Inference Store
The inference store is a collection of services responsible for listening for, and indexing data of, inference events, enabling querying of inferences, and managing retention policies for inferences. It enables storage of production data running through your models and facilitates rich metadata querying of the data and associated inferences.
How It Works
A core component of the Chariot platform is a model. Chariot supports models of various task types that span the domains of computer vision, natural language processing, and tabular data. In order to serve, or provide an endpoint to access these models, Chariot allows users to create inference servers with a variety of settings. One of these settings is the ability to store inferences.
In the simplest form of model serving, a request to a model will look like:
Roughly: client -> inference request -> inference server -> inference response -> client
When inference storage is turned on, an intermediate proxy is inserted to further process and save inference request inputs and outputs.
Roughly: client -> inference request -> inference-proxy -> inference server -> inference-proxy -> inference response -> client
The inference proxy service is the component that ultimately informs the inference store that an inference event has taken place.
Inference Request
A standard inference request in Chariot resembles the following:
{
"inputs":[
{
"data": [
"<base64 encoded data>"
],
"datatype": "BYTES",
"name": "try-it-out",
"parameters": {
"action":"predict"
},
"shape":[height, width, channels]
}
]
}
The data field holds the inference data that the inference server will infer upon. The parameters field holds the action that the inference server should perform on the data (usually conditional on task type). The parameters field also holds optional user-defined metadata that will flow to the inference store. An example is shown below:
{
"inputs":[
{
"data": [
"<base64 encoded data>"
],
"datatype": "BYTES",
"name": "try-it-out",
"parameters": {
"action":"predict",
"metadata": "[
{"key": "latitude", "type": "float", "value": "-32.1"},
{"key": "longitude", "type": "float", "value": "-43.2"},
{"key": "data_source", "type": "string", "value": "hallway-camera-feed"},
{"key": "organization", "type": "string", "value": "striveworks"},
{"key": "group", "type": "string", "value": "team-remediation"},
{"key": "frame_number", "type": "int", "value": "987"},
{"key": "camera_position", "type": "json", "value": "{"angle": "10.5", "tilt": "1.6"}"}
]",
},
"shape":[height, width, channels]
}
]
}
This inference will then be queryable by any of the metadata key-value pairs that have been specified.
Inference Proxy
Inference requests are directed to the inference proxy when inference storage is turned on. The inference proxy introduces three core stages: pre-processing, predict, and post-processing.
The pre-processing stage includes the following steps:
- The inference request is accepted from the client
- The inference data (image, text, tabular row) is stripped from the request and placed in a temporary buffer
- User-defined metadata is stripped from the request and placed in a temporary buffer
The predict stage includes the following steps:
- Forward the inference request to the inference server and await a response
The post-processing stage includes the following steps:
- Compute and attach the data hash
- Upload the data to blob storage
- Upload the metadata to blob storage
- Upload the inference response to blob storage
- Publish an inference event
### Inference Event
The structure of an inference event is detailed below:
```golang
type NewInferenceStorageRequest struct {
// The id of the model that produced the inference
ModelID string `json:"model_id"`
// The id returned by the inference server/process
InferenceID string `json:"inference_id"`
// When the inference proxy accepted the inference request
RequestReceivedAt time.Time `json:"request_received_at"`
// When the inference proxy forwarded the inference request to the inference server
RequestForwardedAt time.Time `json:"request_forwarded_at"`
// When the inference response was returned from the inference server back to the inference proxy
RequestRespondedAt time.Time `json:"request_responded_at"`
// When the inference proxy published the inference event
EventPublishedAt time.Time `json:"event_published_at"`
// The internal storage url of the data file
DataStorageKey string `json:"data_storage_key"`
// The internal storage url of the inference file
InferenceStorageKey string `json:"inference_storage_key"`
// The internal storage url of the metadata file
MetadataStorageKey string `json:"metadata_storage_key"`
}
Using the Inference Store�
Chariot provides one-click inference storage. To enable this feature, navigate to the Advanced Inference Server view within the Chariot UI. Stored inferences will be displayed under the Inference tab within the inference server monitoring view. Several filters and buttons are available on that page to view inferences in more detail.
