Drift Detection
Data drift occurs when the characteristics (e.g., content, statistical distribution, or structure) of incoming data change over time. Within Chariot, we consider model drift to have occurred whenever new inputs deviate substantially from the dataset used to train the model. In practice, drift can arise from changes in the data creation process itself or from changes in the environment where the model operates, making ongoing monitoring and retraining essential.
Chariot lets you track data drift in real time and estimate how reliably a deployed model will perform on that data. Results are available at two granularities:
| Drift type | What it checks | When to use |
|---|---|---|
| Semantic (per‑instance) drift | Compares each incoming datum to the training set to spot outliers. | Catching anomalies that might signal bad inputs, data‑quality issues, or other one-off events. |
| Batch drift | Compares the distribution of a window of data (e.g., an hour, day, or entire dataset) to the training distribution. | Detecting slow shifts, seasonal patterns, or broader changes that could affect a model's trustworthiness. |
Drift signals never override or replace the model's own predictions; they simply flag situations where those predictions may be less trustworthy.
Enabling Drift Detection
Navigate to the Models page within Chariot, and select the Monitor tab.
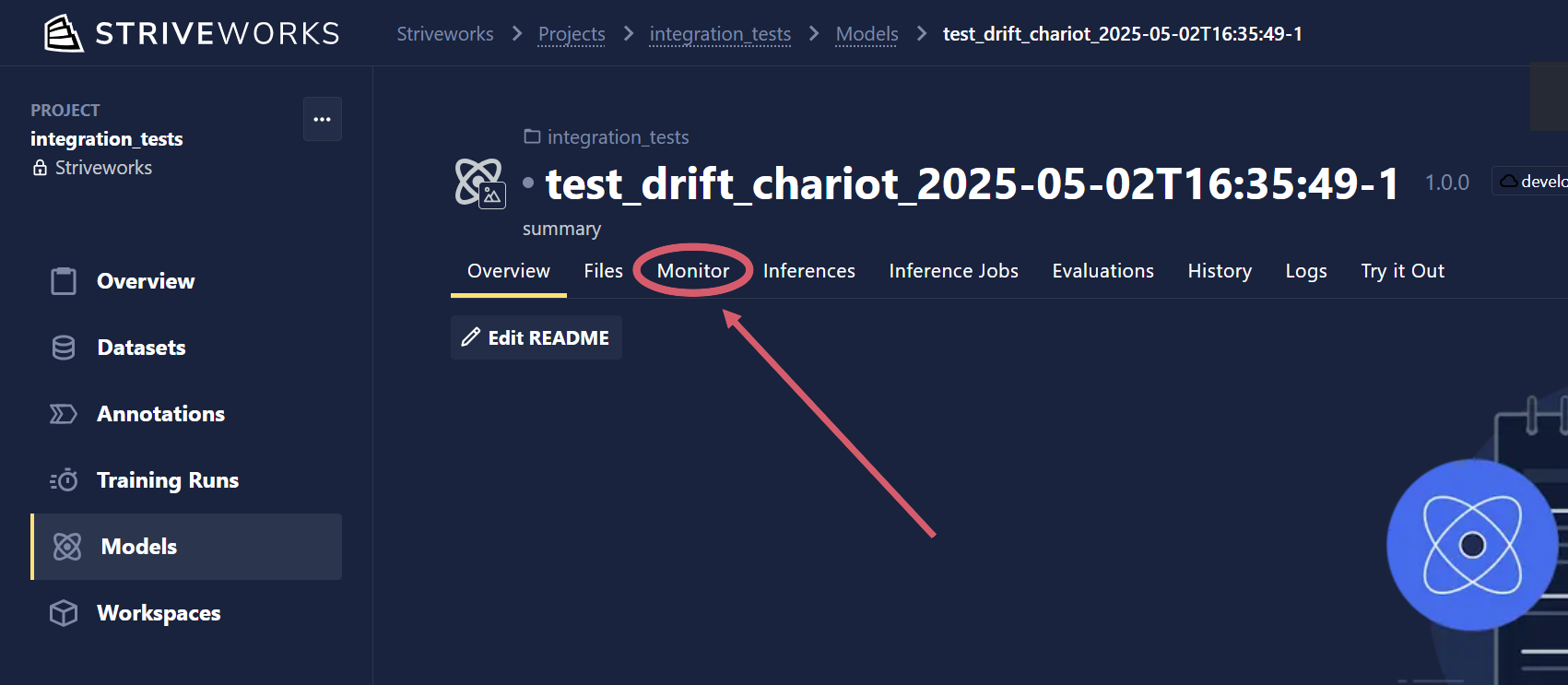
To enable model drift detection, click the Enable Detection button in the Data Drift section. Provisioning can take a few minutes, so you may see an "initializing" state before results appear.
