Creating Evaluations
Model evaluation metrics are calculated based on evaluating model inferences against ground truth data (human annotated labels). Model evaluation empowers data scientists and engineers to evaluate the performance of their machine learning pipelines and use those evaluations to make better modeling decisions in the future.
Inference Jobs
To create the inferences needed for evaluation, you need to start by setting up an inference job, which will run inference across selected data and evaluate the model's predictions against the dataset's annotations. As a prerequisite, you must have a dataset available in your project that contains human-verified annotations.
Step 1: Start an inference job
Navigate to the Models page within Chariot, and select the Inference Jobs tab. To create an evaluation, click the + Bulk Inference button.
You need to have your model deployed via an Inference Server to start an inference job. See the Inference Server section for more details.
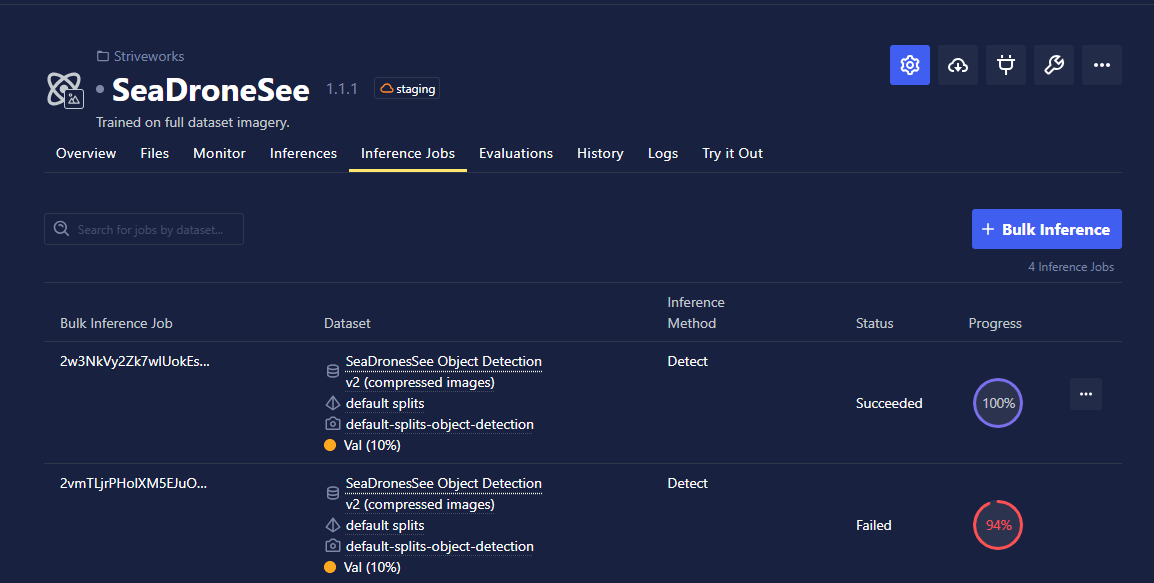
Step 2: Select a dataset
Select the annotated dataset you wish to compare your model's performance against in this process. This dataset will act as the ground truth for the inference job you run.
Step 3: Review progress
While the bulk inference job is running, you can view its progress and logs of the job on the Inference Jobs tab. Once an inference job is complete, you will receive a notification within Chariot.
Viewing Model Performance
Once the bulk inference job is complete, there are several areas where you can view your model performance metrics. For more information regarding available metrics, review the metrics that are computed by Valor here.
The Models Catalog page contains an Evaluation Metric column. You can hover the mouse over the name of the dataset you have evaluated against to see more information about the dataset including the data splits, splits used for evaluation, and sample size.