Enabling Storage
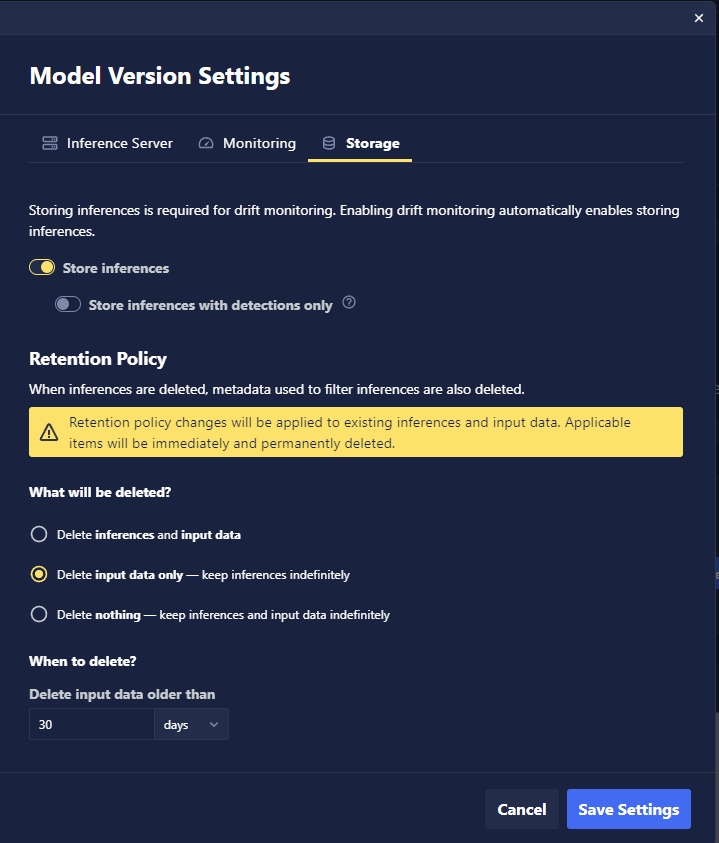
- UI
- SDK
Use the Storage tab in Model Version Settings to turn on inference storage. You can also specify how long inference and input data should be retained in the system. See Retention Policies for more details.
First, you must ensure that the model is registered for inference storage:
from chariot.inference_store import register
register.register_model_for_inference_storage(
request_body=register.NewRegisterModelRequest(model_id=model.id)
)
Retention Policies
Retention policies are used to manage the storage footprint for specific models. Retention policies allow users to set a maximum length of time to keep data for and to specify whether to clean up blob storage, the inference record, or both.
- UI
- SDK
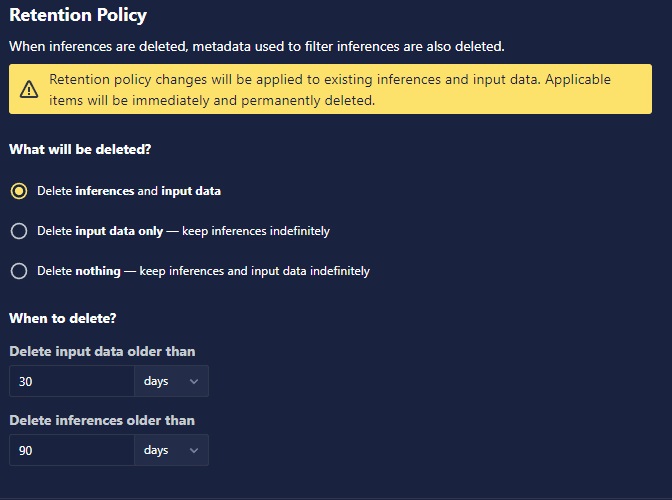
Select whether you want to:
- Delete both inference and input data after a specified time period. The retention period of inference data must be equal to or longer than the input retention period.
- Delete only input data after a specified time period and keep inference indefinitely.
- Keep both inference and input data indefinitely.
Each model will have only one retention policy, and when this policy is changed, it will be applicable to past and future inputs and inferences immediately.
