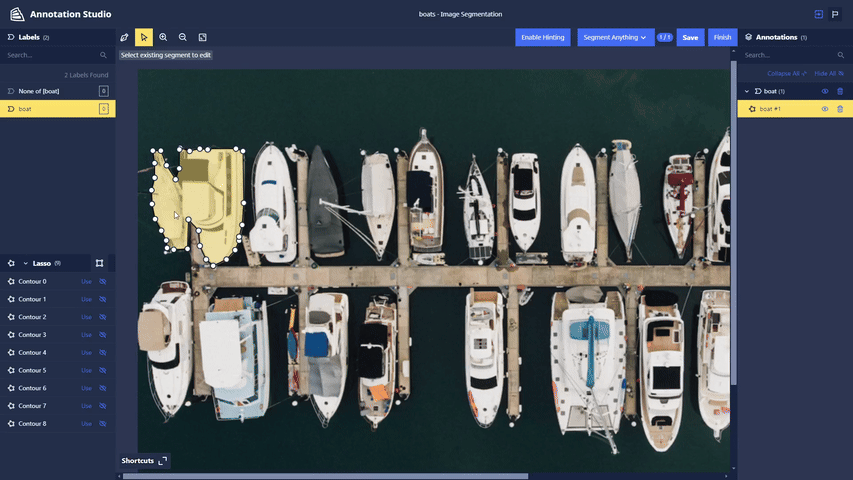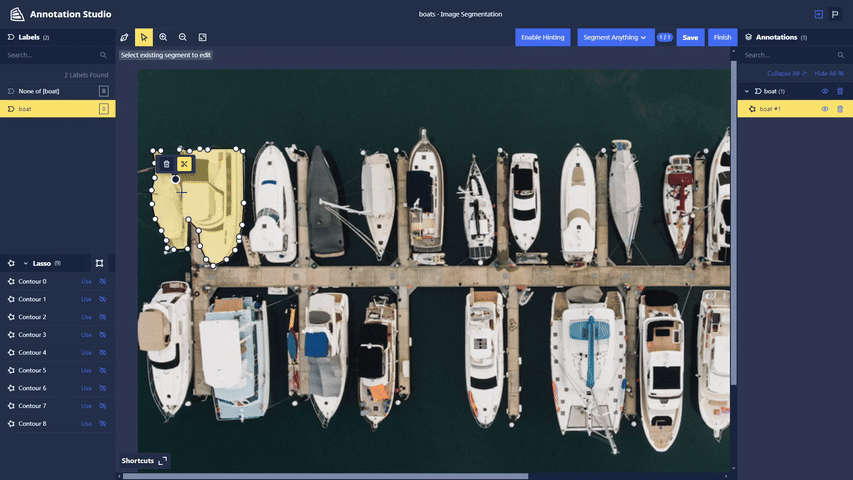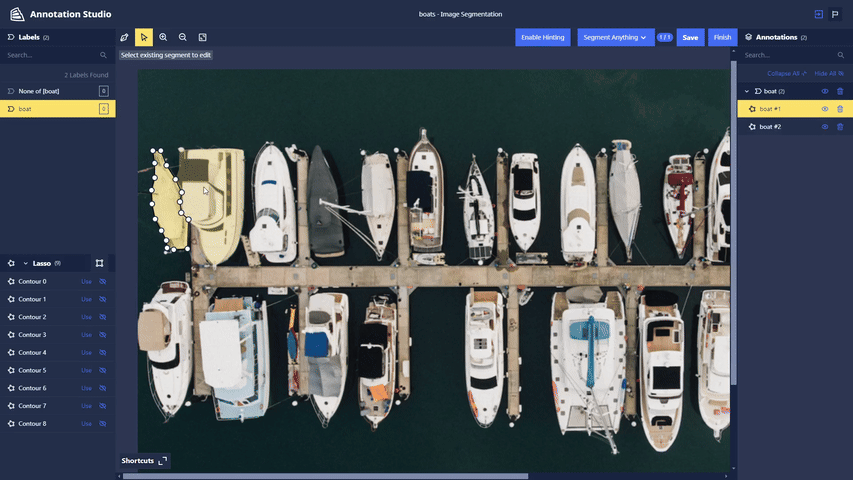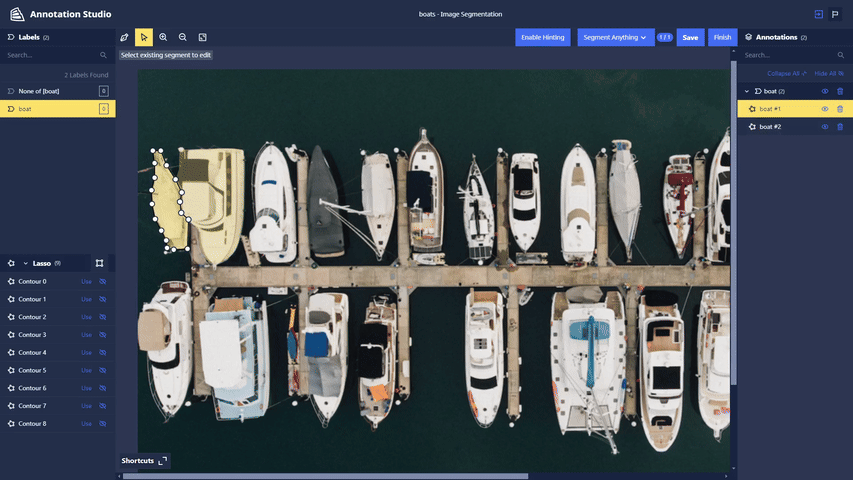
-
Secrets Manager: Users can now securely manage sensitive information, such as API keys, passwords, tokens, and certificates, with Chariot's Secrets Manager. Creating and managing secrets is possible directly from the Secrets tab on the Project Details page. At present, secrets can be retrieved exclusively through the APIs, but there are plans to integrate this functionality more extensively in the UI. For further details, refer to the user guide here.