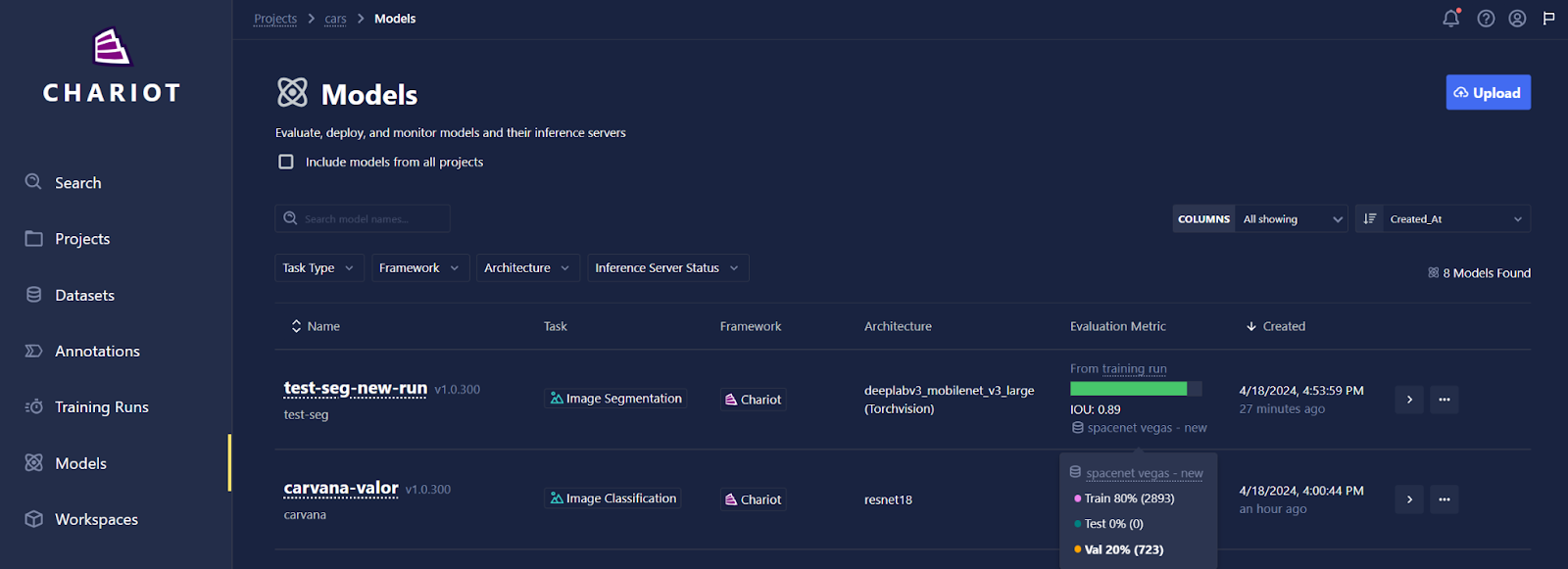
The evaluation metric displayed for each model will vary depending on whether your model was trained within Chariot or if it was trained externally and then imported:
- The Chariot-native model metric will be based on the training metrics associated with the checkpoint you cataloged your model from in the Training Run.
- Models uploaded into Chariot will display the evaluation metrics resulting from the latest bulk inference job.
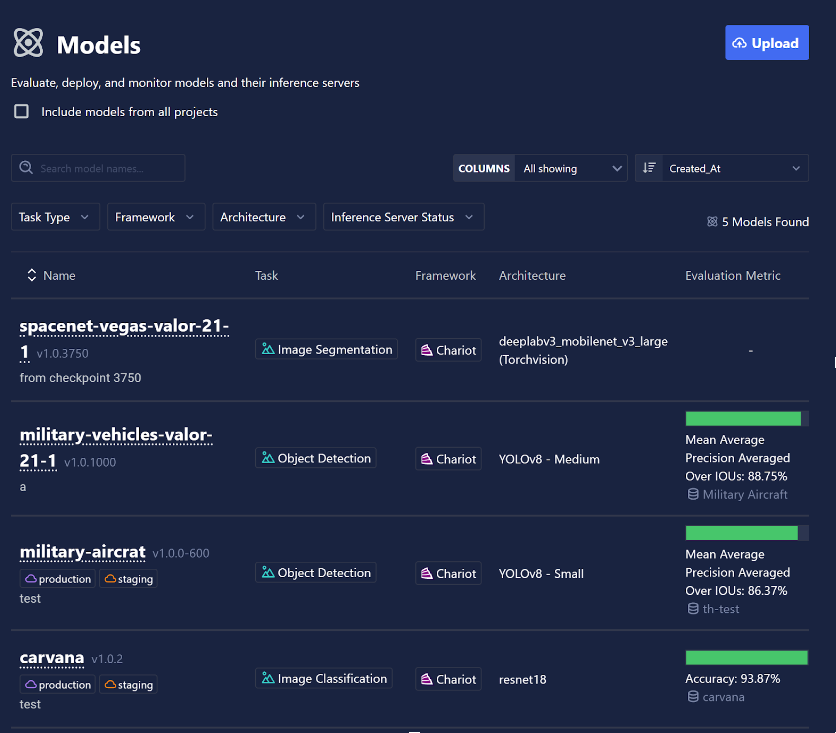
Chariot will display the metric that provides the best overall understanding of model performance for the given task type.
