Overfitting
What is overfitting?
Training a model is often referred to as 'fitting' the model. When training proceeds as intended, improvements in the model's fit to the training data translate into improvements in the model's fit to the validation data. Unfortunately, improvements in the fit of a model to the training data — such as adjustments to the learned model parameters that improve the model's performance on the training data — do not always translate into improvements in the fit of the model to the validation data (i.e., the model's quality metrics degrade—sometimes significantly and rapidly). An overfit model is a model whose performance on the training data is good, but that high performance on training data does not translate to the validation (or testing) data where the model's performance is insufficient. Figure 1 below illustrates a (fictional) neural network training run alongside its observed metrics. Initially, training occurs as expected; the model loss is decreasing, which indicates improving performance on the training data, and the validation accuracy is steadily improving. However, after about 13,000 batches of training data, the model's validation performance declines rapidly, showing signs of overfitting.
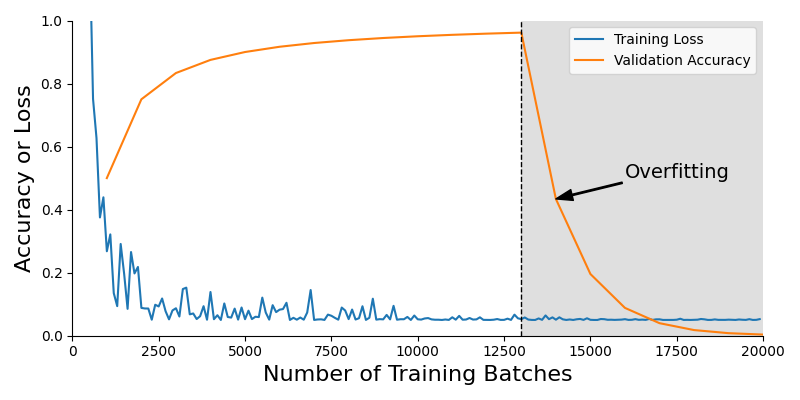
Figure 1: Example training loss and validation accuracy: Initially, the model learns as desired. At some point, the model's validation accuracy peaks, and the model begins overfitting.
What causes overfitting?
Essentially, the root of overfitting is that the model (through whatever training process) has learned to recognize something in the training data that is not present in the validation or testing data.
There are two primary reasons this might occur:
First, the model may have too much capacity for its supplied training data. This option is more likely with smaller training datasets. The more capacity a model has—roughly, the more learnable parameters it has—the easier it becomes for the model to memorize training examples or possibly the entire training dataset. Since no examples in the validation data overlap the training data (remember data splits, remembering the training data is useless for predictions on the validation/testing data.
Second, your training dataset may be vastly different from your validation dataset. When this occurs, you may have excellent accuracy metrics on the training data but still have poor performance on the validation data. This option is more likely if your validation accuracy (or other metrics on the validation dataset) was never high. In Figure 1, this is likely not the case since (before the steep drop-off) the validation accuracy was high.
The good news is that overfitting happens to everyone at some point.
If your model becomes overfit while training (as it did in Figure 1), you can revert to a checkpoint made before the overfitting occurred. As long as model checkpoints are generated frequently, you will likely have a checkpoint of the model from when it was in a well-behaved and high-performing state.
If you did not save checkpoints or did not save recently enough, or if the model never achieved a sufficiently high validation accuracy, then you can retrain the model. As mentioned in the section on model training, training models is a stochastic (random) process, and the results vary (to some degree) from run to run. If part of the problem was too infrequent a checkpoint, then be sure to adjust this in the future. You can increase the variability by adjusting some of the learning parameters, e.g., batch size, learning rate, momentum, etc., or optimizer. These parameters impact how the optimization algorithm trains the model you have. The impact of these parameters can be hard to predict, but some suggestions are included above for consideration.
Suppose you have trained your model multiple times and continually overfit before the validation accuracy (or any other metric of concern) is sufficiently good. In that case, you may want to try a different model. Larger models generally have more capacity, so reducing the model's size can reduce the model's ability to overfit. You can reduce a model's size in two ways: You could select a different model entirely (such as opting for a ResNet18 instead of a ResNet50) or increase the weight decay of the model you already have. Increasing the weight decay puts pressure on the model to use fewer weights, effectively reducing the size or capacity of your model and reducing its ability to overfit.
Can a model be underfit?
Models can also be underfit. An underfit model is one in which even the training metrics are not sufficiently good—you cannot expect that validation or testing metrics will ever be better than their corresponding training metrics. Underfit models are those that fail to learn from the training data. As with overfitting, there can be multiple causes and potential solutions. If a model underfits, best practices are similar to those for overfitting; try retraining a few times, varying the optimizer parameters somewhat—hoping to take advantage of some stochasticity in the process. If that doesn't work, try swapping out the model for one with greater capacity. Be aware that swapping the model for one with greater capacity is the opposite of what one might do if the model is overfitting.