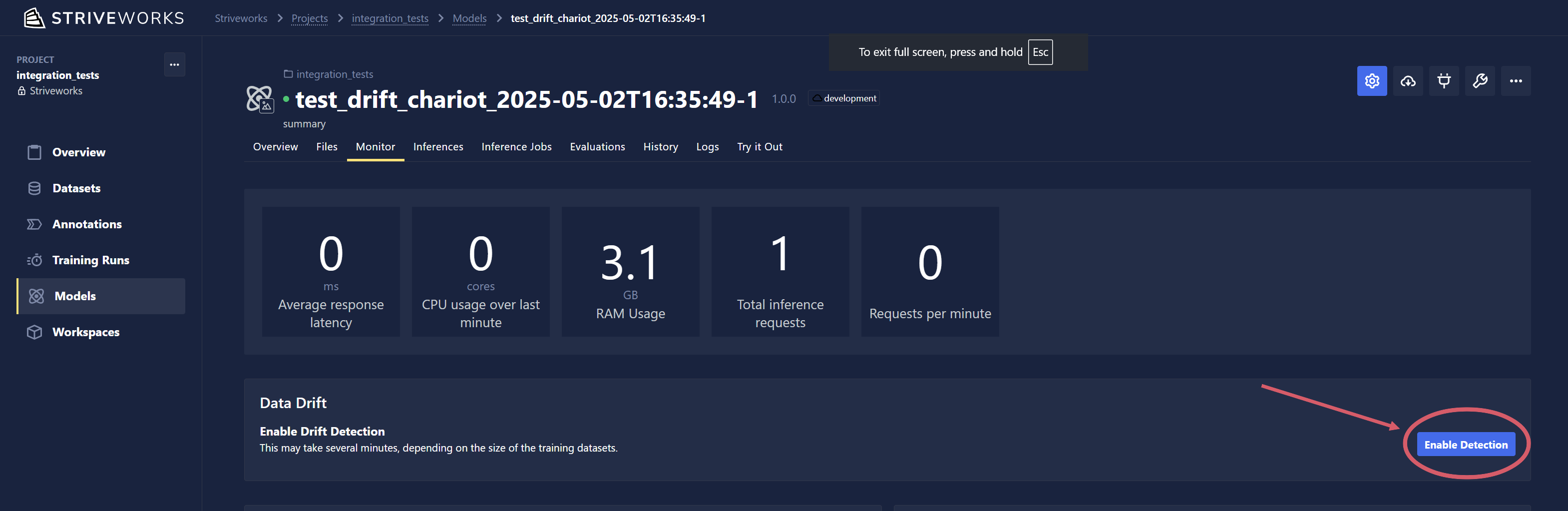
Drift detection is currently limited to models that have been trained within Chariot.
Monitoring Drift
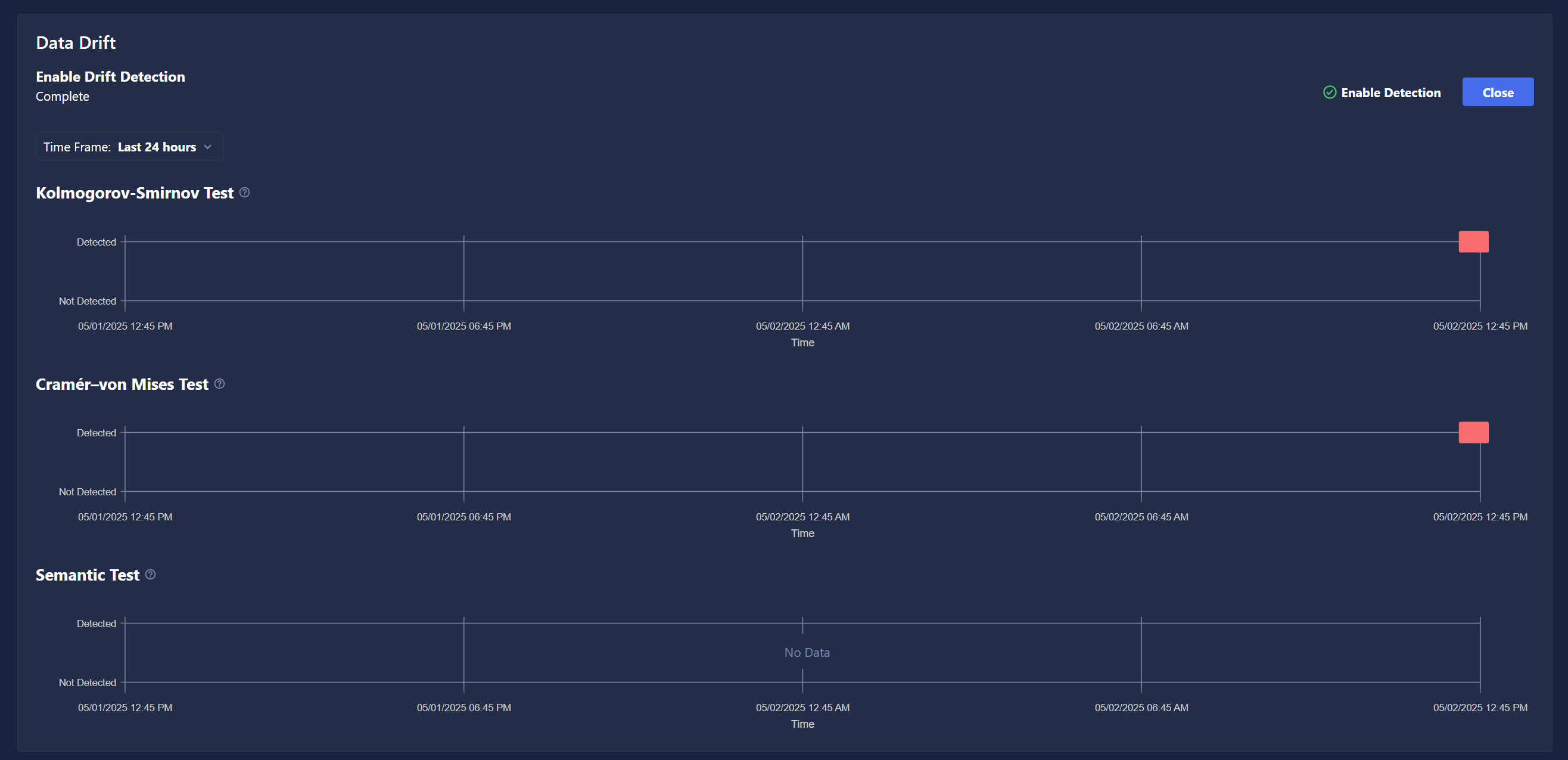
Navigate to the Models page within Chariot, and select the Monitor tab.
Scroll down to the Data Drift view. Positive drift detections will populate this graph as the Inference Server recieves new data.
Per-Inference Drift
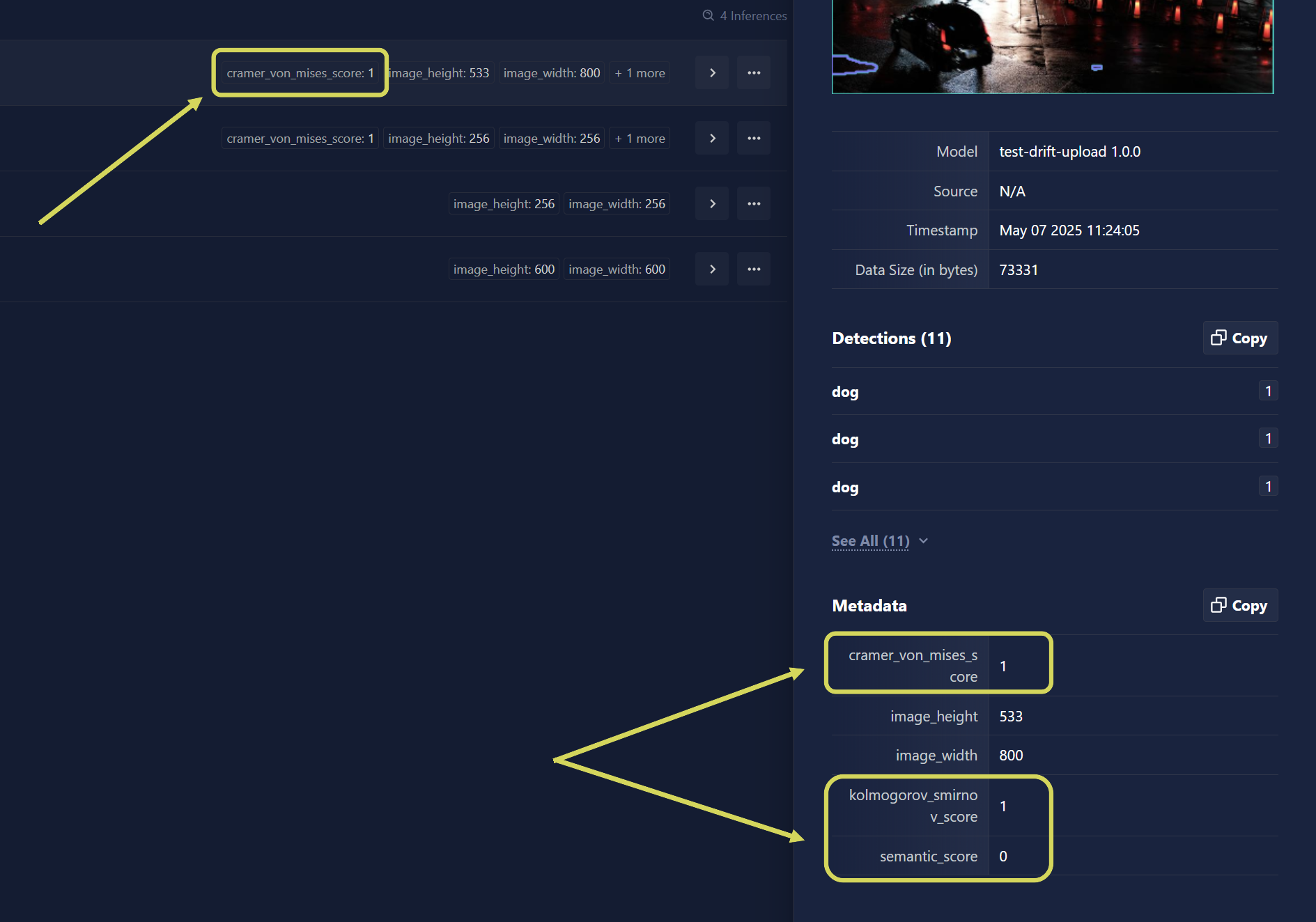
The scores returned within inference metadata are similarity scores, which are equivalent to (1 - drift_score). This means a score of 1 indicates high confidence that the datum is within the training distribution.
Navigate to the Models page within Chariot, and select the Inferences tab.
If available, semantic drift will be displayed on the left-hand side of each row. A green upward-facing arrow indicates that the datum is similar to the training set whereas a downward-facing red arrow indicates that the datum is not similar.