Getting a retention policy for a model:
from chariot.inference_store import models, retention_policy, retention_task
retention_policy.get_retention_policy(model_id=model_id)
Creating a manual retention policy for a model:
# maximum_age and automated_interval are in hours. A value of 0 for maximum_age
# means 'delete immediately on manual requests'. A value of 0 for
# automated_interval indicates that this policy will be invoked manually and will
# not run on an automated interval.
new_retention_policy_request = models.NewRetentionPolicyRequest(
maximum_age=1, delete_records=True, delete_blobs=True, automated_interval=0
)
new_retention_policy = retention_policy.create_retention_policy(
model_id=model_id, request_body=new_retention_policy_request
)
Creating an automatic retention policy for a model:
new_retention_policy_request = models.NewRetentionPolicyRequest(
maximum_age=3, delete_records=True, delete_blobs=True, automated_interval=3
)
retention_policy.create_retention_policy(
model_id=model_id, request_body=new_retention_policy_request
)
Executing a manual retention policy for a model:
new_retention_task_request = models.NewRetentionTaskRequest(
dry_run=False, retention_policy_id=new_retention_policy.id
)
new_retention_task = retention_task.create_retention_task(
model_id=model_id, request_body=new_retention_task_request
)
Getting detail about a single retention task:
retention_task.get_retention_task(
model_id=model_id, retention_task_id=new_retention_task.id
)
Filtering a collection of retention tasks for a model:
retention_task.filter_retention_tasks(
model_id=model_id, request_body=retention_task.NewGetRetentionTasksRequest()
)
Metadata
One of the powerful features of the inference store is its ability to process, store, and query for metadata.
Metadata must be key-value pairs, where keys and values must be sent to the server as string, but values can be parsed based on their specified type. The supported specified types are integers, floats, strings, and nested JSON.
Metadata can be added to an inference in a couple of ways:
- Sending additional metadata with the inference requests.
- Posting metadata to an existing inference in the inference store.
Sending metadata with the inference request using the Chariot SDK:
from PIL import Image
from chariot.client import connect
from chariot.models import get_model_by_id
connect()
model = get_model_by_id("your-model-id")
image = Image.open(file)
# When using the SDK to request an inference, there is no need to specify the type of metadata. The SDK will infer for you.
medadata = {"a":"b", "c": {"d":"e"}, "1": 2, "3", 4.0}
result = model.detect(image, custom_metadata=medadata)
Creating metadata for an existing inference in the store:
from chariot.inference_store import metadata
metadata.create_metadata(
model_id=model_id,
inference_id=inference_id,
request_body=models.NewExtendedMetadataRequest(
key="image_chip_id", type="string", value="abc"
),
)
Retrieving metadata for an inference:
m = metadata.get_metadata(model_id=model_id, inference_id=inference_id)
Deleting metadata for an inference:
metadata.delete_metadata(
model_id=model_id, inference_id=inference_id, key="image_chip_id"
)
Querying the Inference Store
- UI
- SDK
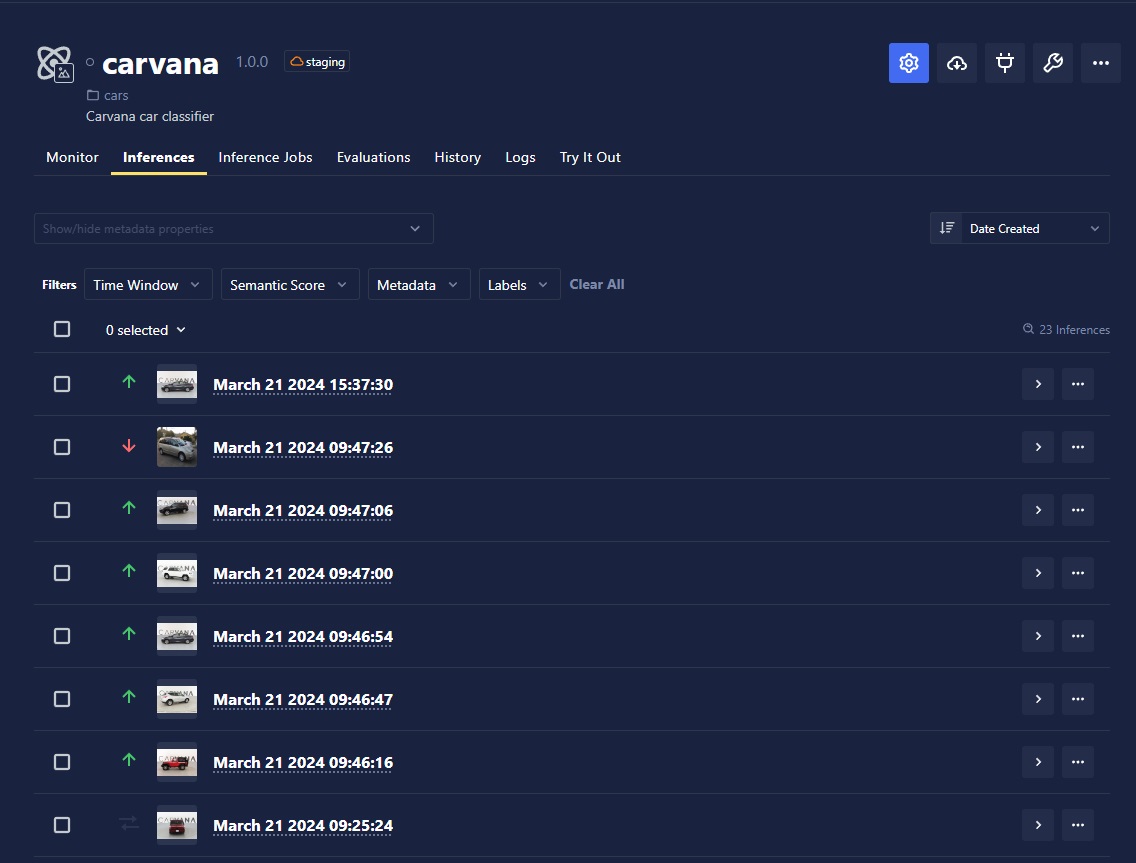