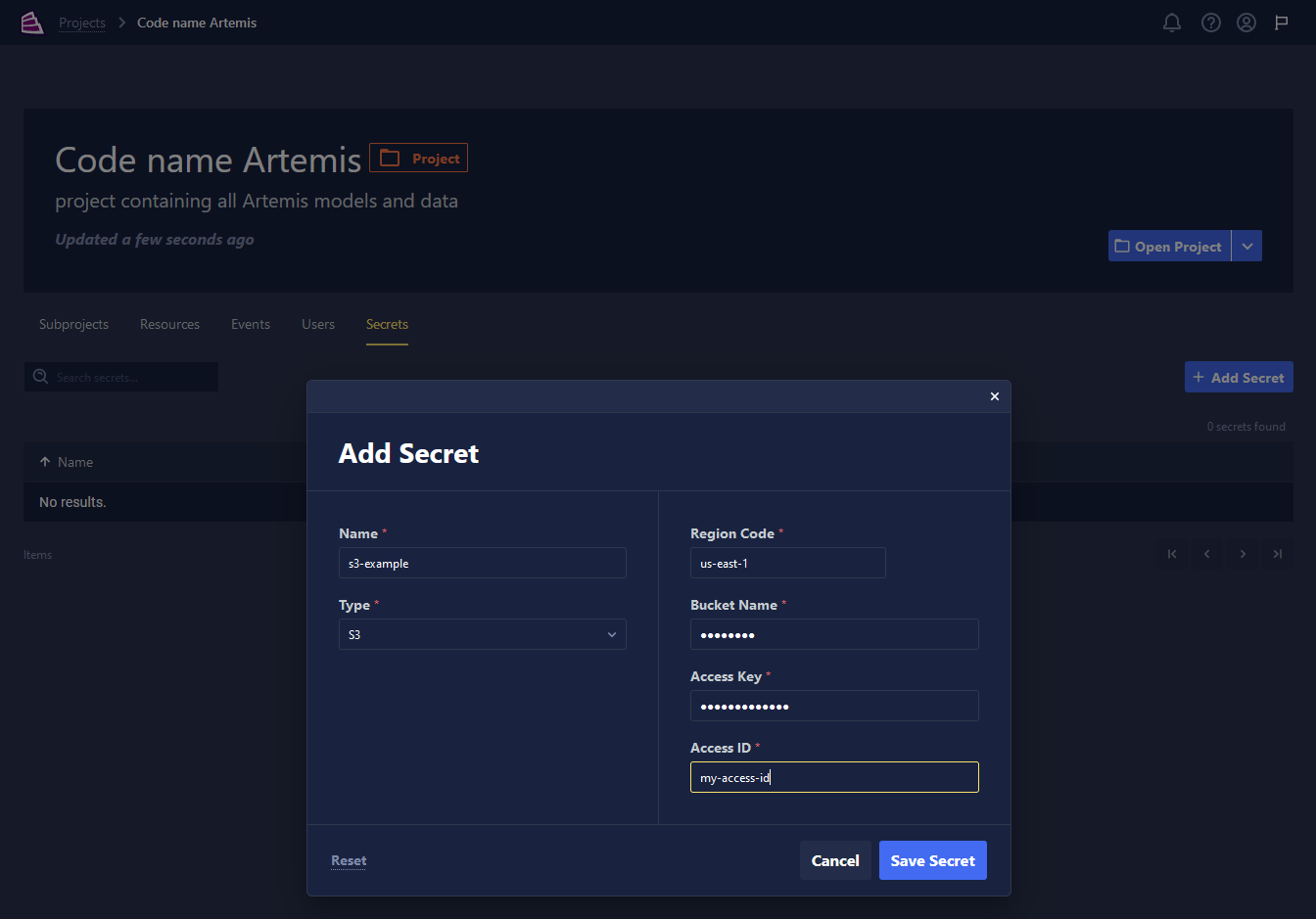
-
Training Blueprints: The example Blueprint provided to users now includes enhanced local testing code, enabling faster iteration in the Blueprint development process.
-
Archived Views: In order to reclaim resources, archived views and snapshots that have been in the archive for one week or more will now be periodically deleted. Note that views with snapshots with associated files will not be deleted until those files are also deleted.
What's Fixed
- Fixed issue where an inference server would encounter errors on new inferences after being shut down and restarted via the SDK
- Fixed issue with training runs having the same name and version
- Fixed issue with "point in time" selection being cut off of the screen when creating a snapshot
0.11.0 - August 5, 2024
What's New
-
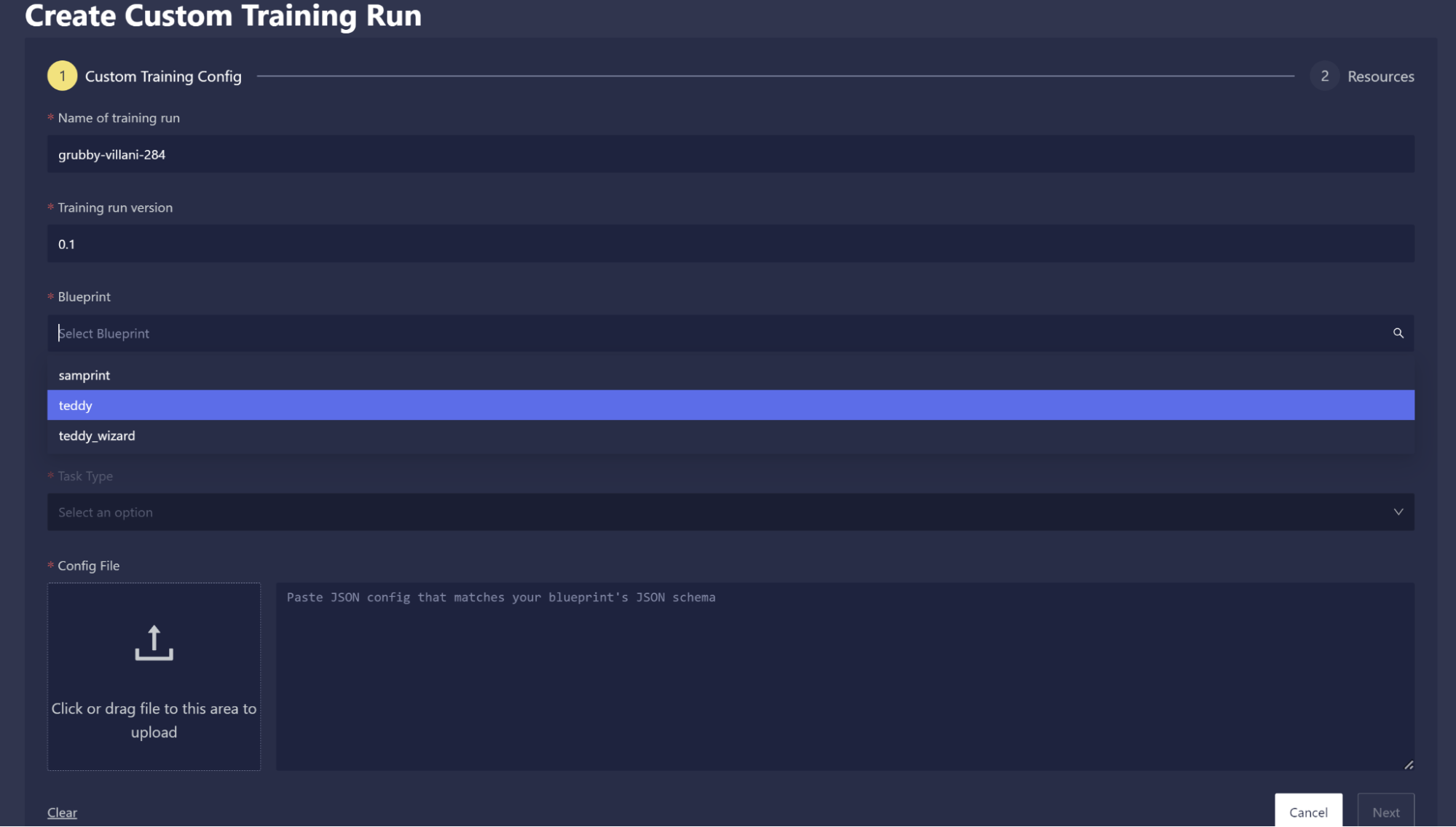
Training Blueprints: Through a new feature called Blueprints, users now have a flexible way to define their own training frameworks to train models in Chariot. To assist users in building their own Blueprints, we provide The Blueprint Toolkit, a Python library that helps users build, test, and deploy Blueprints. For an example Blueprint and step-by-step instructions, see the Chariot User Guide.
-
Users can train a model using their own Blueprints. There are two ways to do so: through the SDK, and through Chariot's UI. In the UI, select the Use Blueprint (custom configuration) option in the Training Run Wizard.
-
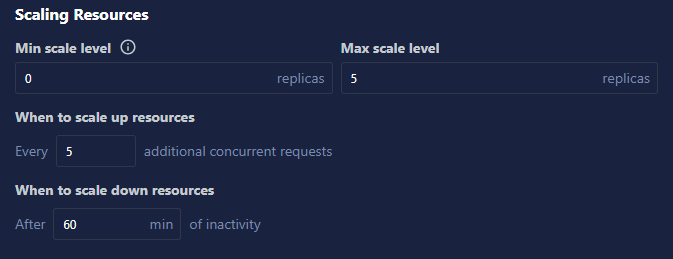
Inference Server Scaling Settings: When creating an inference server, users can now configure the minimum and maximum number of replicas that will be created when that inference server is active. Additionally, users can now configure, on a per-model basis, how long to wait before scaling down resources and at what level of traffic resources should be scaled up, enabling more precise management of inference servers and compute resources.
