Dataset Curation
Production inferences in the Inference Store can be useful for further fine-tuning or evaluating your models. Inferences can easily be used to create a new dataset or added to an existing dataset.
Creating Datasets From Inference Data
- UI
- SDK
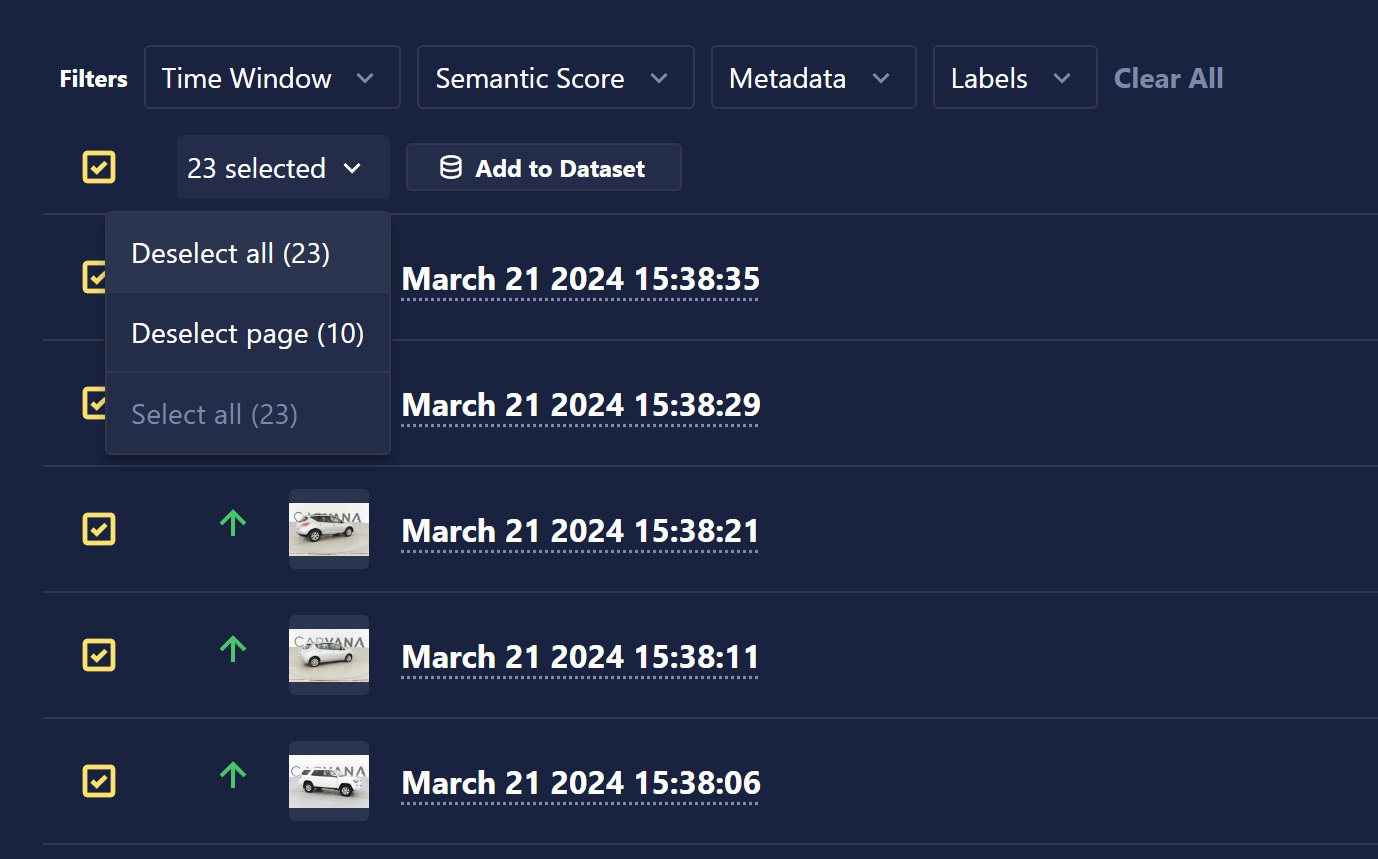
Select individual inferences using the selection box on the left-hand side of the inference, or select an entire page or all inferences using the drop-down selector or floating selection box at the top of the inference table. When the desired inferences are selected, click the Add to Dataset button.
