Inference Servers
Setting Up an Inference Server
You can interact with the Inference Server using the or through the API. Code snippets unique to your server can be found by clicking the Connect to server button.
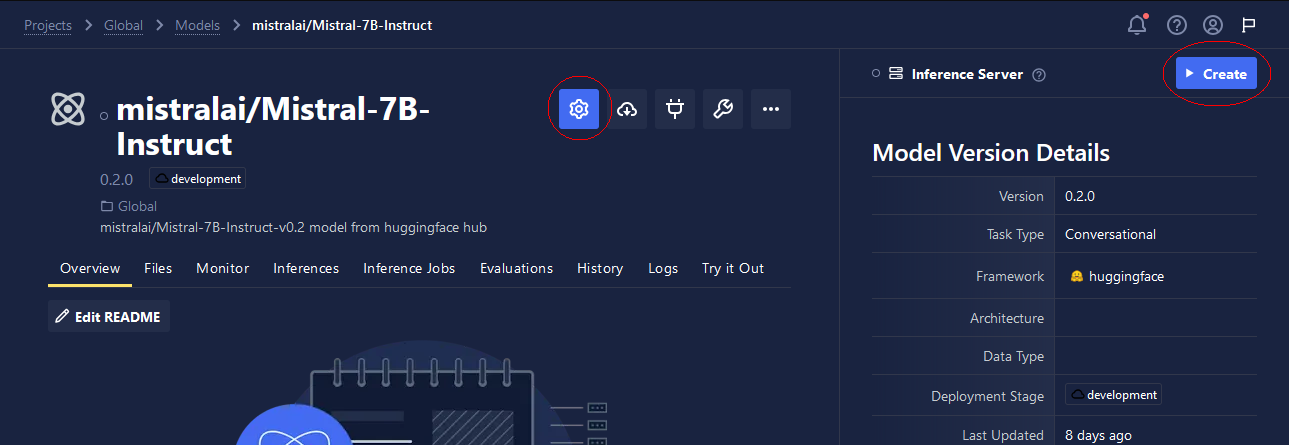
To create an Inference Server, click the Create button. You can modify the server's settings by clicking the Cog button. When the Model Version Settings modal window opens, you'll see tabs for Inference Server, Monitoring, and Storage. These tabs offer customization options so that you can optimize the deployment of your model, allowing you to minimize costs while tailoring performance to meet your specific requirements. Below, we review these options and highlight additional features available for certain task types.
Inference Server Components
Chariot Inference Servers consist of two Components, a predictor and a transformer. Options in the Model Version Settings window (and SDK Inference Server settings functions) are handled by one of these resources. Core Inference Server features like inference itself are handled by the predictor. This is the resource that loads your model data when you start an Inference Server. Other features like inference storage and drift detection are handled by the transformer, a separate resource that communicates automatically with the predictor.
Chariot provides a wide range of options to optimize serving your model so that you can keep costs down while customizing the performance to match your needs. In this section, we will go over these options and highlight some additional features that are available if your model is a certain task type.
Compute Resources
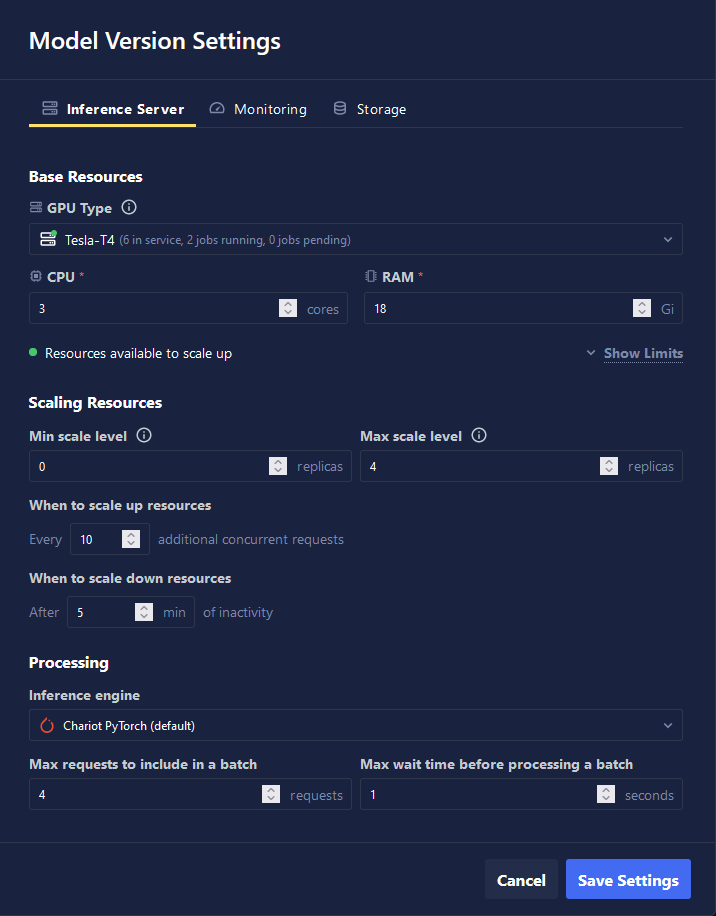
Within the Inference Server tab, the Base Resources section allows you to configure your model to run on either a GPU or CPU and allocate the necessary resources accordingly. Note that in some cases, the Inference Server may take several minutes to initialize if the required resources are not immediately available.
