Uploading Datasets
Chariot supports uploading either annotated or unannotated data.
Uploading Data
- UI
- SDK
To upload a dataset into Chariot, click the Datasets tab on the left-hand navigation bar, and then click Create Dataset.
When choosing data to upload, you can either upload images individually (with a maximum of 25) or in a compressed archive file (which is required to upload annotated data) of all of the images. The archive file must be either a compressed .tar or .zip file with the images in it and a .jsonl file. Annotation format information can be found here.
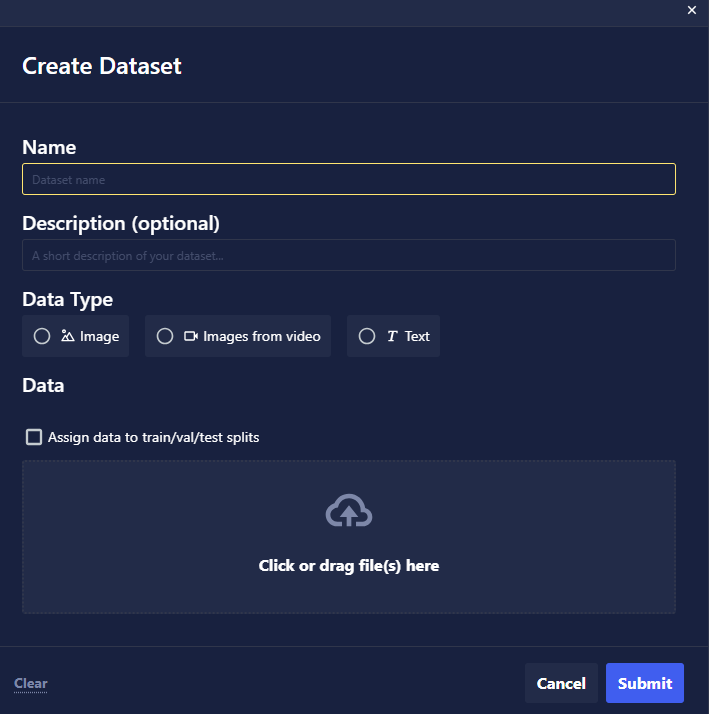
When prompted, provide the following information:
- Data Type: Choose which kind of data—image or text—you would like to bring into Chariot. Each dataset type has different annotations and expected outcomes.
- Name: Provide a name for the dataset. This is used to reference the dataset in the project.
- Description: Provide a short description of the dataset for your own reference. This may be helpful in differentiating between similar datasets in a project.
- Upload Files: Select the local file(s) you want to upload into the dataset.
Click Submit to finish creating the dataset.
During the upload process, relevant EXIF metadata is extracted from each image, with GPSDateTime, GPSLatitude, and GPSLongitude being particularly useful for filtering datums later. If needed, these fields can be overwritten using custom metadata when uploading a dataset. For more details, refer to the Metadata Format section.
Uploading Data to Specific Splits
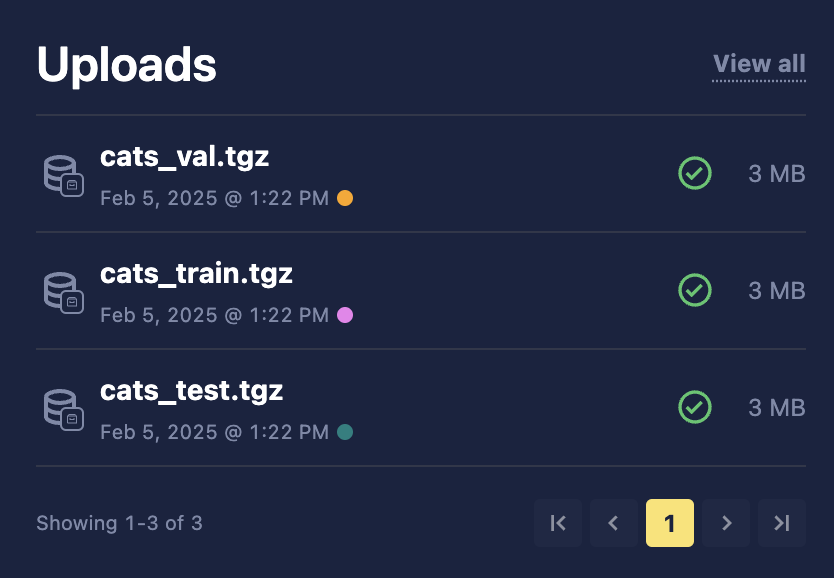
If you want to upload data into a specific split—to specify immediately if your data is going to be used for training, testing, or validation purposes—click the Upload as train/test/val split checkbox before uploading your data file(s). This will assign that data to a specific default split that will be used when creating a View of that dataset later on. When selecting this option, the data assigned to each split will be locked to that split type unless explicitly ignored when creating a View. Each split will then be processed as an individual upload as shown below. See the Views section for more information.
In this example, we use the upload_folder_and_wait function and upload the contents of a directory, including all subdirectories, and wait for Chariot to finish processing all the data. If we wish to continue after the upload is complete and do not want to wait for Chariot to finish processing the uploads, we can use the upload_folder function instead.
We are specifying the Train split to upload the data to. This is optional: When no split is provided, the data will be evenly distributed across splits when a Snapshot is created, according to the View being applied.
from chariot.client import connect
from chariot.datasets import create_dataset, upload_folder_and_wait, DatasetType, SplitName
connect()
# Create empty dataset
dataset = create_dataset(
name="desired name of dataset",
project_id="project_id of project to create dataset",
description="a description of the dataset",
type=DatasetType.IMAGE
)
# Upload images and annotations
upload_folder_and_wait(dataset_id=dataset.id, path="path to directory", split=SplitName.TRAIN)
You can also upload individual files or compressed archives with the upload_file or upload_file_from_url methods.
If you have code that is creating images and or annotations, the upload_bytes method will allow you to upload your data without first writing it to a file.
Large image files (>1GB) uploaded into Chariot may not populate EXIF metadata. Consider chipping your image data prior to uploading it. For additional information, please contact support@striveworks.com or your Striveworks administrator.
Fatal Upload Validation Error
If an upload returns a fatal validation error, there could be various reasons:
- Invalid or unsupported archive type (see compressed file formats for supported file types)
- Truncated or corrupted archive
- Multiple annotations files
- Multiple metadata files
- Annotations or metadata file syntax error
- Ignore file is too large (
.chariotignoreis more than 2 megabytes)
Please check the contents of your upload archive to ensure that it conforms to expectations.
Ignore File
Archive upload contents may be ignored by providing a .chariotignore file at the root of archive. This allows upload archives to contain additional information that is not intended for Chariot. The .chariotignore file uses the same syntax as Git's ignore file. See https://git-scm.com/docs/gitignore for more information.
Example Ignore File
# ignore files foo and bar
foo
bar
# ignore any hidden files
.*
# ignore any json files other than annotations and metadata
*.json
!annotations.json
!metadata.json
# ignore contents of the test directory
test/