-
Users can now see how long a training run took to complete in two places
- The training runs list page
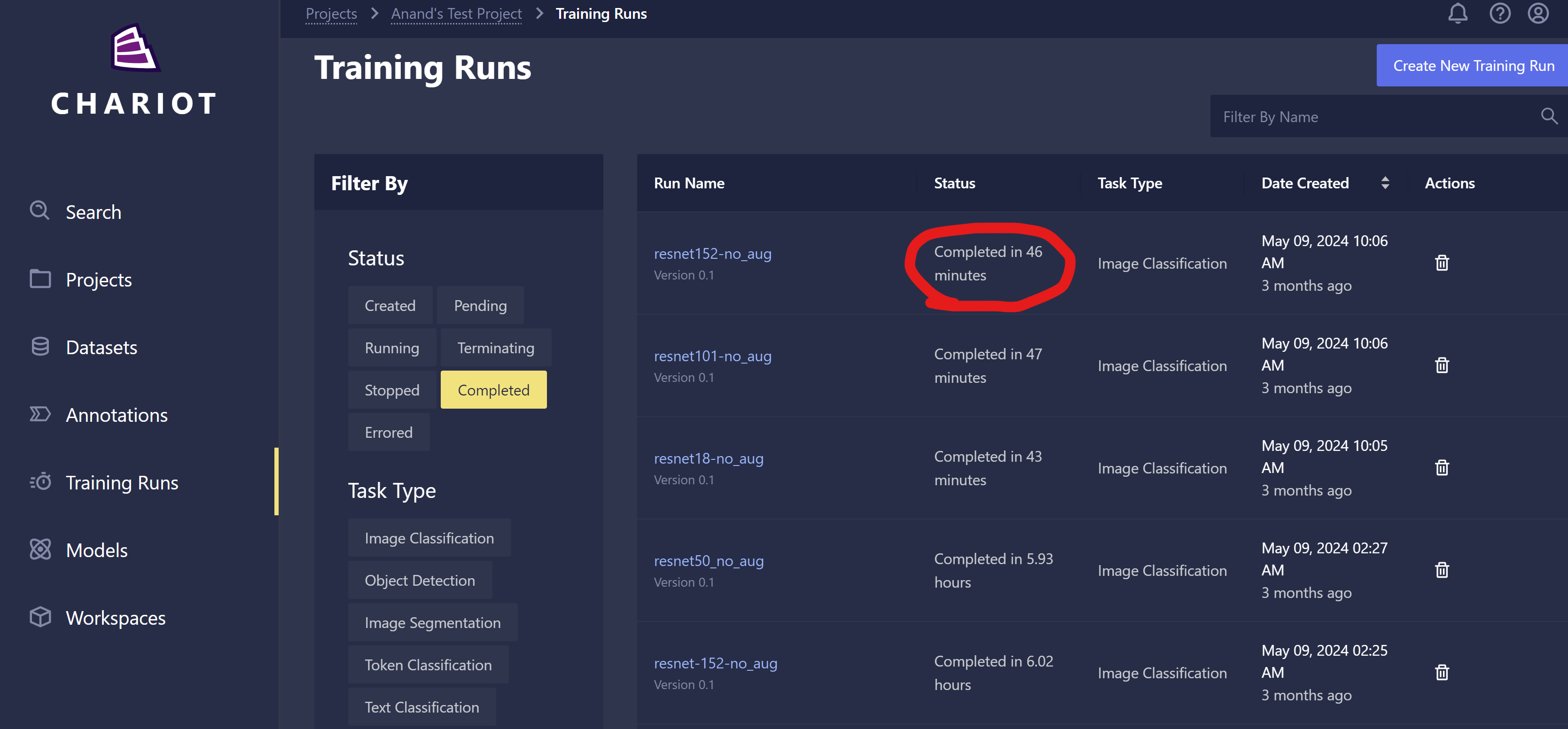
- The Details tab of each training run
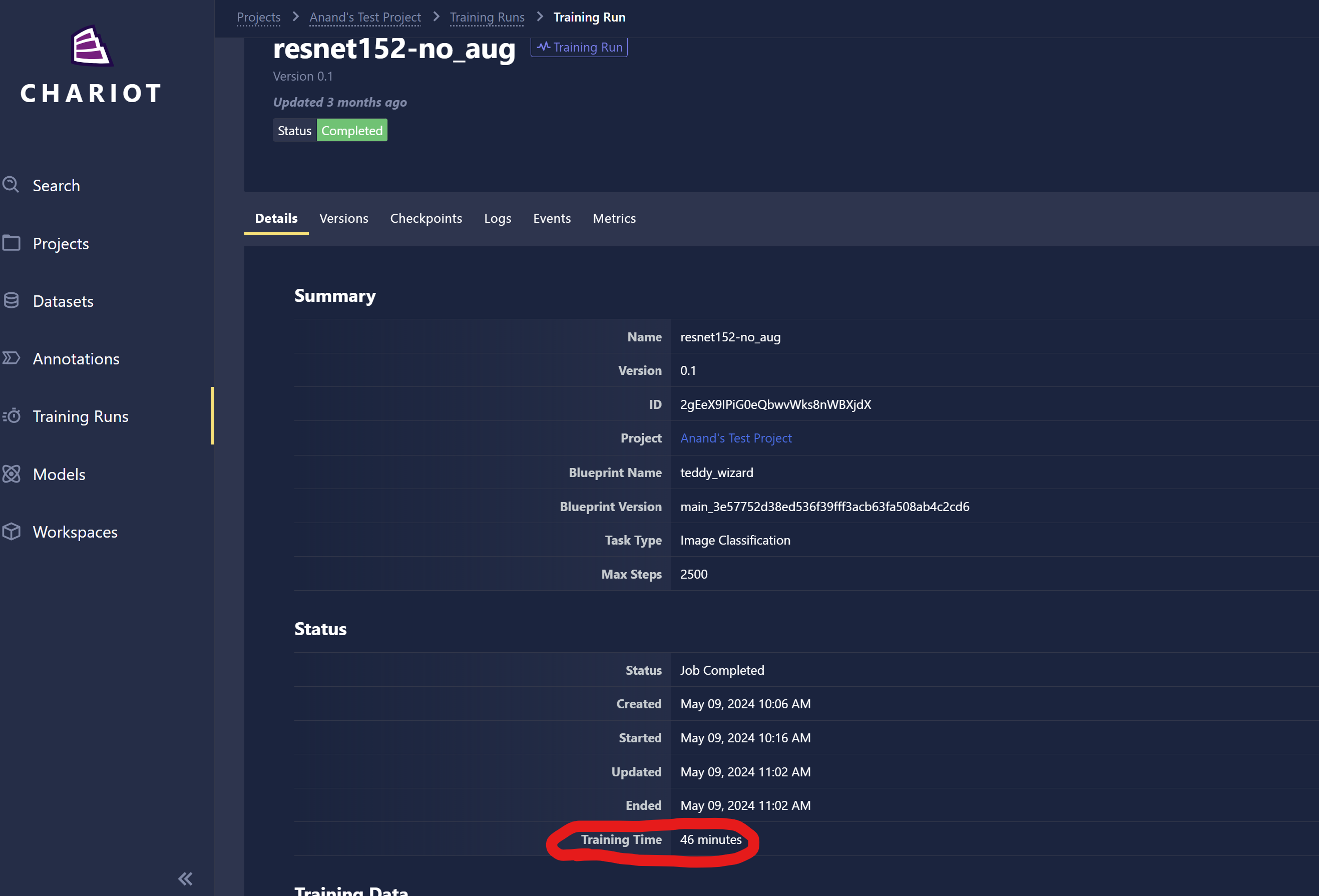
- The training runs list page
-
Users can now choose whether or not to push metrics to Valor for model evaluation when setting up training runs in the UI.