At the moment, the UI only supports viewing the inferences of a single model at once. To view your inferences, navigate to the model whose inferences you wish to view and click the Inferences tab. From this tab, you can view inferences and filter them by time, semantic score, labels, and other metadata.
The SDK provides a flexible interface for querying data in the inference store.
Getting all inferences for a model:
from chariot.inference_store import inference, metadata, models
inference_filter = models.NewGetInferencesRequest()
i = inference.filter_inferences(model_id=model_id, request_body=inference_filter)
Getting a limited set of inferences for a model:
p = models.Pagination(
limit=5,
offset=5,
sort=models.PaginationSortField.CREATED_AT,
direction=models.PaginationSortDirection.ASCENDING,
)
inference_filter = models.NewGetInferencesRequest(
data_source_filter=data_source, pagination=p
)
i = inference.filter_inferences(model_id=model_id, request_body=inference_filter)
Getting inferences with a particular data source:
# Must provide the following within the inference request metadata:
# {"key": "data_source", "type": "string", "value": "<value>"}
inference_filter = models.NewGetInferencesRequest(data_source_filter=data_source)
i = inference.filter_inferences(model_id=model_id, request_body=inference_filter)
Getting inferences with a particular data hash:
data_hash = metadata.get_data_hash(...)
inference_filter = models.NewGetInferencesRequest(data_hash_filter=data_hash)
i = inference.filter_inferences(model_id=model_id, request_body=inference_filter)
Getting inferences within a time window:
time_window_filter = models.TimeWindowFilter(
start="2024-01-01T00:00:00Z", end="2025-01-01T00:00:00Z"
)
inference_filter = models.NewGetInferencesRequest(
time_window_filter=time_window_filter
)
i = inference.filter_inferences(model_id=model_id, request_body=inference_filter)
Getting inferences within a location:
# Must provide the following within the inference request metadata:
# {"key": "latitude", "type": "float", "value": "<value>"},
# {"key": "longitude", "type": "float", "value": "<value>"}
lat, lon = 30.266666, -97.733330
location_filter = models.GeolocationFilter(
gps_coordinates_circle=models.GeoCircle(
center=models.GeoPoint(latitude=lat, longitude=lon), radius=1000
)
)
inference_filter = models.NewGetInferencesRequest(location_filter=location_filter)
i = inference.filter_inferences(model_id=model_id, request_body=inference_filter)
location_filter = models.GeolocationFilter(
gps_coordinates_rectangle=models.GeoRectangle(
p1=models.GeoPoint(latitude=lat - 0.01, longitude=lon - 0.01),
p2=models.GeoPoint(latitude=lat + 0.01, longitude=lon + 0.01),
)
)
inference_filter = models.NewGetInferencesRequest(location_filter=location_filter)
i = inference.filter_inferences(model_id=model_id, request_body=inference_filter)
Getting inferences with particular metadata constraints:
metadata_filter = [
models.MetadataFilter(key="organization", type="string", operator="!=", value="b"),
models.MetadataFilter(key="angle", type="float", operator=">", value="10.0"),
models.MetadataFilter(key="count", type="int", operator="<", value="4"),
]
inference_filter = models.NewGetInferencesRequest(metadata_filter=metadata_filter)
i = inference.filter_inferences(model_id=model_id, request_body=inference_filter)
Any combination of the above filters can be used.