If the Inference Engine supports GPUs, you can request one. Some Inference Engines support Multi-GPU—multiple GPUs on a single node, not distributed computing.
Inference Server Scaling
The Scaling Resources section offers controls for adjusting the server's capacity based on demand. Setting the minimum to zero allows the server to shut down when idle, which helps to reduce costs. This is similar to putting a computer into sleep mode—it will automatically wake up and resume operations when there is activity. You can control scaling behavior by specifying the threshold for concurrent requests and setting the duration of inactivity before scaling down begins.
Monitoring Settings
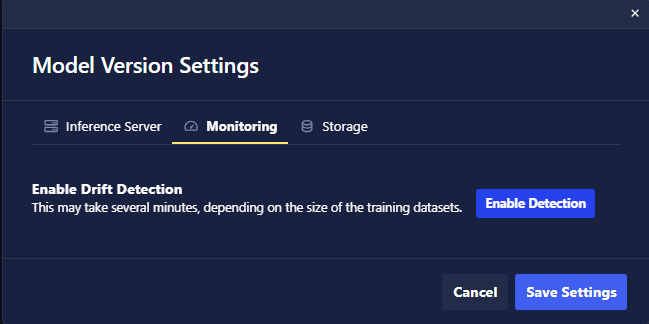
Drift detection is available to you for a Chariot model with an associated Training Run and a corresponding dataset. First, register the model and datasets to enable the Inference Servers to monitor incoming data for potential data drift. This powerful functionality allows you to detect when production data begins to deviate from the data used during training, providing valuable insights. View these data drift detections within the Monitor tab on your model's page. For more details, see Drift Detection.
Inference Storage
This tab is focused on storage management. You have the option of storing the images sent to your model, along with the corresponding inferences. These inferences can be viewed under the Inferences tab on your model's page, and you can even curate new datasets from this data to retrain your model. However, since storing such data can consume significant storage space, Chariot offers retention policies to help manage and clean up outdated data that may no longer be required. For more details on inference storage, see Inference Store.
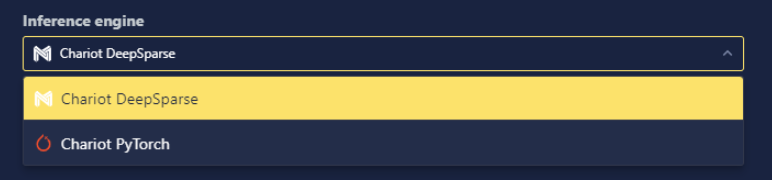
Inference Engine Selection
Some models support multiple Inference Engines, the underlying code and methods used to load the model and run inference. You can also define your own custom Inference Engines to run their Custom models. For more details on custom Inference Engines, see Custom Inference Engines.
- UI
- SDK
When creating an Inference Server, if multiple Inference Engines are supported for a model, the Inference Engine setting will be available, and the supported options will be contained in the drop-down.
Using the SDK, it is possible to determine which Inference Engines are available and to start, if necessary, converting the model. You can also start an Inference Server with a specific Inference Engine.
import chariot.client
from chariot.models import Model, ArtifactType
chariot.client.connect()
model = Model(
name="<NAME OF MODEL>",
# One of `project_id` or `project_name` is required.
project_id="<PROJECT ID>",
project_name="<PROJECT NAME>",
start_server=False
)
inference_engines = model.supported_and_existing_inference_engines()
model.start_inference_server(inference_engine=InferenceEngine.CHARIOTPYTORCH.value)
Sending Data to Models
- UI
- SDK
- Python
The UI offers a try-it-out feature where inference can be run through a web interface. To use this feature, click on the Actions button on the model's page, and select Create Inference Server. After an Inference Server is started, the Try it Out tab will be enabled.