-
Keyset pagination is now allowed as an alternative to offset pagination on the POST
datasets/{datasetId}/getDatumsand POSTsnapshots/{snapshotId}/getDatumsendpoints. Keyset pagination is faster in most cases and should be preferred if random access is not required. -
Users can now provide metadata with individual datum uploads ("type":"datum") by including metadata in the POST
datasets/{datasetId}/uploadsrequest body. -
The datum metadata "SourceFile" key is now auto-populated based on the "Content-Disposition" response header or URL path when a user uploads individual datums ("type":"datum") with source URLs.
-
SHA-256 signatures are now returned with each datum from the API and SDK.
-
Users can further filter snapshots with a list of snapshot IDs at endpoints GET
/snapshots, GET/datasets/{datasetId}/snapshots, and GET/views/{viewId}/snapshots. Snapshots returned can be sorted by ID. -
Users can further filter views with a list of view IDs at endpoints GET
/views, GET/datasets/{datasetId}/views, GET/views/count, and GET/datasets/{datasetId}/views/count. Views returned can be sorted by ID.
What's Fixed
- We fixed an issue where models belonging to an undefined project did not show up as an option for hinting models.
- We fixed an issue where using a project name to retrieve a model through the SDK returned an error.
- We fixed an issue where inference servers errored with an Ultralytics detection model.
0.10.1 - July 9, 2024
What's New
- Training runs now report the total time taken to complete and the time taken to find appropriate resources and start training.
What's Fixed
- Fixed an issue with the chariot-client Python library that caused the
Model()constructor to throw an errant exception. - Fixed an issue of users not being able to catalog models from certain checkpoints of training runs that were created from an older version of the Teddy Blueprint
0.10.0 - July 3, 2024
What's New
- Inference store retention policies can now be set from within the Chariot UI.
- Inferences created by inference jobs will now be sent to the inference store, where they can be viewed.
- Users can now add inference data in the inference store to new or existing datasets.
- When uploading a dataset, users can specify a metadata file to provide metadata to corresponding images and text. For more information, check out the dataset metadata format documentation.
- Added the ability to download an entire dataset instead of being limited to a single snapshot.
- For datums in a dataset, source file names and file extension types are now automatically stored as metadata.
- Added support for uploading "enhanced deflated" .zip files.
- Improved the clickable area of the bar graph on the Datasets page.
- The Chariot software version number can now be found in the Chariot UI and will be auto-populated when submitting a bug report or feature request.
What's Fixed
- Fixed an issue with the resizing status of a workspace not being updated correctly once a resize is complete.
- Fixed an issue with the display of inconsistent metrics for inference jobs.
- Fixed an issue with the try-it-out function failing to read responses from segmentation models.
- Fixed an issue with the Manage Resource page failing to render in some circumstances.
- Fixed issues with some parts of the Chariot user documentation not correctly returning in search results.
Deprecation Warnings
max_batch_sizeandmax_batch_delaysettings for model inference servers have been deprecated and will be removed in the next release.
0.9.0 - May 31, 2024
What's New
- Datasets V3: A major upgrade to our Datasets functionality now makes it easier than ever to perform exploratory data analysis and create persistent views of specific data subsets, helping you track changes and maintain the integrity of your datasets over time. For more details, check out our documentation on Chariot Datasets. Because datasets v3 has a different api from v2, the prior datasets sdk functions have been moved from
chariot.datasetstochariot.datasets.v2(some functions have also been removed as the v2 apis have been transitioned to read-only). To interact with the new version, use the functions underchariot.datasets.v3instead. - DeepSparse inference engine selection is now restricted to non-GPU enabled nodes to optimize performance.
- We've improved recommendations to ensure that training runs have a higher success rate of being scheduled.
- We've added new configuration options to better manage inference server scalability. Currently, these options are accessible only via the SDK and API; functionality through the UI will be available soon. These new settings include:
- Minimum Replicas: The minimum number of server instances to run.
- Maximum Replicas: The maximum number of server instances that can be scaled up to.
- Scale Down Delay: The time delay before scaling down the server instances.
- Scale Down Metric and Target: Metrics and targets that trigger scaling down of server instances.
What's Fixed
- We've fixed an issue where changing a single label on a datum resulted in two labels. Now, only the new label is present.
Deprecation Warnings
- Datasets V2 is now read-only. A small number of datasets could not be migrated automatically from Datasets V2 to the new Datasets V3 and therefore require manual intervention by the Striveworks support team. To migrate these datasets, the Striveworks support team will reach out to the owner of the dataset to go over migration options. If you see any issues with migrated data or have not been contacted by support and feel that you should have been, create a support ticket via our Help Center or contact your local Chariot admin. Datasets V2 APIs will be removed in Chariot 0.10.0 release, currently planned for June 14th.
0.8.0 - May 9, 2024
What's New
- For supported models, users can now optionally select the inference engine when creating inference servers. Specifically, Chariot models support the option to run using Neural Magic's Deepsparse, providing a 3x-8x increase in model throughput compared to using PyTorch.
- The "Custom Config" option for training now allows manual tweaking and re-submitting of any config copied via the "Copy Training Config" button.
- Security enhancement to deny service accounts by default unless added to an allowlist.
- When there is a training run error, the user is redirected to the Events tab instead of the ephemeral Logs tab, giving a better indication of the cause of the error.
- Added pod-to-pod TLS for Chariot's back-end services.
- Removed graphics from the logging page that slowed some browsers.
- Annotation Studio now caches upcoming images, reducing load times seen by users when requesting the next image.
- Performance increases to model drift API calls by switching from synchronous to asynchronous requests.
- When training NLP models, "add special tokens" is turned on by default.
What's Fixed
- Delete model's inference store data on model deletion.
- Fixed differing architecture strings in the Model Catalog.
- Fixed issue with YOLOv8 XL models crashing due to a resize error when fine-tuning.
- Fixed issue requiring a user to have write access to a dataset to be able to use it for model training.
Deprecation Warnings
- In the next release of Chariot (version 0.9.0), Datasets V2 will become read-only. A migration will be performed to automatically migrate the latest version of most datasets to the new Datasets V3 service. We will not auto-migrate the entire history of each dataset. There may be a small number of datasets that cannot be migrated automatically and will require manual intervention by the Striveworks support team.