Creating a Dataset From Inference Data
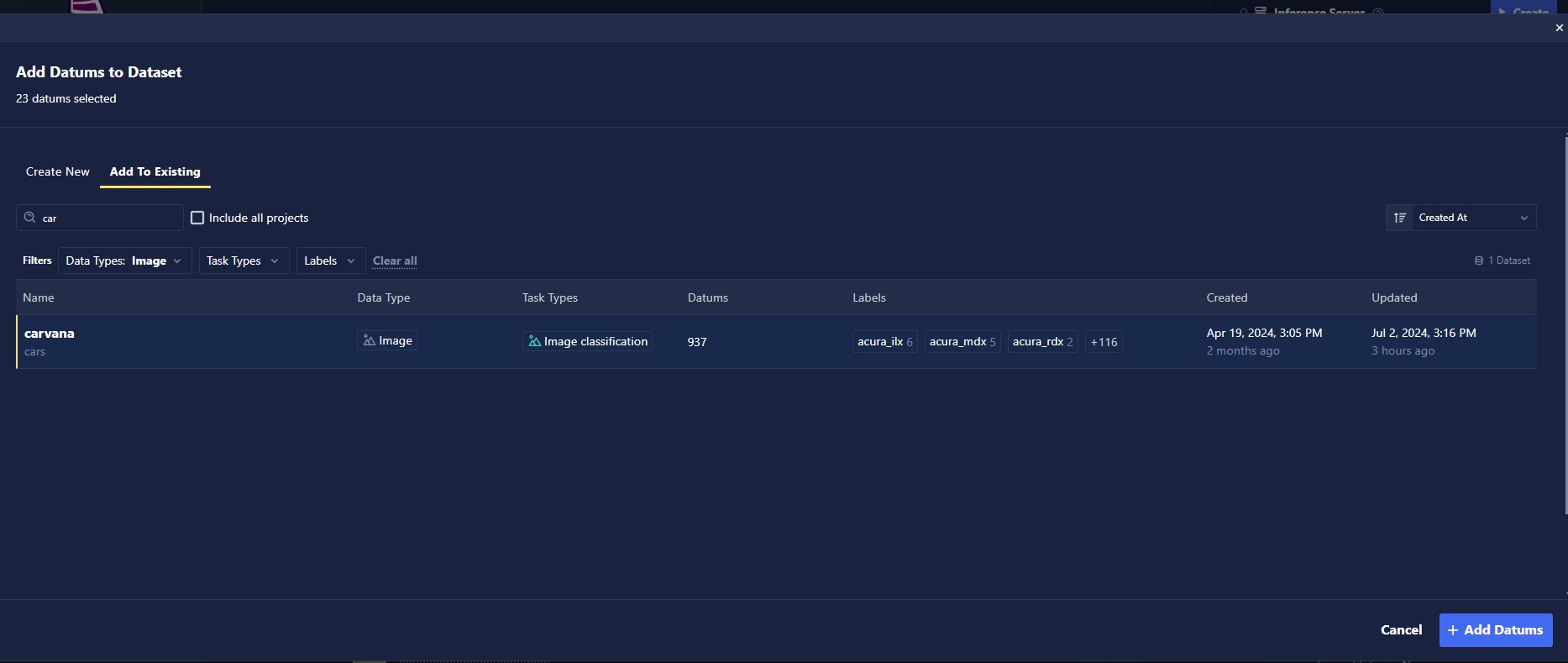
Production inferences in the inference store can be useful for further fine-tuning or evaluating your models. Inferences can easily be used to create a new dataset or added to an existing dataset.