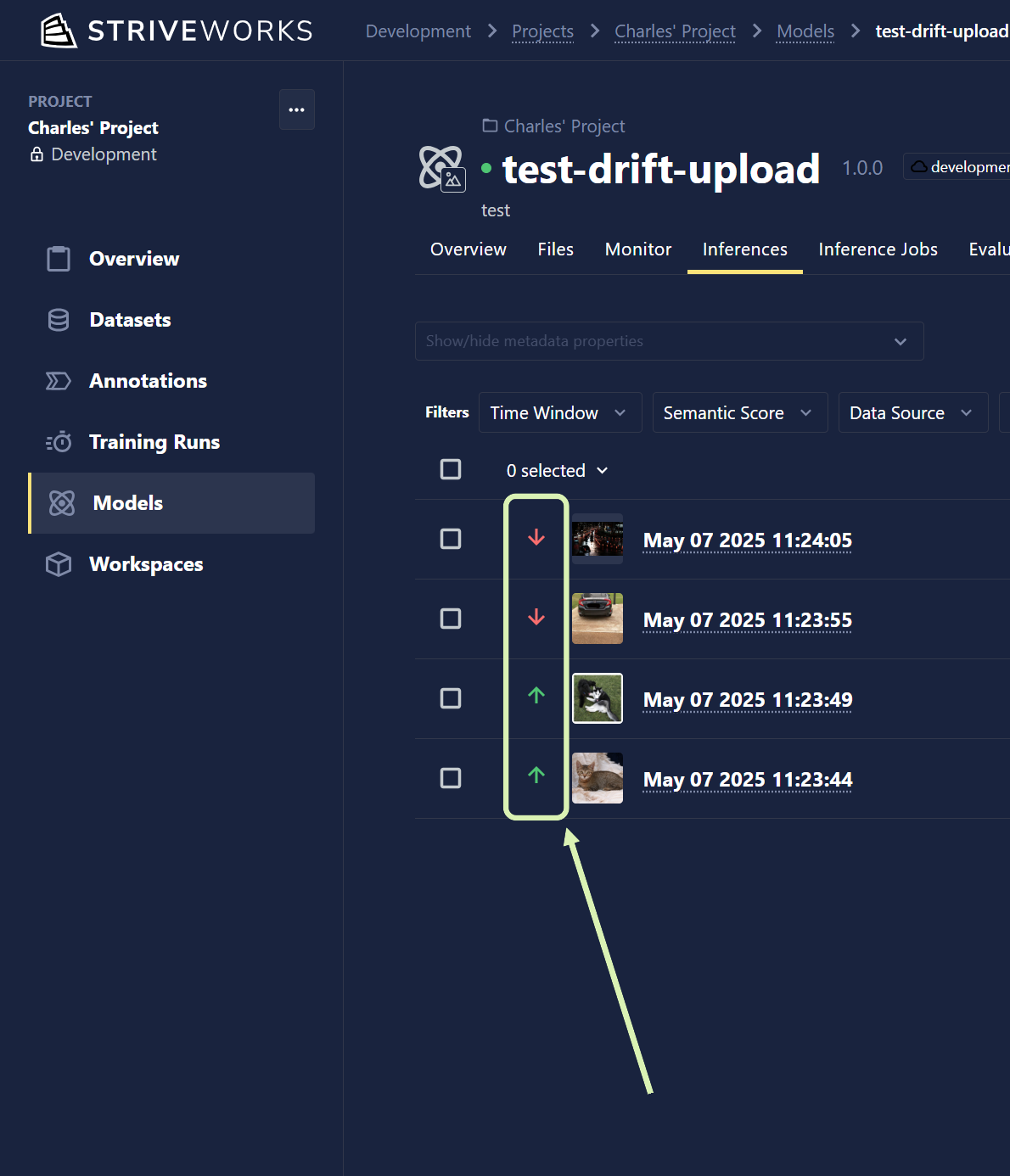
If batch metrics are available, they will be shown either inline or by clicking on the inference.
Custom Drift Detectors
By default, drift detectors are initialized on your model's training data. This guarantees that they're tuned to the data distribution your model has seen in the past. However, when you're working with a forked or third-party model, you often won't have access to its original training set. In those scenarios, you can supply your own reference dataset to build a custom drift detector that reflects the data you expect your model to see in production.
Custom drift detectors can only be created via the SDK.
import numpy as np
from collections import namedtuple
from chariot.client import connect