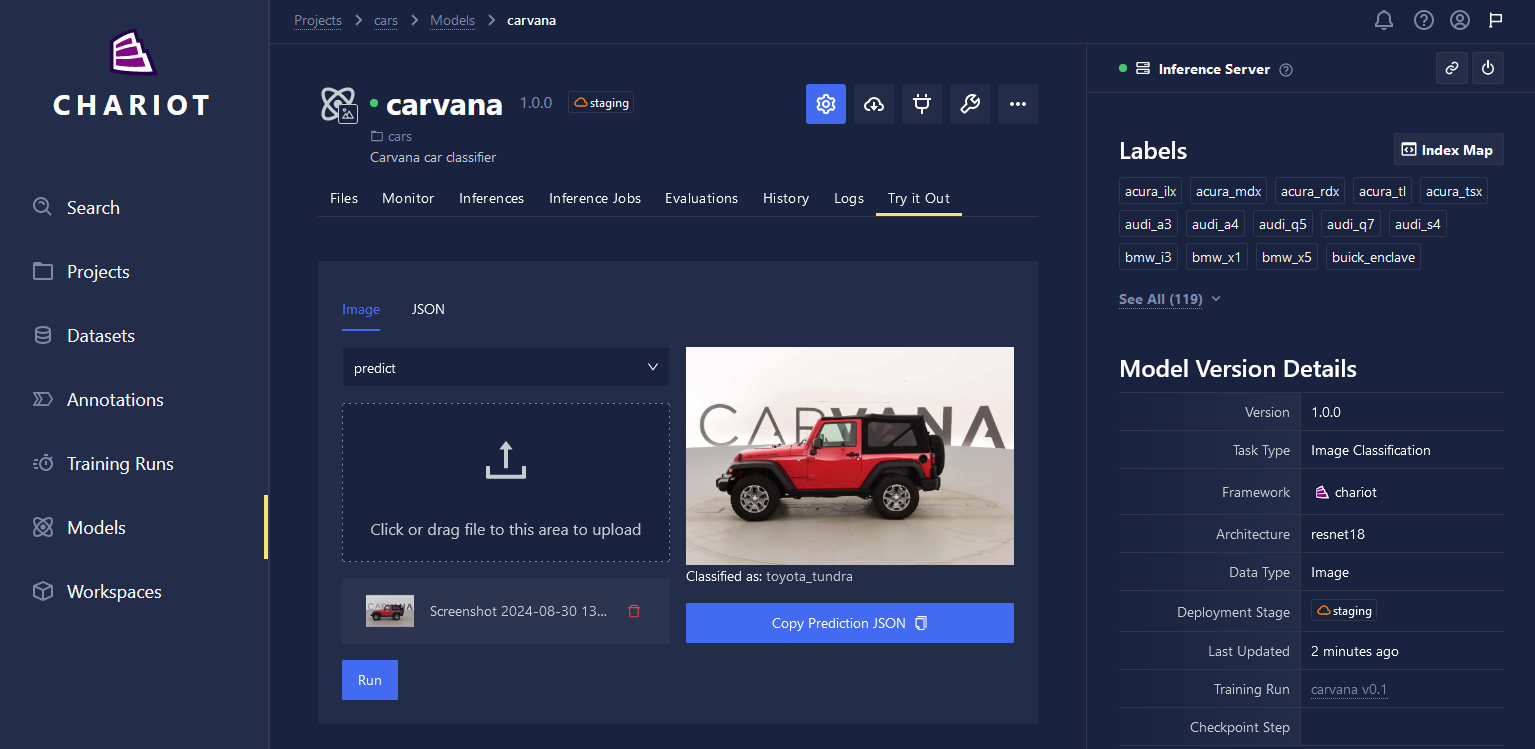
To use a model programmatically, the SDK provides the chariot.models.Model class. The following snippet loads a model given its name and (sub)project name(s):
from chariot.client import connect
from chariot.models import Model
connect()
model = Model(
name="<NAME OF MODEL>",
# one of `project_id` or `project_name` is required
project_id="<PROJECT ID>",
project_name="<PROJECT NAME>",
)
This will automatically start an Inference Server for the model. Depending on the type of the model, various class methods will be exposed for inference:
- For Image Classification, Image Segmentation, and Structured Data Classification models,
predictandpredict_probawill run a hard and soft classification, respectively. - For Object Detection models, the
detectmethod is available. - For Image Embedding models, the
embedmethod is available. - For Autoencoding models, the
embedandreconstructmethods are available.