0.7.0 - April 19, 2024
What's New
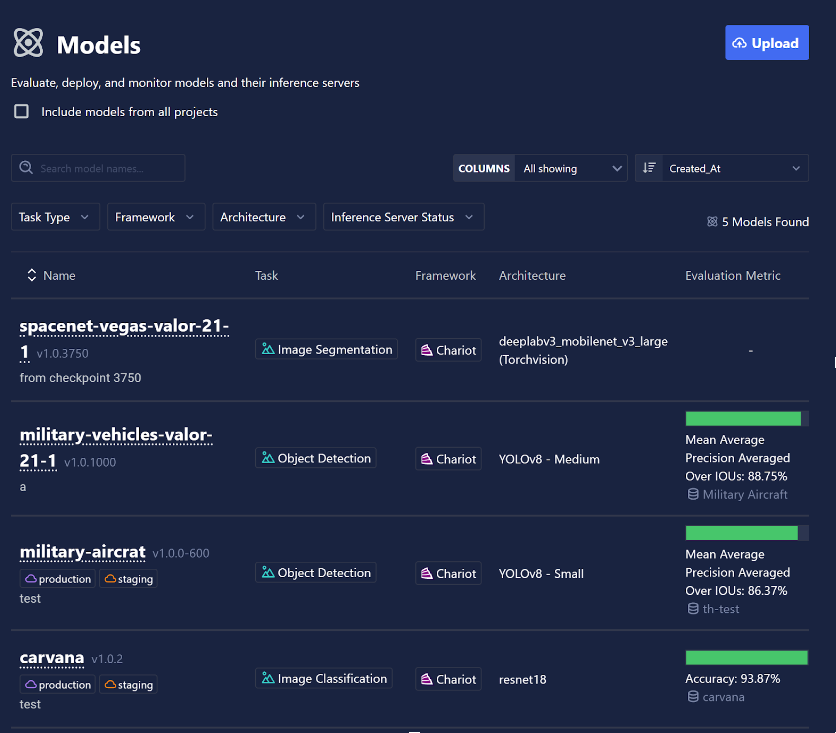
- Model performance metrics, now powered by Valor. Metrics are included in the model's Catalog View. Additional details are available when navigating to the model itself.
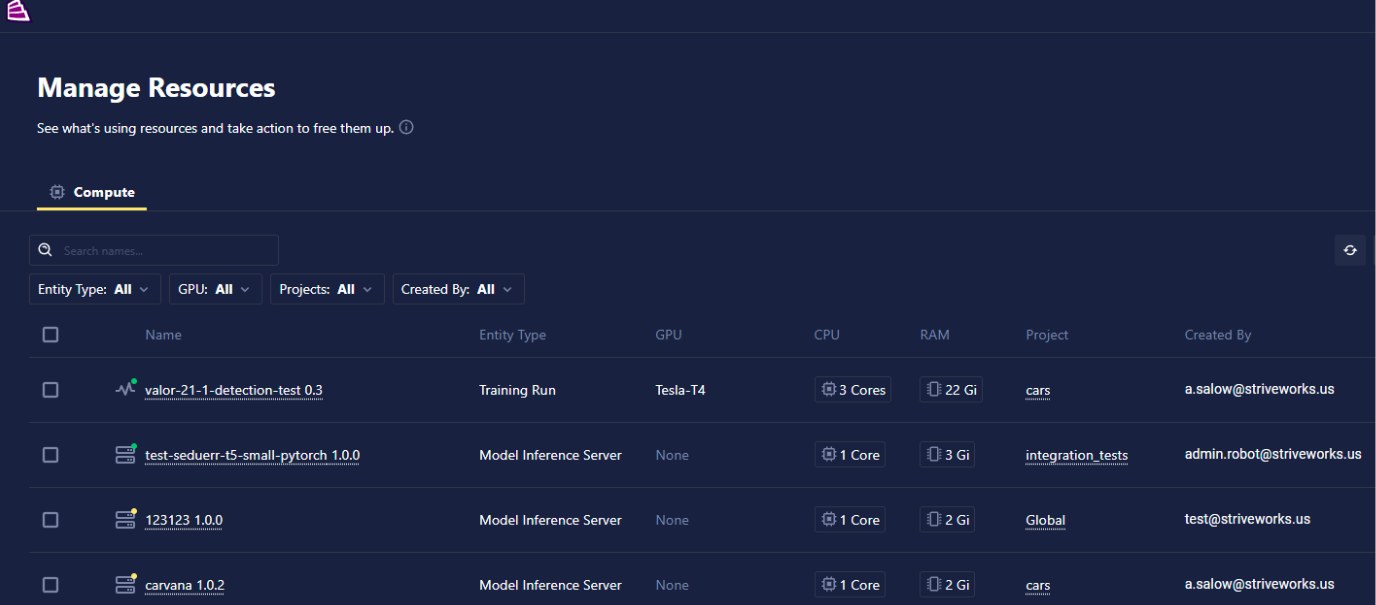
- New "Manage Resources" tab to view compute resources of user-created Chariot entities — Model Inference Servers, Notebooks, and Training Runs.
- Python SDK now supports model drift detection monitoring.
- Added storage sampling settings to enable users to set a sampling percentage of inferences to be saved to the inference store (Currently available via Chariot SDK).
- Annotation Studio now supports using the mouse wheel to scroll to zoom and click and drag to navigate the image.
- Added more granular statuses for GPU resources.
- Google/GKE resource support has been added.
- More robust and secure credentialing for training service.
- New Documentation link fields added to Blueprints (summary, documentation, icon, repo).
- Re-added a copy config button for training runform.
What's Fixed
- Adjusted logic in filters to properly filter on GPU type (was not able to filter on GPU due to Regex test against "undefined" value).
- Fixed an issue where CPU was calculated as gigacores vs. millicores.
- Fixed a round-down error in resource suggestions.
- Fixed an issue where multiple banners were being generated indicating that the user had been signed out.
- Fixed an issue where datums might appear on multiple lines in the annotations file of downloaded dataset archives.
- Fixed an issue where the drift detection service wasn't able to access models in the global project.
- Fixed an issue where some projects would fail to load the Model Catalog with the error: "converting NULL to string is unsupported."
- Fixed parsing YOLO model architectures.
- Fixed an issue for getting model stages for some models.
- Added CLAHE parameters to model config for CV configs.
- Fixed an issue where metrics were not being deleted when a training run was deleted.
Deprecation Warnings
- The model recommender API has been deprecated and will be removed with the next release.
0.6.0 - March 26, 2024
What's New
- More configurability when serving LLMs! Hugging Face inference servers now accept keyword arguments (kwargs) for increased customization of model serving settings.
- The Chariot Inference store has numerous What's New and improvements.
- Search for inferences by class label.
- Specify retention policies to automate clean up of inference data, controlling storage use.
- For object detection and image segmentation models, choose whether or not to store all requests sent the model or only those who's output contained a non-empty list of detections or segmentation masks.
- Batch drift detection with two drift metrics supported, KS (Kolmogorov Smirnov) and CVM (Cramer-von Mises)
- Notifications now persist in a notification inbox.
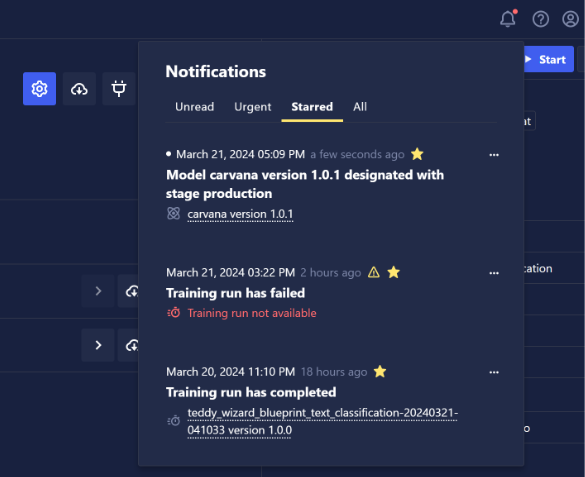
- User documentation is now searchable.
- Improvements in suggestions and validations of resources when creating compute jobs throughout the platform.
- Improved UI for the Chariot models catalog.
- Implemented checkpoint blob garbage collection for deleted runs and checkpoints.
What's Fixed
- Various bug fixes related to creating annotations within Chariot.
- Fixed an issue with Hugging Face servers loading models multiple times, resulting in 2-3x the expected memory being used.