Select individual inferences using the selection box on the left-hand side of the inference, or select an entire page or all inferences using the drop-down selector or floating selection box at the top of the inference table. When the desired inferences are selected, click the Add to Dataset button.
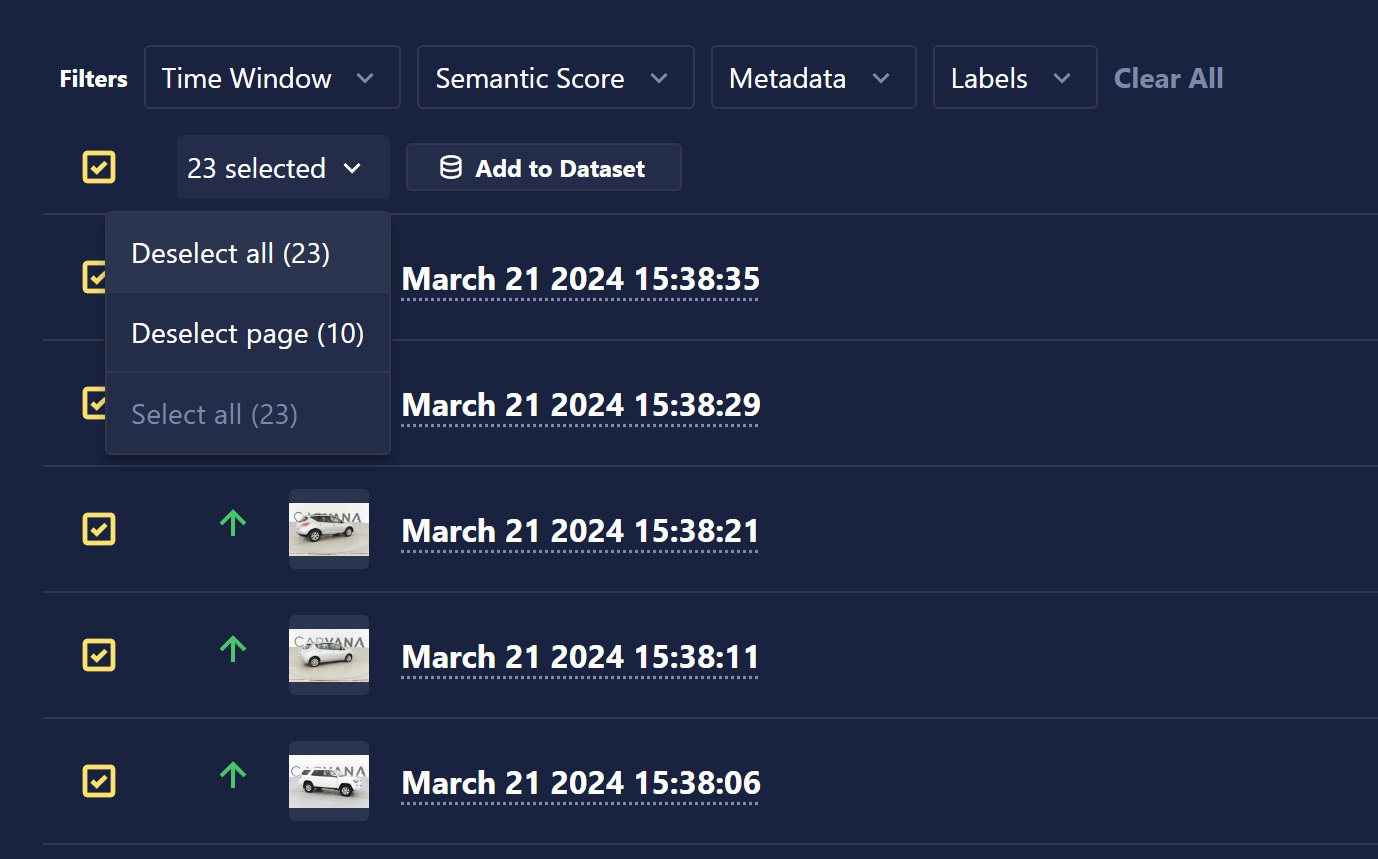
Provide the name of the new dataset that you would like to create, or select an existing dataset to add to. Once you've made your dataset selection, click the Add Datums button, and your inferences will begin uploading to the dataset!