All Computer Vision models take in either a local path to an image as a PIL.Image object, base64 encoded string, or raw bytes. For example, the following snippet outputs the predicted class label string of an image for a Classification model:
from PIL import Image
img = Image.open("/path/to/img")
pred = model.predict(img)
print(pred)
For scikit-learn models, the input is expected to be a list of lists (i.e., batch input). For example, for a Classification model, the following snippet should print a list of strings of length two, giving the predicted class labels for the two datapoints:
pred = model.predict([[1, 2, 3, 4], [9, 7, 1, 3]])
print(pred)
Importantly, inference is not run on the local machine that the above code is running on, but rather the inference methods are making http requests to the Inference Server, which is running on the Chariot Kubernetes cluster. This has the following benefits:
- The SDK has very few resource requirements.
- Different services and SDK instances can use the same Inference Server.
- Inference Servers take advantage of Kubernetes autoscaling.
The Python requests library, along with other HTTP libraries, can be used to make calls to Inference Servers.
See the for information on creating Chariot client credentials.
import base64
import io
import requests
import os
from PIL import Image
# Get Chariot access token with client credentials.
CLIENT_ID = os.getenv("CLIENT_ID")
CLIENT_SECRET = os.getenv("CLIENT_SECRET")
CLIENT_SCOPE = os.getenv("CLIENT_SCOPE")
# BASE_URL including the scheme
BASE_URL = os.getenv("BASE_URL").rstrip()
AUTH_URL = f"{BASE_URL}/auth/client/v2/chariot/login"
body = {
"client_id": CLIENT_ID,
"client_secret": CLIENT_SECRET,
"client_scope": CLIENT_SCOPE,
"grant_type": "client_credentials",
}
s = requests.Session()
resp = s.post(AUTH_URL, data=body)
bearer_token = resp.json()["access_token"]
headers = {"Authorization": f"Bearer {bearer_token}"}
s.headers.update(headers)
# Open image from file_path and send to inference server.
def image_shape(file_path):
image = Image.open(file_path)
width, height = image.size
# TODO: handle all modes from
# https://pillow.readthedocs.io/en/stable/handbook/concepts.html#modes
if image.mode == "RGB":
channels = 3
elif image.mode == "RGBA":
channels = 4
else:
raise NotImplementedError(f"image mode {image.mode} not implemented")
return width, height, channels
buf = io.BytesIO()
with open(PATH_TO_IMAGE, 'rb') as fp:
base64.encode(fp, buf)
width, height, channels = image_shape(PATH_TO_IMAGE)
body = {
"inputs": [
{
"data": buf.getvalue().decode('utf-8'),
"datatype": "BYTES",
"name": "try-it-out",
"parameters": { "action": "predict" },
"shape": [ width, height, channels ],
}
]
}
response = s.post("<url_to_inference_server>", json=body)
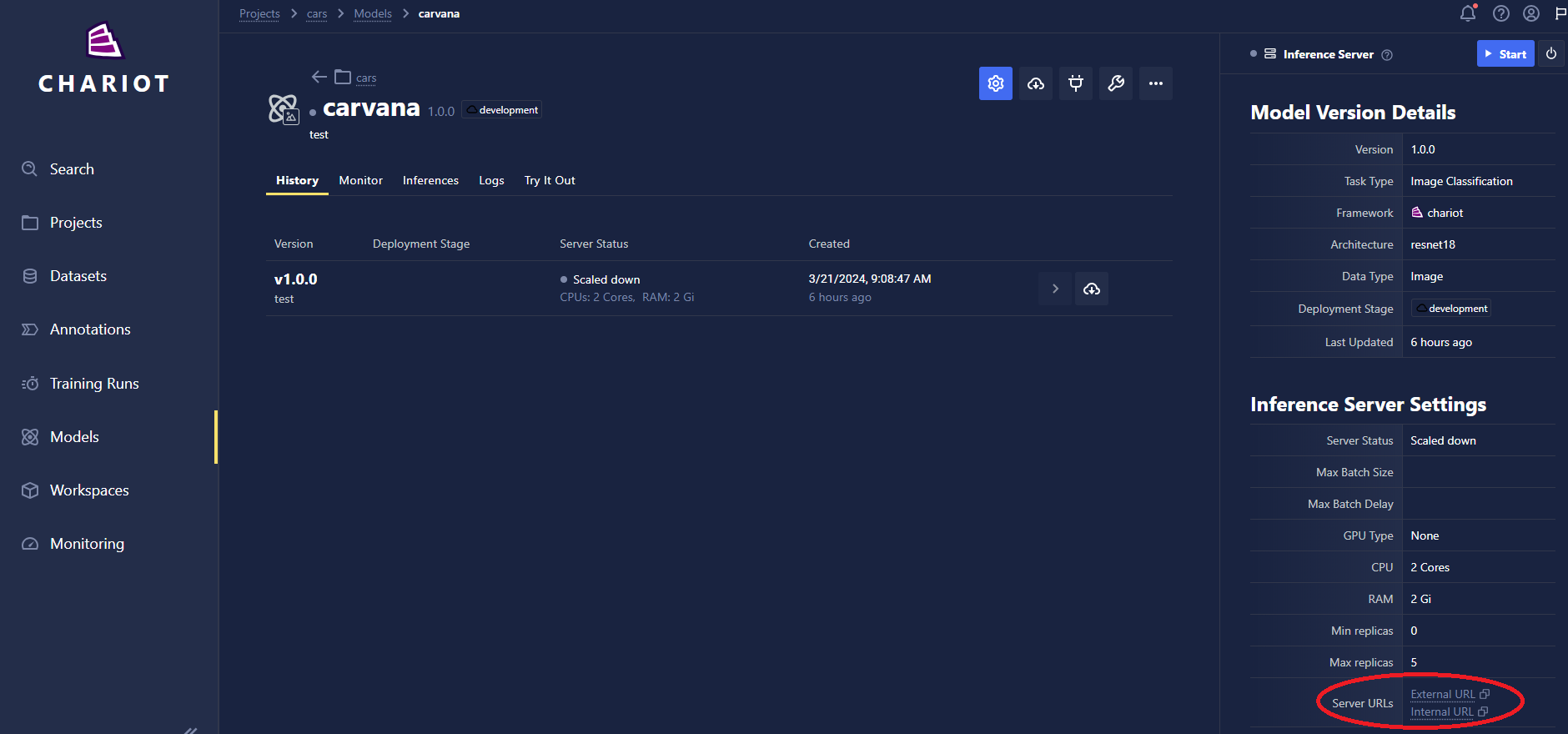
To find the URL for the Inference Server, navigate to the Inference Server detail page and click on Details, where the external URL can be found.
Batching