Deprecation Warnings
When calling inference methods from the Chariot SDK, some kwargs, such as "predict" and "detect", have been renamed. Specifically include_metadata has been changed to return_inference_id and inference_store_values has been changed to custom_metadata.
0.5.0 - February 22, 2024
What's New
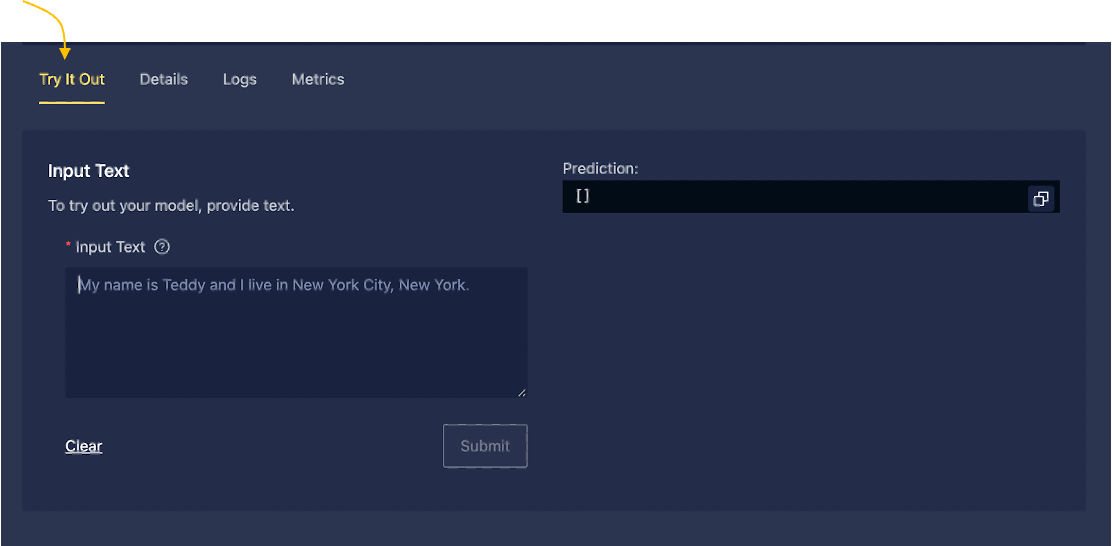
- Models Page: The Try It Out function, where inferences run through the UI, now supports PyTorch models.
- Inference Server Creation Wizard: A new validation check verifies that the user-requested GPU and memory resources are available for the inference server.
- Inference Server Creation Process: A new validation check verifies that a model has been successfully uploaded for inferencing. An error message with remediation advice is displayed when there is an upload issue with the model.
- Training Runs Page: A new Events tab provides more precise descriptions regarding the state of a training run. See the example image below.
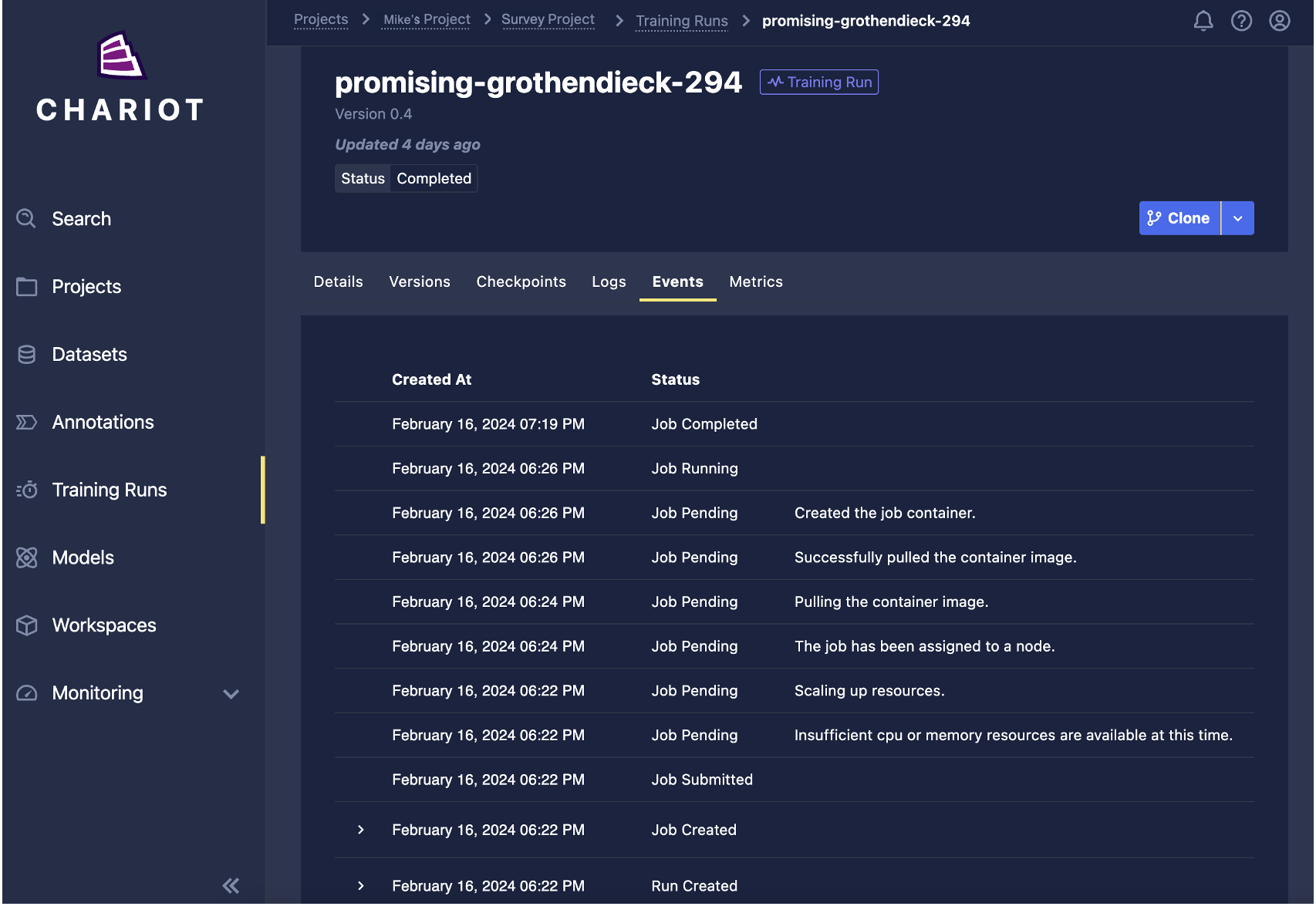
- Model Training: Chariot now defaults to using Training V2 API endpoints. As a result:
- Training V2 SDK functionality is now available in chariot.training_v2.
- Existing Training V1 runs and related data will be migrated to V2 at the time of the upgrade.
- Training V1 is still available, though it is read-only. If you require access to V1 data, you can still use the API. For example, you can use Workspaces or other code you've written using the SDK.
- Migrated runs will indicate an Unknown status on the Training Runs page.
What's Fixed
- FIXED: When deleting a model and clicking to confirm, no feedback is provided to indicate when there is an error or issue with the deletion request; the confirmation page appears frozen.
- FIXED: The Details tab on the Training Runs page has missing labels to indicate the weights from previous training runs.
- FIXED: The Annotation Studio fails to open for text classification annotation tasks.
- FIXED: The Workspaces Creation Wizard can fail when checking for GPU and RAM resources due to API gateway route configurations.
- FIXED: When creating a YOLO training run, the resize parameters for
min sizeandmax size, which aren't relevant to YOLO, are displayed. - FIXED: When selecting an existing YOLO model to fine-tune, the wizard does not provide the correct resize options of height and width.