- Object Detection models will display mAP averaged over IoUs.
- Image Classification models will display overall accuracy as the number of true predictions divided by the total number of predictions.
More detailed metrics can be found in the Evaluations tab of the individual page of each model, including the results of all evaluations that have been processed through inference jobs or evaluations created while training a model within Chariot.
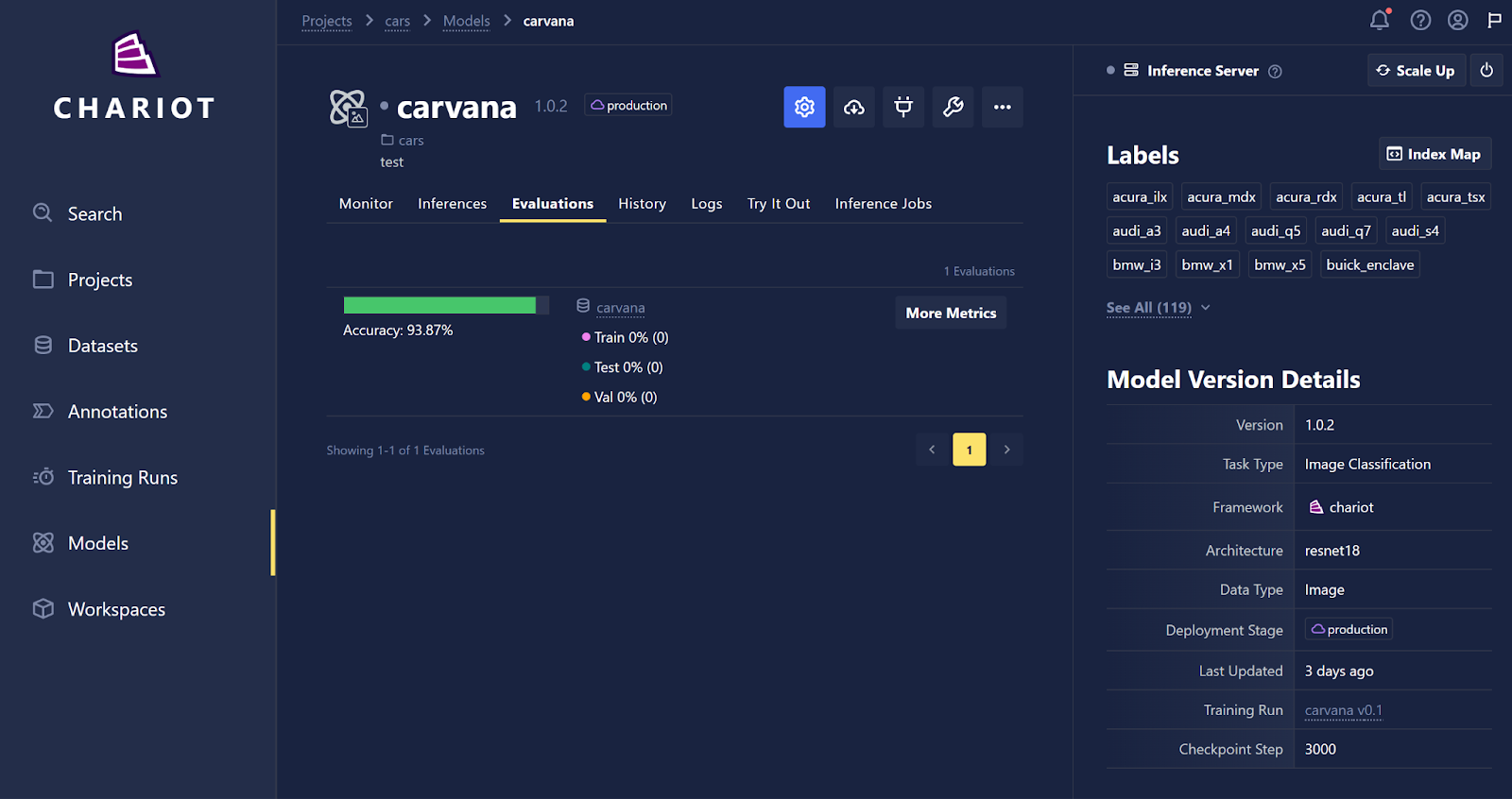
Clicking the More Metrics button will redirect you to the Model Comparison page for a deeper dive on the metrics generated for the model, including per class metrics.