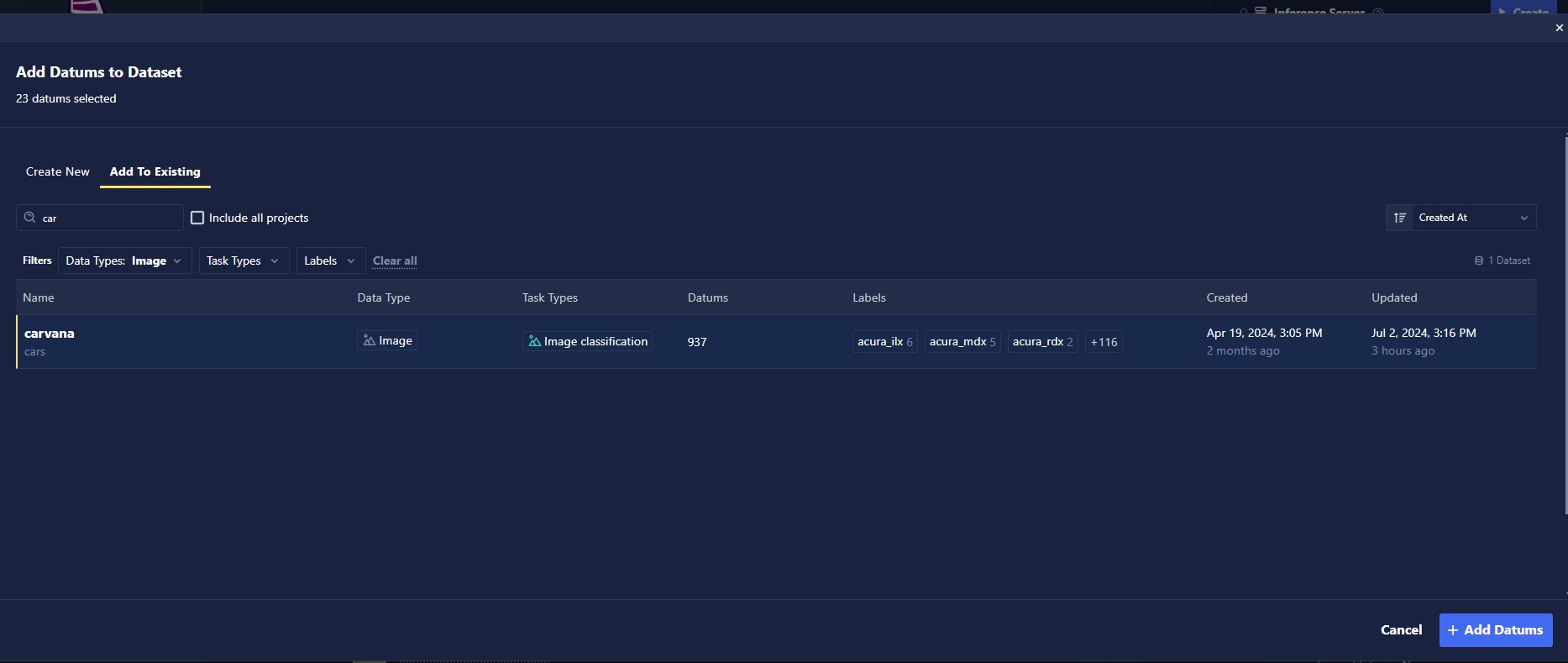
Provide the name of the new dataset that you would like to create, or select an existing dataset to add to. Once you've made your dataset selection, click the Add Datums button, and your inferences will begin uploading to the dataset!
The SDK provides multiple ways to export data from the Inference Store to Chariot datasets. You can use the SDK to download data individually and manually create a dataset object, but the SDK also provides Export Tasks that automatically create the dataset object for you, which can then be uploaded as a dataset.
Export tasks require at least one inclusion criterion, meaning that you must specify filters (time window, metadata, etc.), specific inference IDs, or both. A request sent with no filters and no inference IDs will result in a rejected request and error.
Create an export task to generate a dataset from filtered inferences:
import time
from chariot.inference_store import models, export_task
time_filter = models.TimeWindowFilter(
start="2025-01-01T00:00:00Z",
end="2030-01-01T00:00:00Z"
)
export_request = models.NewExportTaskRequest(
filters=models.BaseInferenceFilter(time_window_filter=time_filter),
include_inferences_as_annotations=True, # Include model predictions as annotations
include_custom_metadata=True # Include custom metadata in export
)
# Alternative Option 2: Export specific inferences by ID
# export_request = models.NewExportTaskRequest(
# include_inference_ids=["inference_id_1", "inference_id_2"], # Specific inference IDs
# include_inferences_as_annotations=True,
# include_custom_metadata=True
# )
# Alternative Option 3: Export specific inference AND any that match metadata filters
# export_request = models.NewExportTaskRequest(
# filters=models.BaseInferenceFilter(time_window_filter=time_filter),
# include_inferences_as_annotations=True,
# include_custom_metadata=True
# )
# Create the export task
task = export_task.create_export_task(model_id=model_id, request_body=export_request)
print(f"Export task created with ID: {task.id}, Status: {task.state}")
# Monitor the export task until completion
is_complete = False
attempts = 0
max_attempts = 30 # Adjust based on expected dataset size
while not is_complete:
task = export_task.get_export_task(model_id=model_id, export_task_id=task.id)
if task.state in ["pending", "scheduled", "running"]:
attempts += 1
print(f"Export task is {task.state}, attempt {attempts}/{max_attempts}")
if attempts >= max_attempts:
raise Exception("Export task exceeded maximum wait time")
time.sleep(5) # Wait 5 seconds between checks
elif task.state == "failed":
raise Exception(f"Export task failed: {task.error_message if hasattr(task, 'error_message') else 'Unknown error'}")
elif task.state == "complete":
is_complete = True
print(f"Export completed! Processed {task.progress_count}/{task.expected_count} inferences")
print(f"Export download URL: {task.presigned_url}")
The annotations added to the dataset will have the Annotation Review Status of Needs Review.