- FIXED: Workspaces are continually assigned to the same GPU slice, instead of being assigned when applicable.
- FIXED: YOLO models exported to the model catalog display the incorrect model architecture prefix.
- FIXED: Cataloging a model fails, due to
taskandartifact typelabels submitted through the UI.
0.4.22 - January 8, 2024
Improvements
-
The Training V2 API is now available via Swagger and the SDK. See V1 Deprecation Warnings below and in SDK docs.
-
You may find SDK documentation for Training V2 here: https://%%CHARIOT-HOST%%/docs/sdk_api_docs/chariot.training_v2.html
Bug Fixes
- Chariot documentation: Eliminate the need to hard refresh the browser after an upgrade.
- Workspace names are now required to be unique.
- Better error handling messages, tooltips, and updated iconography to improve the user experience when encountering UI issues.
Deprecation Warnings
- The Training V1 API is scheduled for deprecation in the next release (0.4.23).
- The Training V1 API will become read-only.
- You are encouraged to migrate any existing functionality using V1 (e.g. SDK) to the new Training V2 API.
- Training V1 data will be automatically migrated to V2 on the next release. Original V1 data will remain for a period of time as read-only.
0.4.21 - December 14, 2023
What's New
Models
- New task type for automatic speech recognition to support Hugging Face Auto Speech Recognition Models.
What's Fixed
Python SDK
- Issue prevents inference for some scikit-learn models. Now fixed.
Annotation Studio
- Large bodies of text are truncated in the UI during annotation. Now fixed.
0.4.20 - November 30, 2023
What's New
Annotation Studio
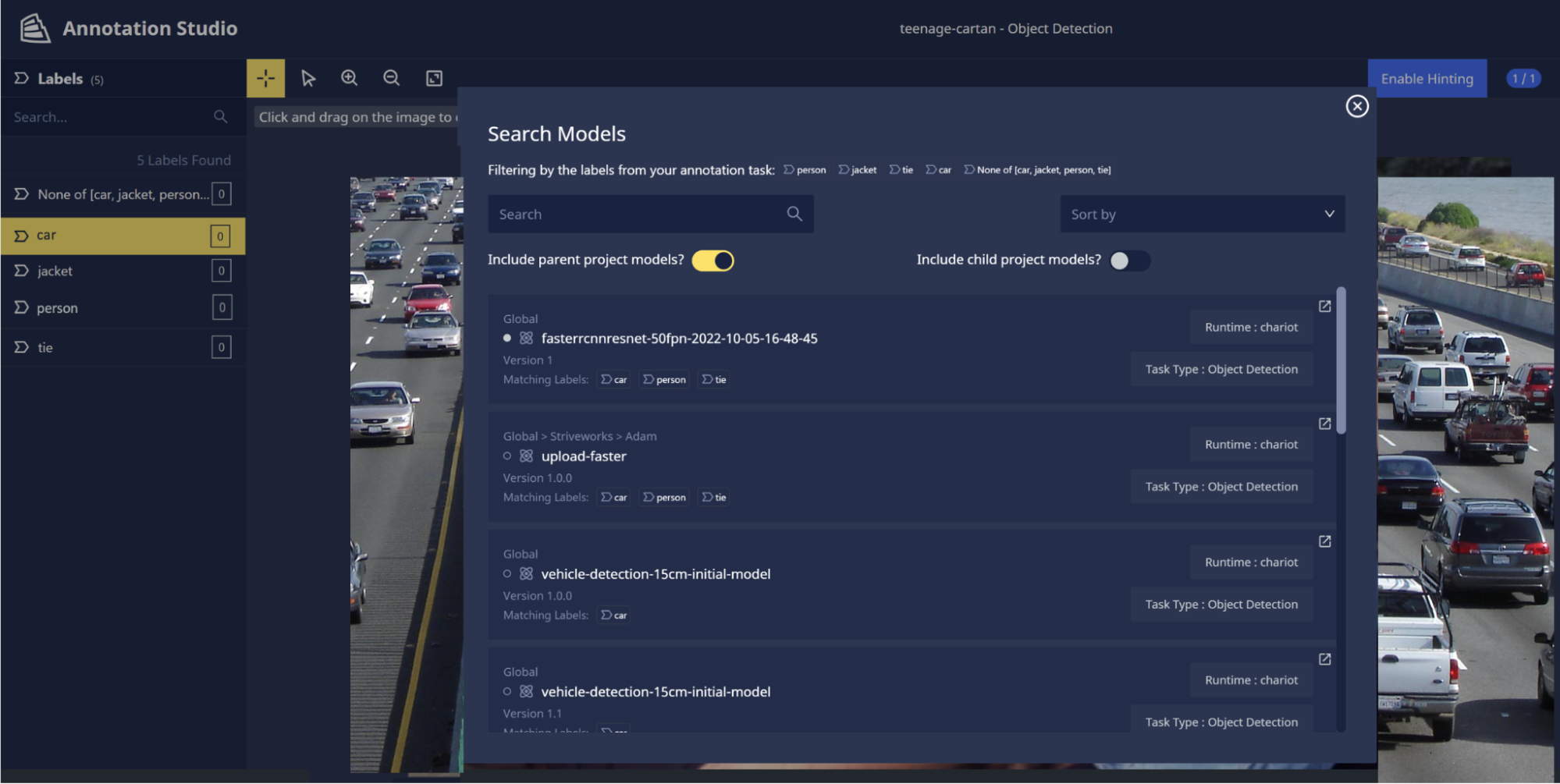
- Previously, selecting models for hinting occurred when the annotation task was created, and only one selection was allowed. Now, models for hinting can be selected or changed from within Annotation Studio. Additionally, the model selections are filtered to present only those that contain class labels relevant to your annotation task:
Performance and experience enhancements
- The object detection default batch size has been lowered to reduce "out of memory" errors.
- The Annotations hotkeys modal can now be collapsed so that it does not visually interfere with images being annotated:
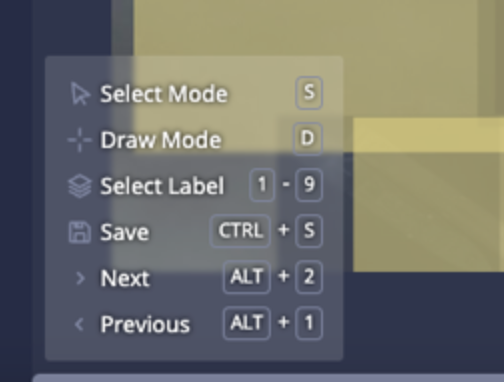
- Chariot Release Notes are now included in the UI help menu:
What's Fixed
- Training runs using multiple datasets fail with error:
RuntimeError: Trying to resize storage that is not resizable.Now fixed.
0.4.19 - November 16, 2023
What's New
Negative sample support
- Annotations for Object Detection and Token Classification now support the ability to mark a datum as a "negative," meaning that it contains no detections of entities and can now be optionally included in the training manifests. See UI help documentation for details.
Monitoring
- The Chariot Monitoring dashboard has been updated to provide more robust monitoring details through two new pages for "Inferences" and "Inference Servers." These pages help you to understand how production models are performing and to monitor inference server health. See UI help documentation for details.
Chariot SDK support for artifacts from the Inference Store
- The Chariot SDK now supports creating artifacts (compressed bundles of data) from data stored in the Inference Store. Artifacts can then be downloaded as tar files from the Inference Store and uploaded to the Chariot datasets service for creating new datasets. The new datasets can be further iterated on or used right away to create new training runs.