from chariot.models import upload_model_file
from chariot.drift import register_detector, DriftMetric
from chariot_drift import SemanticDriftDetector, BatchDriftDetector,
# ===== SETUP ======
# 1. Connect Chariot's client.
connect()
# 2. Select the dataset Snapshots and splits.
Snapshot = namedtuple('Dataset', ['snapshot_id', 'split'])
snapshots = [
# Snapshot(snapshot_id="id_123", split="train"),
# Snapshot(snapshot_id="id_456", split="test"),
]
# 3. Select the destination model.
model_id = ""
# ===== END SETUP ======
def upload_drift_detector(
model_id: str,
detector: SemanticDriftDetector | BatchDriftDetector,
):
match type(detector).__name__:
case SemanticDriftDetector.__name__:
filename = ".chariot/drift-detectors/semantic.detector"
metrics = [DriftMetric.SEMANTIC]
case BatchDriftDetector.__name__:
filename = ".chariot/drift-detectors/batch.detector"
metrics = [DriftMetric.KOLMOGOROV_SMIRNOV, DriftMetric.CRAMER_VON_MISES]
case unknown:
raise NotImplementedError(f"detector with type '{unknown}' is not supported")
storage_url = upload_model_file(
model_id=model_id,
filename=filename,
data=detector.encode(),
)
for metric in metrics:
register_detector(
model_id=model_id,
metric=metric,
storage_url=storage_url,
)
# Create image embeddings.
embeddings = np.zeros((0, 2048), dtype=np.float64)
for snapshot_id, split in snapshots:
snapshot_embeddings = embed(
snapshot_id=snapshot_id,
split=split,
verbose=True,
)
embeddings = np.concatenate([embeddings, snapshot_embeddings])
# Create the detectors.
semantic_detector = SemanticDriftDetector.fit(embeddings=embeddings)
batch_detector = BatchDriftDetector.fit(embeddings=embeddings)
# Upload the detectors.
upload_drift_detector(model_id, semantic_detector)
upload_drift_detector(model_id, batch_detector)