Batching is the process of passing a collection of inputs (images, strings, etc.) to a model in a single inference request rather than sending them each as a separate request. Depending on the model and what hardware it is running on, this can be more efficient. There are two ways that batching is done in Chariot: client side and server side. Client side batching is where you explicitly pass all of your inputs into one request. For example, with the SDK, this looks like:
from chariot.client import connect
from chariot.models import Model
connect()
model = Model(name="my_model_name", project="my_project_name")
model.detect(["path/to/image1.png","path/to/image2.png","path/to/image3.png"])
Server side batching (also called adaptive batching) is where the Inference Server intercepts separate individual inference requests within a predetermined timeframe and automatically groups them into a single batched inference request that is then sent to the model. For example, if you send your inference requests separately as:
for path in ["path/to/image1.png","path/to/image2.png","path/to/image3.png"]:
result = model.detect(path)
then adaptive batching will automatically group these into a single batch before they reach the model.
Benefits
There are two main benefits of batching:
- Maximize resource usage: Usually, inference operations are "vectorized" (i.e., are designed to operate across batches). For example, a GPU is designed to operate on multiple data points at the same time.
- Minimize inference overhead: This can be something like input/output (IO) to communicate with the GPU or some kind of processing in the incoming data. Up to a certain size, this overhead tends to not scale linearly with the number of data points. Therefore, it is beneficial to send batches that are as large as possible without deteriorating performance.
However, these benefits will only scale up to a certain point, which can be determined either by the infrastructure, the machine learning framework used to train your model, or a combination of the two.
In order to maximize the performance improvements made by batching, it is important to tailor this configuration for specific models, environments, and use cases, which can be found through experimentation.
Using Adaptive Batching
Chariot lets you configure adaptive batching independently through two parameters:
- Maximum batch size: The maximum number of inference requests that the server will group together to process as a batch.
- Maximum batch delay: The maximum time, in seconds, that the server should wait for new requests to group together for batch processing.
Authentication
You will need to authenticate with Chariot in order to send data to models and get predictions. For detailed information on authentication methods including creating client credentials, using the SDK, and programmatic authentication, see the Authentication documentation.
Large Language Models (LLMs)
Large Language models may have additional settings. For comprehensive information about serving Large Language models in Chariot see the LLM documentation.