Asynchronous processing for long-running tasks
- The processing of long-running tasks issued from the Chariot SDK, such as deleting large amounts of data from the Inference Store or creating artifacts, is now asynchronous. In addition, when a long-running task is issued, a job ID is immediately returned. The ID can be used to query for the job and to check its stage of completion.
Platform streaming support for token classification datasets
- Production-scale datasets for token classification can now be directly streamed from the Chariot Data Store into the Chariot Training Service, reducing the resources required to execute a training run.
Inference Server progress bar
- The Inference Server progress bar now provides enhanced details when scheduling and starting Chariot inference servers. For example, when initializing, the container status displays:

What's Fixed and Updates
What's Fixed
- Chariot UI: tar file upload failures for Hugging Face models. Now fixed.
- YOLO training of batches without objects (negative samples) resulted in irrevocable model updates. Now fixed.
- Unable to submit a bulk inference job when "Evaluate Metrics" is disabled. Now fixed. ● Workspace could not attach to a "GPU Type." Now fixed.
- Validation errors in cloned training run due to "Training Datasets Batch Size." Now fixed. ● The "Labels" field for text token classification annotation jobs is not automatically populated when selecting a dataset that has existing token classification labels. Now fixed. ● A Workspace in hibernation mode cannot be opened again without manually stopping and restarting the session. Now fixed.
- Workspace did not scale up due to availability zone preference. Now fixed and Workspaces in cloud environments with availability zones scale up agnostically.
Updates
- Hugging Face update to 4.35.0, and models now saved as model.saftetensors
0.4.18 - Novemeber 3, 2023
This release consisted mainly of minor enhancements and bug fixes.
0.4.17 - October 25, 2023
What's New
Model Catalog
- Five new YOLOv8 models (nano, small, medium, large, and extra large) pre-trained on COCO are now included with Chariot. Fine-tuning of these models is supported via the SDK and Chariot UI. These models are ideally suited for real-time object detection tasks and can be trained and fine-tuned on your custom datasets.
Workspaces
- A progress bar is now displayed to indicate startup progress when you create a new workspace.
Additionally, any errors that occur during the startup process are displayed so that you can remediate accordingly.
Example:


0.4.16 - October 10, 2023
This release consisted mainly of minor enhancements and bug fixes.
0.4.15 - September 12, 2023
This release consisted mainly of minor enhancements and bug fixes.
0.4.14 - September 6, 2023
This release consisted mainly of minor enhancements and bug fixes.
0.4.13 - August 25, 2023
What's New
Annotations
- Hints are now available in the UI for text classification and text summarization tasks. Note: unlike hints for image annotations, in which Chariot can optionally learn from your annotation inputs, hints for text annotations are currently "static," meaning that they are pre-derived and Chariot does not learn while you label.
Model Catalog
- Four new Hugging Face task types are now supported:
Text2TextGeneration,TextSummarization,Feature Extraction, andQuestion Answering NLP. - Two Hugging Face language models for text generation are now included with Chariot and available through both the SDK and UI:
google/t5-large-flanandt5-large. - The Ultralytics
YOLOv8model has been integrated with Chariot for training through the SDK (UI support is forthcoming). The resulting trained model can be uploaded to the Model Catalog, through the SDK, and served from either the SDK or UI.
Datasets
- Performance enhancements provide faster time to results when querying multiple datasets using the SDK.
Inferencing Ingestion
- 20% increase in ingestion speed.
Model Catalog
- Model names are more flexible now and not restricted by RegEx patterns.
- Parameter efficient, fine-tuned Hugging Face models with sharded PyTorch weight files can now be uploaded into the catalog.
Training Configuration
- Data Augmentations and Color Transformations can now be individually selected:
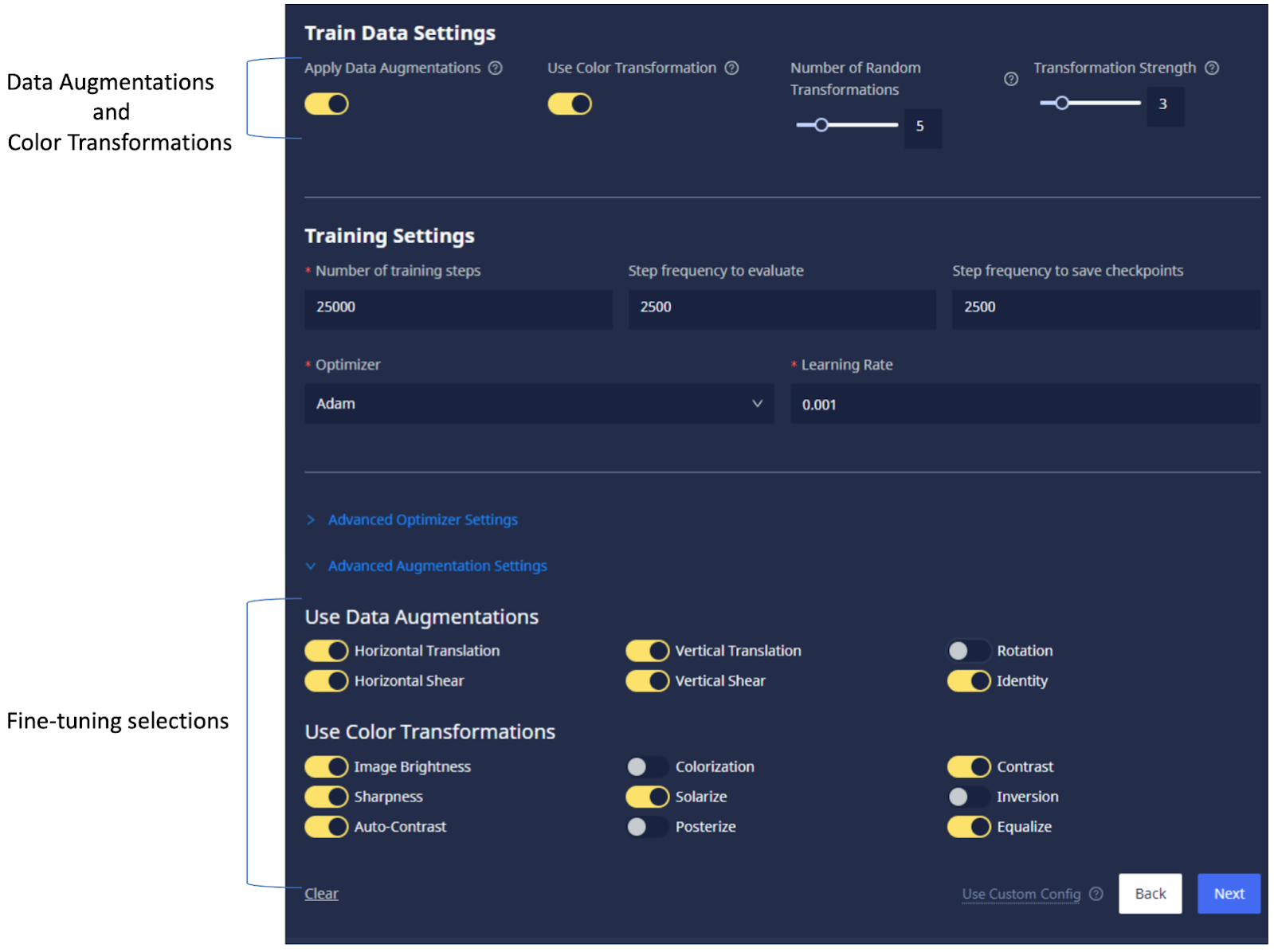
Model Recommender
- Performance enhancements provide improved application stability for the Recommender.
Known Issues
Inference Servers
- After upgrade, all existing inference servers must be shut down and restarted to pick up the new inference image. Otherwise, SDK calls to the inference server may fail with a runtime error.